This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last Updated on October 5, 2024 by Editorial Team Author(s): Harsh Chourasia Originally published on Towards AI. The Ultimate Guide to Making Smarter DataDecisions This member-only story is on us. Photo by Nicole Wolf on Unsplash Today we will talk about DecisionTrees, a powerful tool in machine learning and datascience.
Can datascience techniques protect individuals’ identities? Since there was a massive data breach in 2024 that compromised 2.9 How Can DataScience Combat Synthetic Identity Fraud? Almost everything a person does generates an enormous amount of data. What Is Synthetic Identity Fraud?
Last Updated on December 18, 2024 by Editorial Team Author(s): Mukundan Sankar Originally published on Towards AI. You're not ready for neural networks if you cant explain Linear Regression or DecisionTrees. Stop Overthinking and Start Building Models with Real-World Datasets This member-only story is on us.
Last Updated on December 19, 2024 by Editorial Team Author(s): Mukundan Sankar Originally published on Towards AI. You're not ready for neural networks if you cant explain Linear Regression or DecisionTrees. Stop Overthinking and Start Building Models with Real-World Datasets This member-only story is on us.
Industry Adoption: Widespread Implementation: AI and datascience are being adopted across various industries, including healthcare, finance, retail, and manufacturing, driving increased demand for skilled professionals. Python Explain the steps involved in training a decisiontree.
Theres a reason why the best datascience teams at top-tier companies still rely on logistic regression, XGBoost, and decisiontrees. AI generated Image from Napkin AI The Data Most Businesses Care About Lets face it: much of the worlds data isnt text, image, or video.
Even though artificial intelligence relies on human-generated data, its reasoning has become too complex for people to understand, leading to what’s called the black box problem. In other words, the average person can’t grasp the datascience techniques professionals use to improve transparency. Is there another way?
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. The challenge demonstrated the intersection of sports and datascience by combining real-world datasets with predictive modeling.
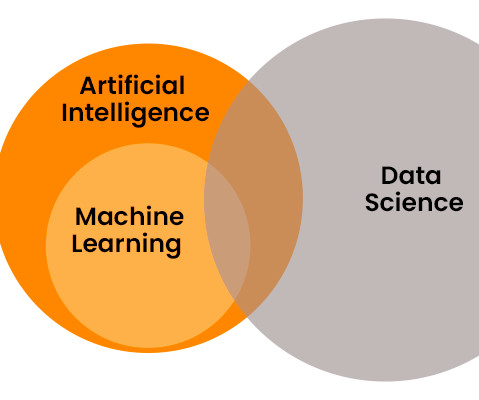
Summary: In the tech landscape of 2024, the distinctions between DataScience and Machine Learning are pivotal. DataScience extracts insights, while Machine Learning focuses on self-learning algorithms. The collective strength of both forms the groundwork for AI and DataScience, propelling innovation.
Last Updated on September 30, 2024 by Editorial Team Author(s): Souradip Pal Originally published on Towards AI. Unlike other algorithms, which rely on a single model to make predictions, Gradient Boosting uses a series of weak models (often decisiontrees), each learning from the mistakes of the one before it.
Last Updated on October 5, 2024 by Editorial Team Author(s): Souradip Pal Originally published on Towards AI. Join thousands of data leaders on the AI newsletter. This member-only story is on us. Upgrade to access all of Medium. Imagine you’re trying to guess how many jelly beans are in a jar.
Last Updated on December 18, 2024 by Editorial Team Author(s): Mukundan Sankar Originally published on Towards AI. You're not ready for neural networks if you cant explain Linear Regression or DecisionTrees. Stop Overthinking and Start Building Models with Real-World Datasets This member-only story is on us.
Last Updated on May 1, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. We shall look at various types of machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code.
Last Updated on March 29, 2024 by Editorial Team Author(s): Boris Meinardus Originally published on Towards AI. Back when I started learning ML, some of my professors would simply throw a formula on the screen and tell us “This is the loss function for a decisiontree” and that was it. It can be very hard!
