This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, companies are discovering that performing full fine tuning for these models with their data isnt cost effective. To reduce costs while continuing to use the power of AI , many companies have shifted to fine tuning LLMs on their domain-specific data using Parameter-Efficient Fine Tuning (PEFT).
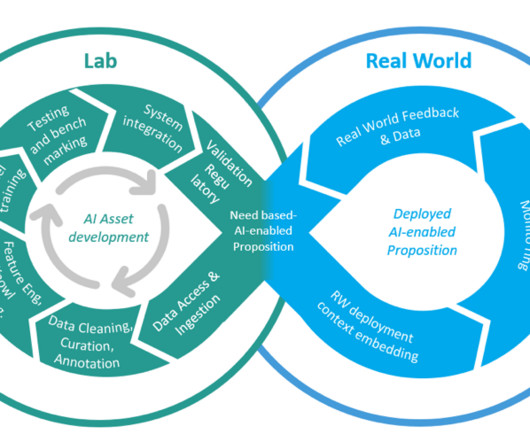
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
AIs transformative impact extends throughout the modern business landscape, with telecommunications emerging as a key area of innovation. Fastweb , one of Italys leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. We’ll cover Amazon Bedrock Agents , capable of running complex tasks using your company’s systems and data.
In today’s world, data is exploding at an unprecedented rate, and the challenge is making sense of it all. Generative AI (GenAI) is stepping in to change the game by making data analytics accessible to everyone. How is Generative AI Different from Traditional AI Models?
In recent years, there has been a growing interest in the use of artificial intelligence (AI) for data analysis. AI tools can automate many of the tasks involved in data analysis, and they can also help businesses to discover new insights from their data.
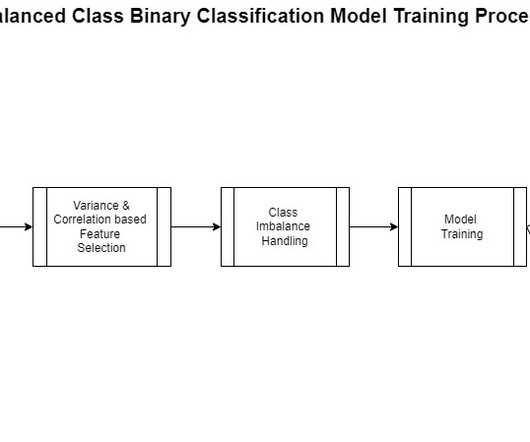
You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. These features can find temporal patterns in the data that can influence the baseFare.
Use case governance is essential to help ensure that AI systems are developed and used in ways that respect values, rights, and regulations. According to the EU AI Act, use case governance refers to the process of overseeing and managing the development, deployment, and use of AI systems in specific contexts or applications.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. From deriving insights to powering generative artificial intelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability.
Key disciplines involved in data science Understanding the core disciplines within data science provides a comprehensive perspective on the field’s multifaceted nature. Overview of core disciplines Data science encompasses several key disciplines including data engineering, datapreparation, and predictive analytics.
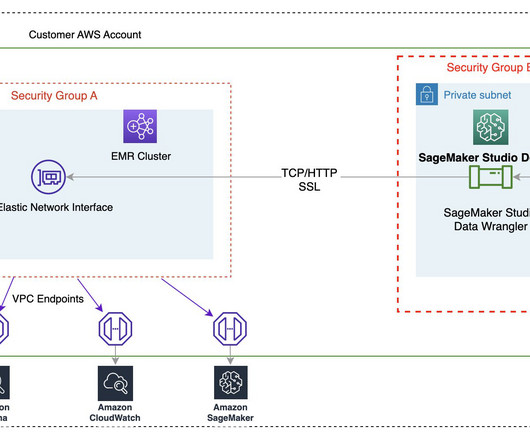
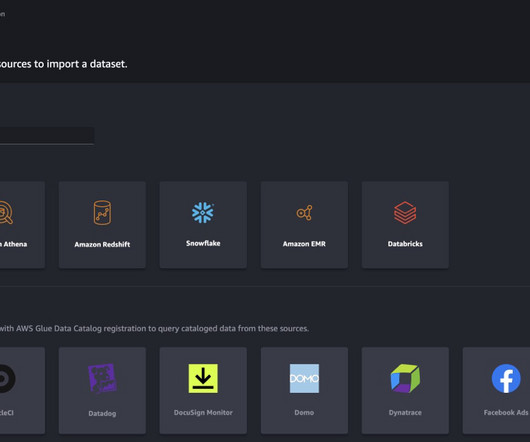
Data scientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. compute.internal.
