This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
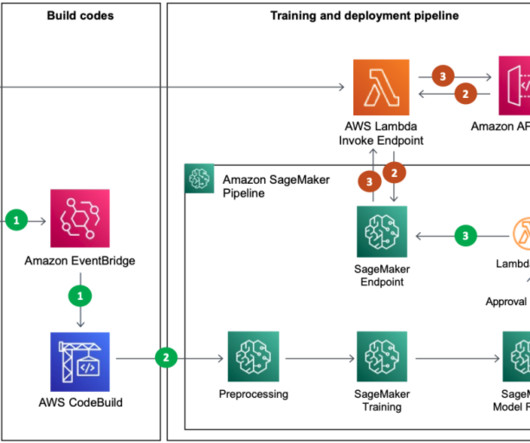
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Best Big Data Tools Popular tools such as ApacheHadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Use Cases : Yahoo!
From healthcare where AI assists in diagnosis and treatment plans, to finance where it is used to predict market trends and manage risks, the influence of AI is pervasive and growing. As AI technologies evolve, they create new job roles and demand new skills, particularly in the field of AI engineering.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is ApacheHadoop?
Last Updated on September 29, 2023 by Editorial Team Author(s): Mihir Gandhi Originally published on Towards AI. It leverages ApacheHadoop for both storage and processing. Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI.
Summary: The article explores the differences between data driven and AI driven practices. Data-driven and AI-driven approaches have become key in how businesses address challenges, seize opportunities, and shape their strategic directions.
Platforms and tools Organizations often rely on advanced tools such as ApacheHadoop and Apache Spark to streamline data handling. Innovations on the horizon Anticipated advancements include: AI and machine learning: These technologies are expected to further improve data analysis capabilities.
Artificial intelligence (AI) is revolutionizing industries by enabling advanced analytics, automation and personalized experiences. Enterprises have reported a 30% productivity gain in application modernization after implementing Gen AI. This flexibility ensures optimal performance without over-provisioning or underutilization.
Summary: Business Analytics focuses on interpreting historical data for strategic decisions, while Data Science emphasizes predictive modeling and AI. Big data platforms such as ApacheHadoop and Spark help handle massive datasets efficiently. Retail uses AI solutions for personalized recommendations and inventory optimization.
This section will highlight key tools such as ApacheHadoop, Spark, and various NoSQL databases that facilitate efficient Big Data management. ApacheHadoopHadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability. Data lakes and cloud storage provide scalable solutions for large datasets.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability. Data lakes and cloud storage provide scalable solutions for large datasets.
Check out this course to build your skillset in Seaborn — [link] Big Data Technologies Familiarity with big data technologies like ApacheHadoop, Apache Spark, or distributed computing frameworks is becoming increasingly important as the volume and complexity of data continue to grow.
Among these tools, ApacheHadoop, Apache Spark, and Apache Kafka stand out for their unique capabilities and widespread usage. ApacheHadoopHadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
Hadoop: The Definitive Guide by Tom White This comprehensive guide delves into the ApacheHadoop ecosystem, covering HDFS, MapReduce, and big data processing. The post 10 Best Data Engineering Books [Beginners to Advanced] appeared first on Pickl AI.
With Amazon EMR, which provides fully managed environments like ApacheHadoop and Spark, we were able to process data faster. Gonsoo Moon is an AWS AI/ML Specialist Solutions Architect and provides AI/ML technical support.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. ETL Tools: Apache NiFi, Talend, etc.
This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to leverage Generative AI to manage unstructured data Benefits of applying proper unstructured data management processes to your AI/ML project.
With its powerful ecosystem and libraries like ApacheHadoop and Apache Spark, Java provides the tools necessary for distributed computing and parallel processing. Java’s scalability, performance, and compatibility with frameworks like ApacheHadoop and Apache Spark make it a favorable choice for big data analytics.
This layer includes tools and frameworks for data processing, such as ApacheHadoop, Apache Spark, and data integration tools. Platform as a Service (PaaS) PaaS offerings provide a development environment for building, testing, and deploying Big Data applications.
