This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last Updated on October 31, 2024 by Editorial Team Author(s): Jonas Dieckmann Originally published on Towards AI. Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities.
Key Takeaways: Data integrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Dataquality and data governance are the top data integrity challenges, and priorities. AI drives the demand for data integrity.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
Key Takeaways: Data integrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Dataquality and data governance are the top data integrity challenges, and priorities. AI drives the demand for data integrity.
Sponsored Post Generative AI is a significant part of the technology landscape. The effectiveness of generative AI is linked to the data it uses. Similar to how a chef needs fresh ingredients to prepare a meal, generative AI needs well-prepared, cleandata to produce outputs.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Summary: The article explores the differences between data driven and AI driven practices. Data-driven and AI-driven approaches have become key in how businesses address challenges, seize opportunities, and shape their strategic directions.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
Author(s): Richie Bachala Originally published on Towards AI. Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Artificial Intelligence (AI) is revolutionizing various industries, and IT support is no exception. The adoption of AI in IT support has led to significant improvements in efficiency, user experience, and issue resolution. This enables IT teams to anticipate potential problems and take proactive measures to prevent service disruptions.
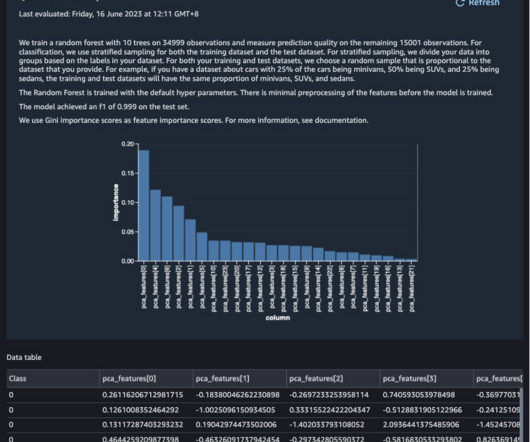
To quickly explore the loan data, choose Get data insights and select the loan_status target column and Classification problem type. The generated DataQuality and Insight report provides key statistics, visualizations, and feature importance analyses. About the authors Dr. Changsha Ma is an AI/ML Specialist at AWS.
The post The one constant in our AI future? Data appeared first on SAS Blogs. The innovations keep coming and so do the 3 a.m. night sweats for decision makers. How will we catch up when technology seems to change overnight, nearly every night?” It’s a surprisingly common [.]
Last Updated on August 26, 2023 by Editorial Team Author(s): Zijing Zhu Originally published on Towards AI. In today's business landscape, relying on accurate data is more important than ever. Join thousands of data leaders on the AI newsletter. Published via Towards AI Upgrade to access all of Medium.
We’ve infused our values into our platform, which supports data fabric designs with a data management layer right inside our platform, helping you break down silos and streamline support for the entire data and analytics life cycle. . Analytics data catalog. Dataquality and lineage. Data preparation.
We’ve infused our values into our platform, which supports data fabric designs with a data management layer right inside our platform, helping you break down silos and streamline support for the entire data and analytics life cycle. . Analytics data catalog. Dataquality and lineage. Data preparation.
Summary: AI is revolutionising procurement by automating processes, enhancing decision-making, and improving supplier relationships. Introduction Artificial Intelligence (AI) is revolutionising various sectors , and Acquisition is no exception. Around 96% use AI in the procurement process. What is AI in Procurement?
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
This article explores real-world cases where poor-qualitydata led to model failures, and what we can learn from these experiences. By the end, you’ll see why investing in qualitydata is not just a good idea, but a necessity. Why Does DataQuality Matter? The outcome? Sounds great, right?
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. By automating complex forecasting processes, AI significantly improves accuracy and efficiency in various applications. billion by 2030. What is Time Series Forecasting?
As AI becomes ubiquitous across dozens of industries, the initial hype of new technology is beginning to be replaced by the challenge of building trustworthy AI systems. We’ve all heard the headlines: Amazon’s AI hiring scandal, IBM Watson’s $62 million failure in oncology, the now-infamous COMPAS recidivism […].
