This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last Updated on October 31, 2024 by Editorial Team Author(s): Jonas Dieckmann Originally published on Towards AI. Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
These data science teams are seeing tremendous results—millions of dollars saved, new customers acquired, and new innovations that create a competitive advantage. Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results. Read the blog. Read the blog.
It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AIData Cloud and Dataiku. Let’s say your company makes cars.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. By automating complex forecasting processes, AI significantly improves accuracy and efficiency in various applications. billion by 2030. What is Time Series Forecasting?
This crucial step involves handling missing values, correcting errors (addressing Veracity issues from Big Data), transforming data into a usable format, and structuring it for analysis. This often takes up a significant chunk of a data scientist’s time. Think graphs, charts, and summary statistics.
This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data. The different tools used in unstructured data management. What is Unstructured Data?
Clear Formatting Remove any inconsistent formatting that may interfere with data processing, such as extra spaces or incomplete sentences. Validate Data Perform a final quality check to ensure the cleaneddata meets the required standards and that the results from data processing appear logical and consistent.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaningPipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaningPipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction. Data engineers can prepare the data by removing duplicates, dealing with outliers, standardizing data types and precision between data sets, and joining data sets together.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaningPipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
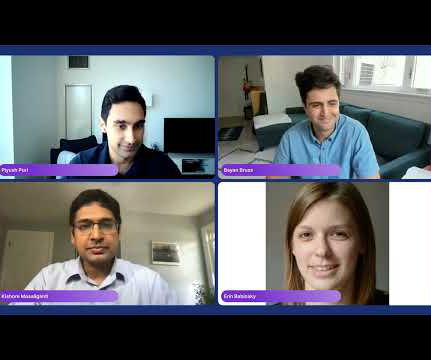
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Data quality is crucial across various domains within an organization. For example, software engineers focus on operational accuracy and efficiency, while data scientists require cleandata for training machine learning models. Without high-quality data, even the most advanced models can't deliver value.
Data Ingestion Tools To facilitate the process, various tools and technologies are available. These tools can automate data collection, transformation, and loading processes, making it easier for organisations to manage their datapipelines effectively. Data Lakes allow for flexible analysis.
Snowpark Use Cases Data Science Streamlining data preparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow data scientists to use familiar tools for wrangling and cleaningdata directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.
This year, there are more than 900 academic programs offering training in data science. LinkedIn’s 2020 Emerging Job Report lists Data Scientist at #3 with 37% annual growth. The job AI Specialist, which is closely related, is listed at #1 with 74% annual growth. New roles and opportunities in data are multiplying!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content