This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
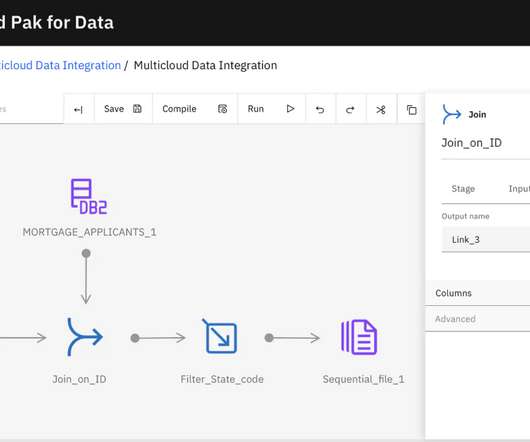
Next Generation DataStage on Cloud Pak for Data Ensuring high-qualitydata A crucial aspect of downstream consumption is dataquality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics.
At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets. This approach not only enhances the efficiency of datapreparation but also improves the accuracy and relevance of AI models.
Ensuring high-qualitydata A crucial aspect of downstream consumption is dataquality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis.
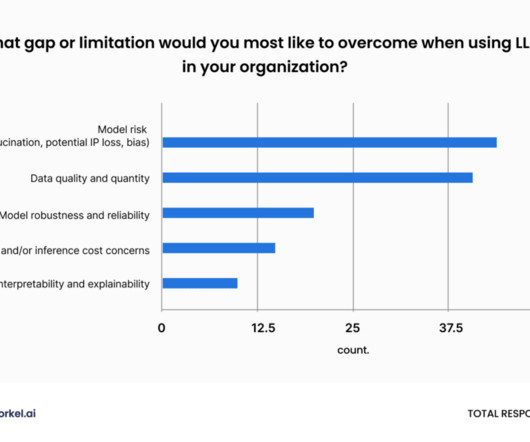
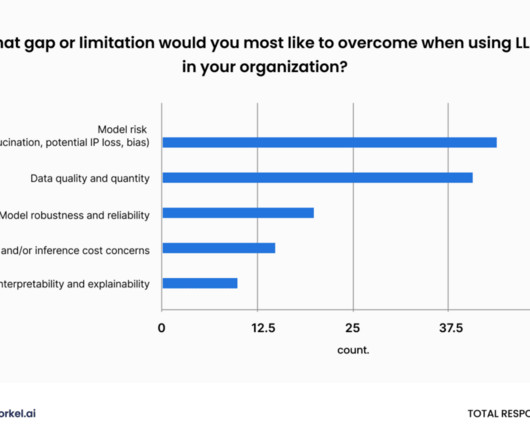
LLM distillation will become a much more common and important practice for data science teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As data science teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
LLM distillation will become a much more common and important practice for data science teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As data science teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
Last Updated on December 20, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. Datapreparation using Roboflow, model loading and configuration PaliGemma2 (including optional LoRA/QLoRA), and data loader creation are explained.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log dataPreparing your data to provide quality results is the first step in an AI project.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. This process involves extracting data from multiple sources, transforming it into a consistent format, and loading it into the data warehouse. ETL is vital for ensuring dataquality and integrity. from 2025 to 2030.
Last Updated on June 25, 2024 by Editorial Team Author(s): Mena Wang, PhD Originally published on Towards AI. Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. This practice vastly enhances the speed of my datapreparation for machine learning projects.
Data Management – Efficient data management is crucial for AI/ML platforms. Regulations in the healthcare industry call for especially rigorous data governance. It should include features like data versioning, data lineage, data governance, and dataquality assurance to ensure accurate and reliable results.
It is projected to grow at a CAGR of 34.20% in the forecast period (2024-2031). Common Challenges in DataPreparation One of the most common challenges when preparing UCI datasets is dealing with missing data. The global Machine Learning market continues to expand. It was valued at USD 35.80 billion by 2031.
billion in 2024, at a CAGR of 10.7%. R and Other Languages While Python dominates, R is also an important tool, especially for statistical modelling and data visualisation. Data Transformation Transforming dataprepares it for Machine Learning models. billion in 2023 to $181.15
The importance of dataquality The concept of “garbage in, garbage out” succinctly captures the importance of dataquality in machine learning. The performance and reliability of an algorithm directly correlate with the integrity and representativeness of its training data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content