ODSC West is right around the corner, promising an impressive lineup of industry leaders who will cover cutting-edge developments in AI, machine learning, and datascience. Whether you are scaling your models or looking for ways to enhance predictive accuracy, this session will offer valuable guidance for datascience professionals.
Last Updated on February 7, 2024 by Editorial Team Author(s): Kamireddy Mahendra Originally published on Towards AI. Context & Problem Statement from the Kaggle website: Welcome to the year 2912, where your datascience skills are needed to solve a cosmic mystery. Click Here to see the project details.
Top Python Libraries of 2023 and 2024 NumPy NumPy is the gold standard for scientific computing in Python and is always considered amongst top Python libraries. What makes it popular is that it is used in a wide variety of fields, including datascience, machine learning, and computational physics. Not a bad list right?
Last Updated on March 18, 2024 by Editorial Team Author(s): Joseph George Lewis Originally published on Towards AI. With applications in all the same places as plain old AI, XAI has a tangible role in promoting trust and transparency and enhancing user experience in datascience and artificial intelligence.
Results of the Hindcast Stage ¶ The Water Supply Forecast Rodeo is being held over multiple stages from October 2023 through July 2024. In the Hindcast Stage —the first stage of the challenge—participants developed forecast models that were evaluated against 10 years of held out historical data. Image courtesy of USBR.
From deterministic software to AI Earlier examples of “thinking machines” included cybernetics (feedback loops like autopilots) and expert systems (decisiontrees for doctors). Whatever the case, by 2024, humans are the input on which things are trained, and provide the feedback on output quality that is used to improve it.
His predictive models showed an impressive accuracy rate, with the DecisionTree Classifier achieving a classification accuracy of 98% and a recall rate of 97%, highlighting its effectiveness in identifying potentially successful startups based on early-stage data inputs.
Last Updated on February 20, 2024 by Editorial Team Author(s): Vaishnavi Seetharama Originally published on Towards AI. Linear Regression DecisionTrees Support Vector Machines Neural Networks Clustering Algorithms (e.g., You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
Solvers first developed their solutions on historical data in the Hindcast Stage, which concluded in spring 2024. This blog post presents the winners of all remaining stages: Forecast Stage where models made near-real-time forecasts for the 2024 forecast season. Previously worked in various tech companies in Indonesia.
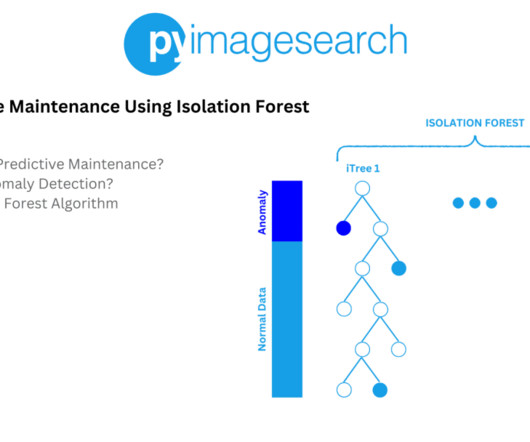
Figure 3: Isolation Forest isolates anomalies by randomly selecting a feature and splitting the data (source: DataScience Demystified ). Figure 4: Isolation Tree is a binary tree structure built by recursively partitioning the data (source: DataScience Demystified ). What's next? Raha, and P.
DecisionTrees and Random Forests are scale-invariant. 2019) DataScience with Python. WRITER at MLearning.ai / 800+ AI plugins / AI Searching 2024 Mlearning.ai Feature scaling ensures that each feature has an effect on a model’s prediction. For most algorithms, feature scaling is an important pre-processing step.
billion in 2024, at a CAGR of 10.7%. R and Other Languages While Python dominates, R is also an important tool, especially for statistical modelling and data visualisation. DecisionTrees These trees split data into branches based on feature values, providing clear decision rules.
AssemblyAI's Summarization Model Results: Bias and Variance Explained Bias and variants are two of the most important topics when it comes to datascience. Fitting variants show us the sensitivity of the model on the training data. This video is brought to you by AssemblyAI and is part of our Deep Learning Explained series.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content