One popular example of the MapReduce pattern is ApacheHadoop, an open-source software framework used for distributed storage and processing of big data. Hadoop provides a MapReduce implementation that allows developers to write applications that process large amounts of data in parallel across a cluster of commodity hardware.
Adopting AI-enabled Data Science technologies will help automate manual data cleaning and ensure that Data Scientists become more productive. Some of the tools used by Data Science in 2023 include statistical analysis system (SAS), Apache, Hadoop, and Tableau.
Furthermore, data warehouse storage cannot support workloads like Artificial Intelligence (AI) or Machine Learning (ML), which require huge amounts of data for model training. For example, a bank may get rid of its decade old datawarehouse and deliver all BI and AI use cases from a single data platform, by implementing a lakehouse.
Integration with Big Data Ecosystems NiFi integrates seamlessly with Big Data technologies such as ApacheHadoop, Apache Kafka, and Apache Spark. This integration allows organizations to build robust data pipelines that leverage the strengths of each technology for data processing and analytics.
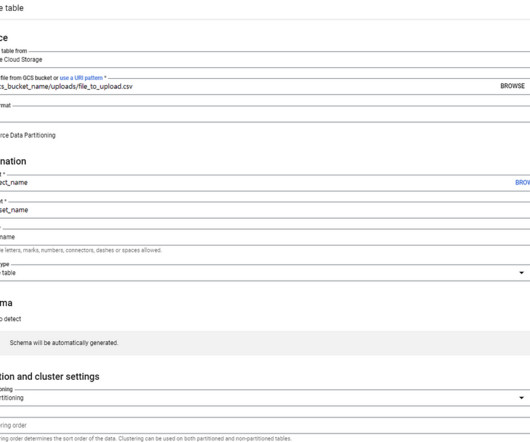
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and ApacheHadoop. Some of the other ways are creating a table 1) using the command line in Google Cloud console, 2) using the APIs, or 3) from Vertex AI Workbench.
Apache Nutch A powerful web crawler built on ApacheHadoop, suitable for large-scale data crawling projects. Nutch is often used in conjunction with other Hadoop tools for big data processing. Scrapy is known for its speed and efficiency, making it a popular choice among developers.
Packages like dplyr, data.table, and sparklyr enable efficient data processing on big data platforms such as ApacheHadoop and Apache Spark. The post Introduction to R Programming For Data Science appeared first on Pickl AI. You can easily learn R for Data Science through the available online courses in Pickl.AI
Big Data Technologies: As the amount of data grows, familiarity with big data technologies such as ApacheHadoop, Apache Spark, and distributed computer platforms might be useful. The post Best Resources for Kids to learn Data Science with Python appeared first on Pickl AI.
Programming languages like Python or R should be mastered by students or professionals working on these projects, as should big data tools like ApacheHadoop, Apache Spark, or cloud-based data analytics platforms. The post Top 15 Data Analytics Projects in 2023 for beginners to Experienced appeared first on Pickl AI.
In der Parallelwelt der ITler wurde das Tool und Ökosystem ApacheHadoop quasi mit Big Data beinahe synonym gesetzt. Artificial Intelligence (AI) ersetzt. AI wiederum scheint spätestens mit ChatGPT 2022/2023 eine neue Euphorie-Phase erreicht zu haben, mit noch ungewissem Ausgang. Industrie 4.0). Process Mining).
Applications of DFS in Artificial Intelligence Distributed File Systems (DFS) play a significant role in enhancing the capabilities of Artificial Intelligence (AI) applications. Here are some key applications: Data Management and Storage AI models require vast amounts of data for training and inference.
WRITER at MLearning.ai / 800+ AI plugins / AI Searching 2024 Mlearning.ai Get in touch with us to discuss your needs and wants and bring your ideas to life. Originally published at [link] on August 3, 2023. on Medium, where people are continuing the conversation by highlighting and responding to this story.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content