Analyze the obtained sample data. Cluster Sampling Definition and applications Cluster sampling involves dividing a population into clusters or groups and selecting entire clusters at random for inclusion in the sample. Select clusters randomly from the population. Analyze the obtained sample data.
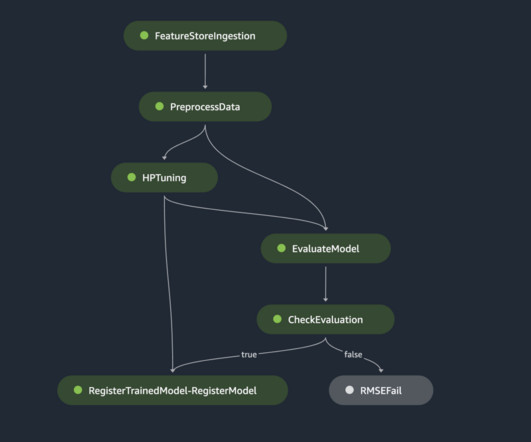
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. Unlike persistent endpoints, clusters are decommissioned when a batch transform job is complete.
We believe generative AI has the potential over time to transform virtually every customer experience we know. Innovative startups like Perplexity AI are going all in on AWS for generative AI. And at the top layer, we’ve been investing in game-changing applications in key areas like generative AI-based coding.
One of the key drivers of Philips’ innovation strategy is artificial intelligence (AI), which enables the creation of smart and personalized products and services that can improve health outcomes, enhance customer experience, and optimize operational efficiency.
In the rapidly evolving landscape of AI, generative models have emerged as a transformative technology, empowering users to explore new frontiers of creativity and problem-solving. By fine-tuning a generative AI model like Meta Llama 3.2 For a detailed walkthrough on fine-tuning the Meta Llama 3.2 Meta Llama 3.2 All Meta Llama 3.2
Author(s): Towards AI Editorial Team Originally published on Towards AI. What happened this week in AI by Louie This was another huge week for foundation LLMs, with the release of GPT-4o mini, the leak of LLama 3.1 Publishers are updating robots.txt and changing terms of service to prevent AI scraping.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. Moreover, they require a pre-determined number of topics, which was hard to determine in our data set. The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
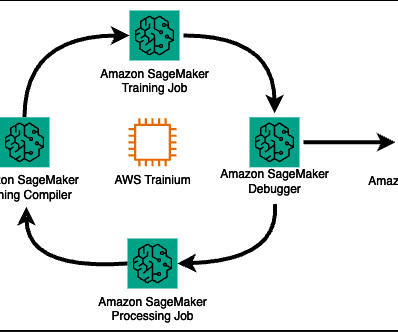
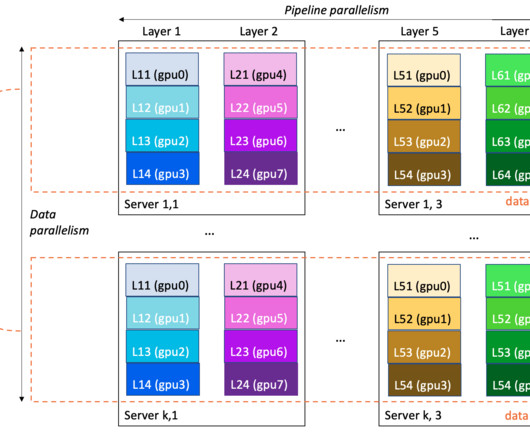
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
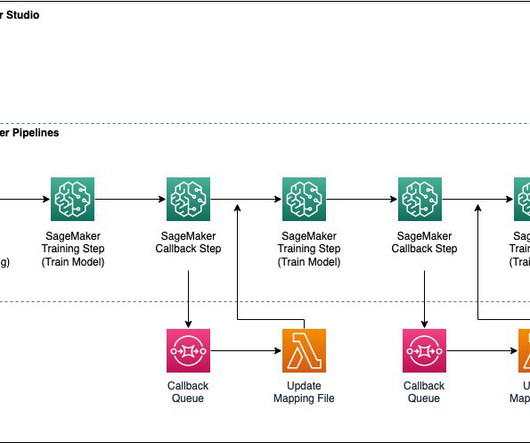
Ray AI Runtime (AIR) reduces friction of going from development to production. With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. In the processing job API, provide this path to the parameter of submit_jars to the node of the Spark cluster that the processing job creates. We attached the IAM role to the Redshift cluster that we created earlier.
