This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters. Create a new training plan.
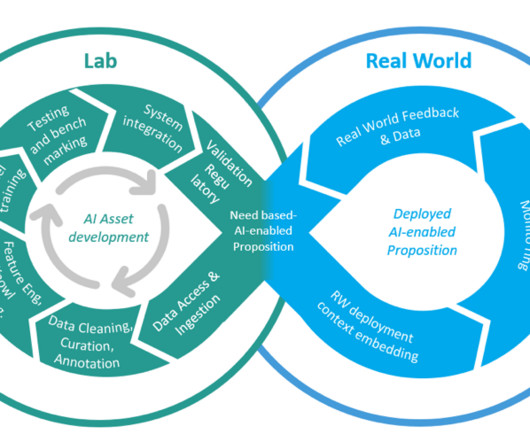
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. RELand consistently outperforms the benchmark models on all relevant metrics.
in 2024 , is a benchmark designed for evaluating reading comprehension on very long texts, often exceeding 200,000 tokens. 2024) , is a benchmark that evaluates long-context comprehension across multiple documents. Clustering : Aggregating and grouping relevant information from multiple sources based on specific criteria.
It gives these users a single, intuitive entry point to interact with data and AI—without needing to understand clusters, queries, models, or notebooks. Databricks One is a new product experience designed specifically for business users.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
Amazon SageMaker HyperPod recipes At re:Invent 2024, we announced the general availability of Amazon SageMaker HyperPod recipes. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. recipes=recipe-name.
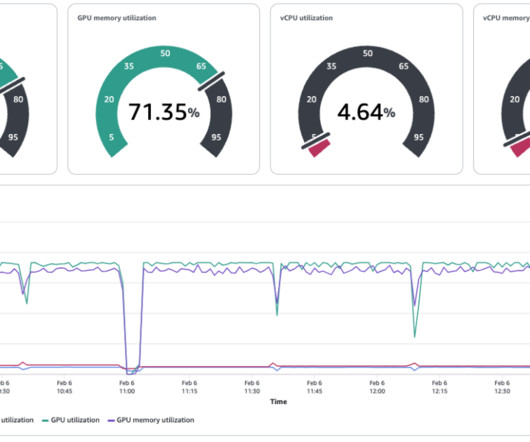
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. # install.sh
Last Updated on September 3, 2024 by Editorial Team Author(s): Surya Maddula Originally published on Towards AI. Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit.
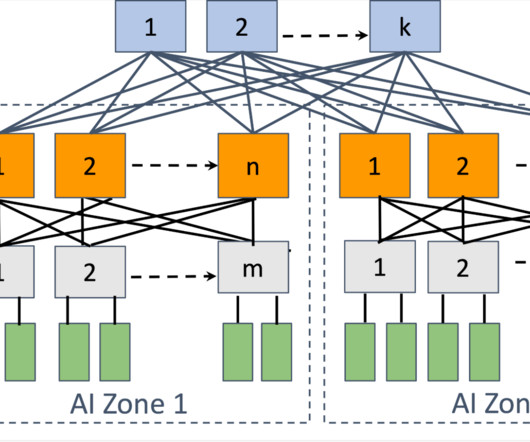
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
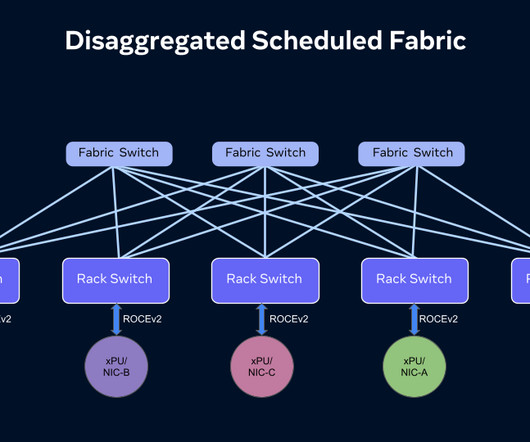
At Open Compute Project Summit (OCP) 2024, we’re sharing details about our next-generation network fabric for our AI training clusters. DSF: Scheduled fabric that is disaggregated and open Network performance and availability play an important role in extracting the best performance out of our AI training clusters.
In 2024, climate disasters caused more than $417B in damages globally, and theres no slowing down in 2025 with LA wildfires that destroyed more than $135B in the first month of the year alone. Their unifying mission is to create scalable solutions that accelerate the transition to a sustainable, low-carbon future.
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters. Builders can use built-in ML tools within SageMaker HyperPod to enhance model performance.
