

Enterprise-grade natural language to SQL generation using LLMs: Balancing accuracy, latency, and scale
APRIL 24, 2025
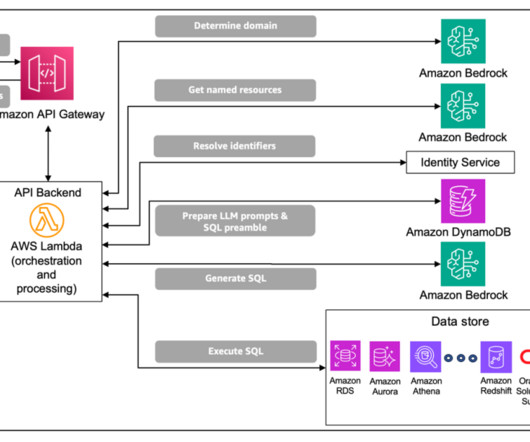
Data across these domains is often maintained across disparate data environments (such as Amazon Aurora , Oracle, and Teradata), with each managing hundreds or perhaps thousands of tables to represent and persist business data. As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.









Let's personalize your content