“Instead of focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic. This can be a tedious task involving data collection, discovery, profiling, cleansing, structuring, transforming, enriching, validating, and securely storing the data.
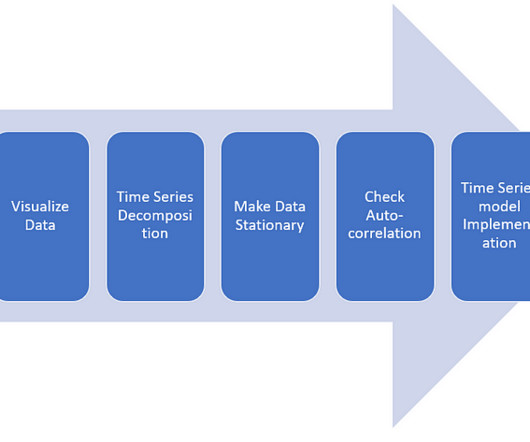
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. DataPreparation — Collect data, Understand features 2. Visualize Data — Rolling mean/ Standard Deviation— helps in understanding short-term trends in data and outliers.
In the rapidly expanding field of artificial intelligence (AI), machine learning tools play an instrumental role. Already a multi-billion-dollar industry, AI is having a profound impact on every aspect of life, business, and society. These tools are becoming increasingly sophisticated, enabling the development of advanced applications.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing data quality.
Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development. Python is renowned for its simplicity and versatility, making it an ideal choice for AI applications.
This growth can be seen in more accurate models and even opening new possibilities with generative AI: large language models (LLMs) that synthesize natural language, text-to-image generators, and more. Finally, launching clusters can introduce operational overhead due to longer starting time.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Further expanding the capabilities of AI in marketing, Zeta Global has developed AI Lookalikes.
This entails breaking down the large raw satellite imagery into equally-sized 256256 pixel chips (the size that the mode expects) and normalizing pixel values, among other datapreparation steps required by the GeoFM that you choose. This routine can be conducted at scale using an Amazon SageMaker AI processing job.
Summary: Data Science and AI are transforming the future by enabling smarter decision-making, automating processes, and uncovering valuable insights from vast datasets. Introduction Data Science and Artificial Intelligence (AI) are at the forefront of technological innovation, fundamentally transforming industries and everyday life.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. This can cause limitations if you need to consider more metrics than this.
We all know the management of Machine Learning systems can be complex: it typically involves the operation of servers, containers, and Kubernetes clusters, which requires prolonged processes and expertise in systems management. For example, services like S3, API Gateway, and Kinesis can trigger processes as soon as new data is detected.