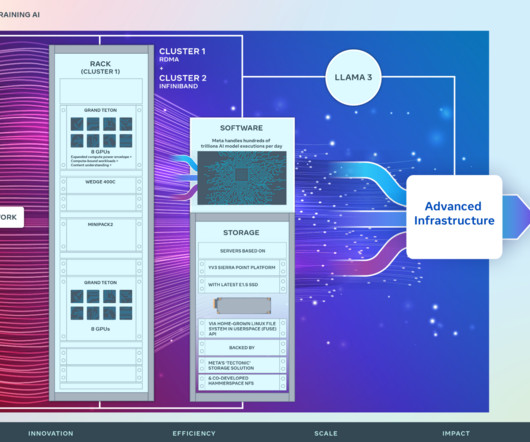
Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We use this cluster design for Llama 3 training. We built these clusters on top of Grand Teton , OpenRack , and PyTorch and continue to push open innovation across the industry. We are strongly committed to open compute and open source.
At the Open Compute Project (OCP) Global Summit 2024, we’re showcasing our latest open AI hardware designs with the OCP community. Over the course of 2023, we rapidly scaled up our training clusters from 1K, 2K, 4K, to eventually 16K GPUs to support our AI workloads. Today, we’re training our models on two 24K-GPU clusters.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. The implementation included a provisioned three-node sharded OpenSearch Service cluster. Dr. Hemant Joshi has over 20 years of industry experience building products and services with AI/ML technologies.
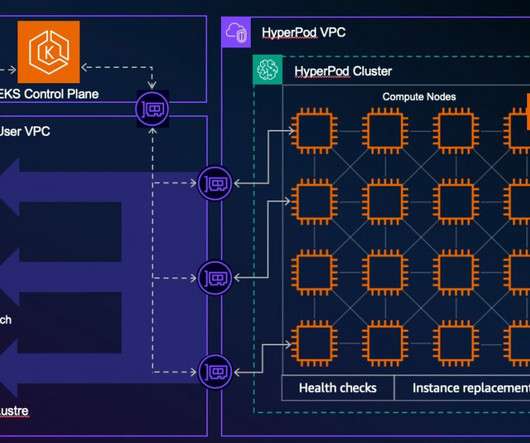
At AWS re:Invent 2024, we launched a new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that enables you to run generative AI development tasks on shared accelerated compute resources efficiently and reduce costs by up to 40%.
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
Last Updated on February 20, 2024 by Editorial Team Author(s): Vaishnavi Seetharama Originally published on Towards AI. Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms.
This capability allows for the seamless addition of SageMaker HyperPod managed compute to EKS clusters, using automated node and job resiliency features for foundation model (FM) development. FMs are typically trained on large-scale compute clusters with hundreds or thousands of accelerators.
This blog was originally written by Travis Hegner and updated for 2024 by Vinicius Olivera. Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. Sign up today for unbiased AI/ML advice!
This week at ACM SIGCOMM 2024 in Sydney, Australia, we are sharing details on the network we have built at Meta over the past few years to support our large-scale distributed AI training workload. When Meta introduced distributed GPU-based training , we decided to construct specialized data center networks tailored for these GPU clusters.
billion in 2024 to USD 36.1 The key here is to focus on concepts like supervised vs. unsupervised learning, regression, classification, clustering, and model evaluation. Hugging Face Tutorial (2024) - This comprehensive guide covers various NLP tasks, including building a sentiment analysis model with Hugging Face (Recommended).
Artificial intelligence has been adopted by over 72% of companies so far (McKinsey Survey 2024). Adding to the numbers, PwCs 2024 AI Jobs Barometer confirms that jobs requiring AI specialist skills have grown over 3 times faster than all other jobs. Indeed, Artificial intelligence is a way of life!
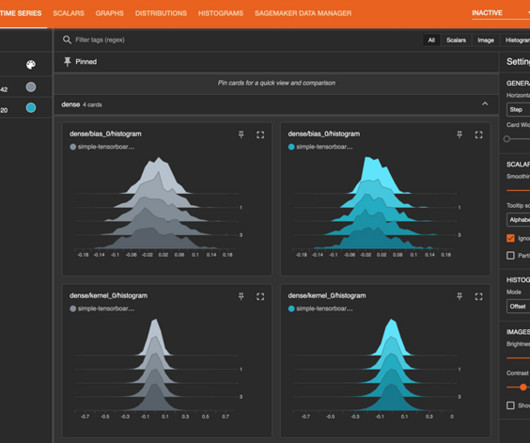
Swallow training Experiment management We discuss topics relevant to machine learning (ML) researchers and engineers with experience in distributed LLM training and familiarity with cloud infrastructure and AWS services. This post is organized as follows: Overview of Llama 3.3 Swallow Architecture for Llama 3.3 42,000 Swallow-Gemma-Magpie-v0.1
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Custom geospatial machine learning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machine learning (ML) tasks. Points clustered closely on the y-axis indicate similar ground conditions; sudden and persistent discontinuities in the embedding values signal significant change.