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis. What is Data Manipulation? Data manipulation is crucial for several reasons.
Summary: This comprehensive guide explores data standardization, covering its key concepts, benefits, challenges, best practices, real-world applications, and future trends. By understanding the importance of consistent data formats, organizations can improve dataquality, enable collaborative research, and make more informed decisions.
Real-World Example: Healthcare systems manage a huge variety of data: structured patient demographics, semi-structured lab reports, and unstructured doctor’s notes, medical images (X-rays, MRIs), and even data from wearable health monitors. Ensuring dataquality and accuracy is a major challenge.
Data scrubbing is often used interchangeably but there’s a subtle difference. Cleaning is broader, improving dataquality. This is a more intensive technique within datacleaning, focusing on identifying and correcting errors. Data scrubbing is a powerful tool within this cleaning service.
Moreover, ignoring the problem statement may lead to wastage of time on irrelevant data. Overlooking DataQuality The quality of the data you are working on also plays a significant role. Dataquality is critical for successful data analysis.
This phase is crucial for enhancing dataquality and preparing it for analysis. Transformation involves various activities that help convert raw data into a format suitable for reporting and analytics. Normalisation: Standardising data formats and structures, ensuring consistency across various data sources.
We also reached some incredible milestones with Tableau Prep, our easy-to-use, visual, self-service data prep product. In 2020, we added the ability to write to external databases so you can use cleandata anywhere. Tableau Prep can now be used across more use cases and directly in the browser.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
Tools such as Python’s Pandas library, Apache Spark, or specialised datacleaning software streamline these processes, ensuring data integrity before further transformation. Step 3: Data Transformation Data transformation focuses on converting cleaneddata into a format suitable for analysis and storage.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. DataCleaningDatacleaning is crucial for data integrity.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. Data Lakes allow for flexible analysis.
Overcoming challenges like dataquality and bias improves accuracy, helping businesses and researchers make data-driven choices with confidence. Introduction Data Analysis and interpretation are key steps in understanding and making sense of data. Challenges like poor dataquality and bias can impact accuracy.
We are hearing about NLP, LLMs, ChatGPT and Generative AI a lot ! On December 5th, 2023, Dr Sonal Khosla took us on a journey from where it all began to the most recent Generative AI. Natural Language Processing (NLP) is a branch of Artificial Intelligence (AI) that helps computers understand, interpret and manipulate human language.
This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data. The different tools used in unstructured data management. What is Unstructured Data?
Data scientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data. The choice of approach depends on the impact of missing data on the overall dataset and the specific analysis or model being used.
However, despite being a lucrative career option, Data Scientists face several challenges occasionally. The following blog will discuss the familiar Data Science challenges professionals face daily. Furthermore, it ensures that data is consistent while effectively increasing the readability of the data’s algorithm.
AWS Glue is then used to clean and transform the raw data to the required format, then the modified and cleaneddata is stored in a separate S3 bucket. For those data transformations that are not possible via AWS Glue, you use AWS Lambda to modify and clean the raw data.
Accurate, cleandata and workflows prevent disruptions and downtime once the system goes live. Specifically, to ensure the accuracy of data, organizations should test the following variables: Data archive: Make sure older data that might not have been imported to Oracle is archived securely and is easy to access.
Duplicates can significantly affect Data Analysis and reporting in several ways: Inflated Metrics: Duplicates can lead to inflated totals or averages, which misrepresent the actual data. Skewed Insights: Analysis based on duplicated data can result in incorrect conclusions and impact decision-making.
He presented “Building Machine Learning Systems for the Era of Data-Centric AI” at Snorkel AI’s The Future of Data-Centric AI event in 2022. The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. You can then plug in different types of objectives.
He presented “Building Machine Learning Systems for the Era of Data-Centric AI” at Snorkel AI’s The Future of Data-Centric AI event in 2022. The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. You can then plug in different types of objectives.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content