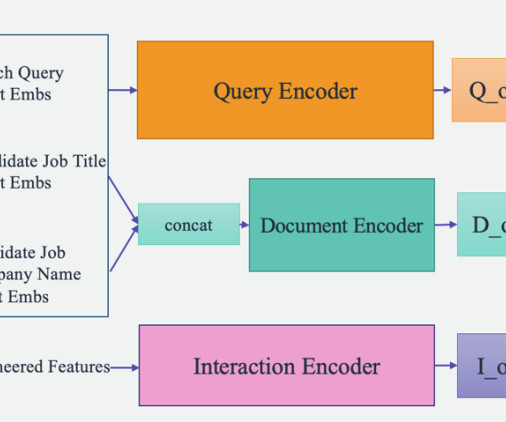
Feature engineering We perform two sets of feature engineering processes to extract valuable information from the raw data and feed it into the corresponding towers in the model: standard feature engineering and fine-tuned SBERT embeddings. Standard feature engineering Our datapreparation process begins with standard feature engineering.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificial intelligence (AI), are simply not practically possible, without hardware acceleration.
The Data Scientist’s responsibility is to move the data to a data lake or warehouse for the different data mining processes. DataPreparation: the stage prepares the data collected and gathered for preparation for data mining. are the various data mining tools.
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. Data is split into a training dataset and a testing dataset. Details of the datapreparation code are in the following notebook.
The eight speakers at the event—the second in our Enterprise LLM series—united around one theme: AIdata development drives enterprise AI success. Generic large language models (LLMs) are becoming the new baseline for modern enterprise AI. Slides for this session. Slides for this session.
To learn more about SageMaker Studio JupyterLab Spaces, refer to Boost productivity on Amazon SageMaker Studio: Introducing JupyterLab Spaces and generative AI tools. Data source access credentials – This SageMaker Studio notebook feature requires user name and password access to data sources such as Snowflake and Amazon Redshift.
Here are the steps involved in predictive analytics: Collect Data : Gather information from various sources like customer behavior, sales, or market trends. Clean and Organise Data : Prepare the data by removing errors and making it ready for analysis. Test the Model : Ensure that the model is accurate and works well.
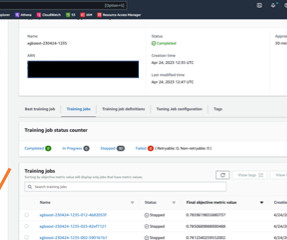
Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data. e-]*)"} ] Finally, define a Pytorch estimator and submit a training job that refers to the data location obtained from the HealthOmics sequence store.
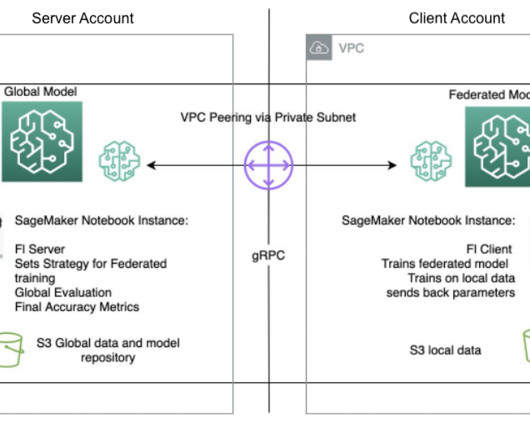
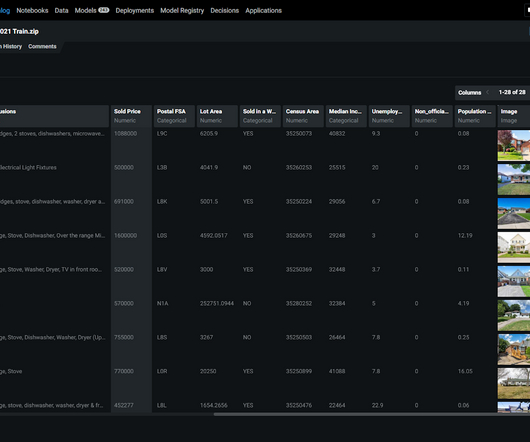
Enterprises see the most success when AI projects involve cross-functional teams. For true impact, AI projects should involve data scientists, plus line of business owners and IT teams. Quite a few complex use cases, such as price forecasting, might require blending tabular data, images, location data, and unstructured text.
LLMs are the foundation of gen AI applications. In the end, youll have the tools to make the necessary choices for building your gen AI application foundation. The AI landscape is moving towards a multi-agent architecture with LLM agents , meaning each model works on a clear and simple task.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content