By early 2024, we are beginning to see the start of “Act 2,” in which many POCs are evolving into production, delivering significant business value. Because provisioning and managing the large GPU clusters needed for AI can pose a significant operational burden.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment. Adopted from [link] In this article, we will first briefly explain what ML workflows and pipelines are. around the world to streamline their data and ML pipelines.
dollars in 2024, a leap of nearly 50 billion compared to 2023. This rapid growth highlights the importance of learning AI in 2024, as the market is expected to exceed 826 billion U.S. Why AI is a Crucial Field in 2024 AI is rapidly transforming industries and the global economy. Deep Learning is a subset of ML.
In 2024, organizations are setting aside dedicated budgets for gen AI while ramping up their efforts to build accelerated infrastructure to support gen AI in production. MLRun is an open-source AI orchestration framework for managing ML and generative AI applications across their lifecycle. You can watch the entire webinar here.
Last Updated on February 1, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. If you are passionate about AI/ML and looking for a teammate to explore, contact them in the thread! Master clustering with this guide covering foundation and practical use.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, data preparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
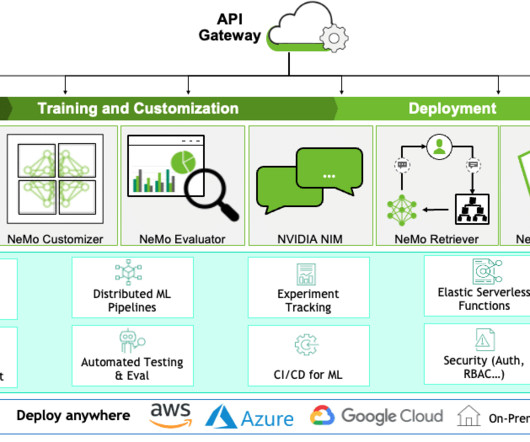
At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machine learning (ML) models. The serverless infrastructure of Amazon Bedrock manages the execution of ML models, resulting in a scalable and reliable application.
AWS innovates to offer the most advanced infrastructure for ML. For ML specifically, we started with AWS Inferentia, our purpose-built inference chip. We expect our first Trainium2 instances to be available to customers in 2024. Customers like Adobe, Deutsche Telekom, and Leonardo.ai
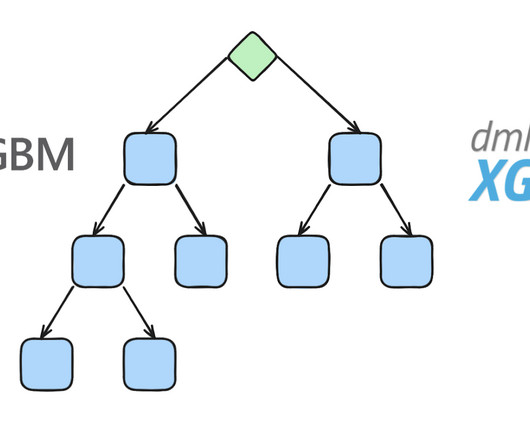
This ensures high quality and minimizes the chances of errors in implementing complex ML architectures. Some frameworks offer APIs compatible with leading approaches, such as LightGBM's scikit-learn API, allowing seamless integration into existing ML pipelines. XGBoost models are known for their impressive predictive performance.
Last Updated on April 4, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme.
Machine Learning (ML) is a subset of AI that focuses on developing algorithms and statistical models that enable systems to perform specific tasks effectively without being explicitly programmed. Clustering algorithms, such as K-Means and DBSCAN, are common examples of unsupervised learning techniques.
The Insights This comprehensive guide, updated for 2024, delves into the challenges and strategies associated with scaling Data Science careers. Embrace Distributed Processing Frameworks Frameworks like Apache Spark and Spark Streaming enable distributed processing of large datasets across clusters of machines.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. This versatility allows prompt engineers to adapt it to different projects and needs.
Last Updated on June 30, 2024 by Editorial Team Author(s): Shashank Bhushan Originally published on Towards AI. Training an Embedding Model Now that we know how to interpret embeddings let's see how we would go about training an ML model to generate embeddings. For our task, we will use simple binary classification.
Solution overview This post demonstrates the use of SageMaker Training for running torchtune recipes through task-specific training jobs on separate compute clusters. SageMaker Training is a comprehensive, fully managed ML service that enables scalable model training. The following diagram illustrates the solution architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content