

Big data management
Dataconomy
MAY 26, 2025
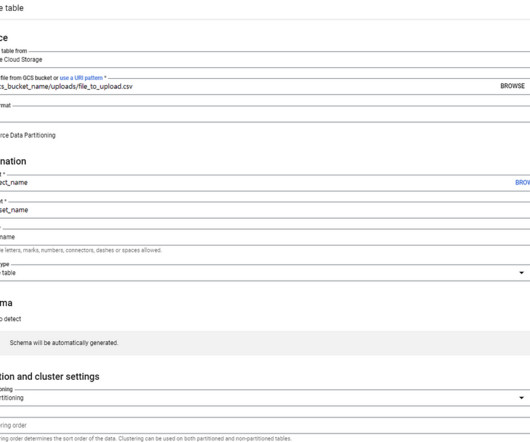
Platforms and tools Organizations often rely on advanced tools such as Apache Hadoop and Apache Spark to streamline data handling. Leveraging advanced technologies Utilizing machine learning and AI can significantly enhance data analytics capabilities, providing deeper insights.













Let's personalize your content