This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. invoke_agent("What are the dates for reinvent 2024?", A: 'The AWS re:Invent conference was held from December 2-6 in 2024.' Query processing: a.
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. between 2024 and 2030. It fosters reliability.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
It is ideal for handling unstructured or semi-structured data, making it perfect for modern applications that require scalability and fast access. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles BigData. It integrates well with various data sources, making analysis easier.
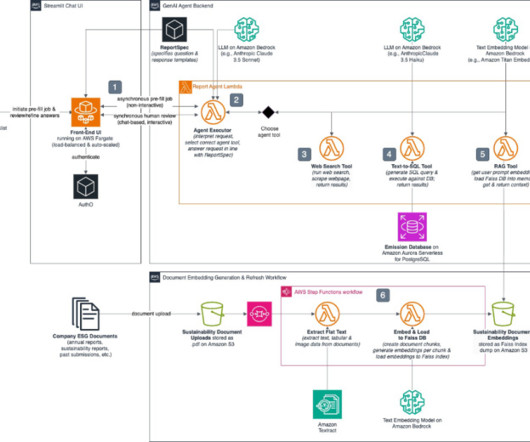
The tool uses natural language requests, such as “What were our Scope 2 emissions in 2024,” as input and returns the results from the emissions database. Using Report GenAI, OHI tracked their GHG inventory and relevant KPIs in real time and then prepared their 2024 CDP submission in just one week.
Last Updated on April 3, 2024 by Editorial Team Author(s): Harish Siva Subramanian Originally published on Towards AI. The ORC and Parquet are columnal storage and they are famous in the BigData world because of their efficient storage. Create a new Glue Crawler to discover and catalog your data in S3.
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
Dollar Unit Equivalencies: `1,234 million 1.234 billion` - Date Format Equivalencies: `2024-01-01 January 1st 2024` - Number Equivalencies: `1 one` - Start your response immediately with the question-answer-fact set JSON, and separate each extracted JSON record with a newline. See for examples.
Apache Spark™ has become the de facto engine for bigdata processing, powering workloads at some of the largest organizations in the world. This standard simplifies pipeline development across batch and streaming workloads.
In contrast, MongoDB uses a more straightforward query language that works well with JSON data structures. MongoDB’s horizontal scaling capabilities surpass relational databases’ typical vertical scaling limitations, making it suitable for bigdata applications. 2024’s top Power BI interview questions simplified.
It secures your data in the lakehouse by defining fine-grained permissions, which are consistently applied across all analytics and ML tools and engines. You can bring data from operational databases and applications into your lakehouse in near real time through zero-ETL integrations.
This work overcomes fragmented governance solutions, where fine-grained access control could only be enforced for SQL workloads, while bigdata processing with frameworks such as Apache Spark relied on coarse-grained governance at the file level with cluster-bound data access.
We start with the following sample client email: Dear Support Team, Could you please verify the closing price for the Dollar ATM swaption (USD_2Y_1Y) as of March 15, 2024? About the Authors Siokhan Kouassi is a Data Scientist at Parameta Solutions with expertise in statistical machine learning, deep learning, and generative AI.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content