This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
A recent study by Telecom Advisory Services , a globally recognized research and consulting firm that specializes in economic impact studies, shows that cloud-enabled AI will add more than $1 trillion to global GDP from 2024 to 2030. Let’s take a look at the initial group of apps launched at re:Invent 2024.
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI.
In this post, we share how Amazon Web Services (AWS) is helping Scuderia Ferrari HP develop more accurate pit stop analysis techniques using machine learning (ML). Since implementing the solution with AWS, track operations engineers can synchronize the data up to 80% faster than manual methods.
This post focuses on how the QP model used draft centric speculative decoding (SD)also called parallel decodingwith AWS AI chips to meet the demands of Prime Day. AWS AI chips and parallel decoding To overcome these challenges, Rufus adopted parallel decoding, a simple yet powerful technique for accelerating LLM generation.
In business for 145 years, Principal is helping approximately 64 million customers (as of Q2, 2024) plan, protect, invest, and retire, while working to support the communities where it does business and build a diverse, inclusive workforce. The following diagram illustrates the Principal generative AI chatbot architecture with AWS services.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
Previously, setting up a custom labeling job required specifying two AWS Lambda functions: a pre-annotation function, which is run on each dataset object before it’s sent to workers, and a post-annotation function, which is run on the annotations of each dataset object and consolidates multiple worker annotations if needed.
The AWS DeepRacer League is the worlds first autonomous racing league, open to anyone. While the final championships concluded at re:Invent 2024, that same event played host to a brand new AI competition, ushering in a new era of gamified learning in the age of generative AI.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! are the sessions dedicated to AWS DeepRacer !
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, is within the verified semantic cache. Query processing: a.
According to a Gartner survey in 2024 , 58% of finance functions have adopted generative AI, marking a significant rise in adoption. It combines interactive dashboards, natural language query capabilities, pixel-perfect reporting , machine learning (ML) driven insights, and scalable embedded analytics in a single, unified service.
The AWS DeepRacer League is the world’s first autonomous racing league, open to everyone and powered by machine learning (ML). AWS DeepRacer brings builders together from around the world, creating a community where you learn ML hands-on through friendly autonomous racing competitions.
AWS DeepRacer League 2024 Championship finalists at re:Invent 2024 The AWS DeepRacer League is the worlds first global autonomous racing league powered by machine learning (ML). The following image displays the 2024 qualifiers.
This post explores how Onity Group , a financial services company specializing in mortgage servicing and origination, used Amazon Bedrock and other AWS services to transform their document processing capabilities. Amazon Textract is a ML service that automates the extraction of text, data, and insights from documents and images.
In 2024, climate disasters caused more than $417B in damages globally, and theres no slowing down in 2025 with LA wildfires that destroyed more than $135B in the first month of the year alone. To offer a more concrete look at these trends, the following is a deep dive into how climate tech startups are building FMs on AWS.
Amazon Lookout for Vision , the AWS service designed to create customized artificial intelligence and machine learning (AI/ML) computer vision models for automated quality inspection, will be discontinuing on October 31, 2025. For an out-of-the-box solution, the AWS Partner Network offers solutions from multiple partners.
It also comes with ready-to-deploy code samples to help you get started quickly with deploying GeoFMs in your own applications on AWS. Custom geospatial machine learning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machine learning (ML) tasks. Lets dive in!
Since our founding nearly two decades ago, machine learning (ML) and artificial intelligence (AI) have been at the heart of building data-driven products that better match job seekers with the right roles and get people hired. Within weeks, we fine-tuned our best-performing model to-date and released it.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. We’ll walk through the process of deploying NVIDIA NIM microservices from AWS Marketplace for SageMaker Inference.
Amazon Rekognition people pathing is a machine learning (ML)–based capability of Amazon Rekognition Video that users can use to understand where, when, and how each person is moving in a video. Example code The following code example is a Python script that can be used as an AWS Lambda function or as part of your processing pipeline.
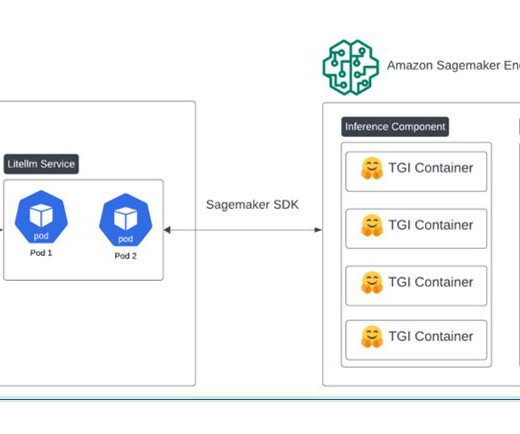
Implementation details We spin up the cluster by calling the SageMaker control plane through APIs or the AWS Command Line Interface (AWS CLI) or using the SageMaker AWS SDK. To request a service quota increase, on the AWS Service Quotas console , navigate to AWS services , Amazon SageMaker , and choose ml.p4d.24xlarge
You can try this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Prerequisites To try out Pixtral 12B in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources.
We guide you through a step-by-step implementation on how you can use the ( AWS CLI ) or the AWS Management Console to find, review, and create optimal training plans for your specific compute and timeline needs. If you’re setting up the AWS CLI for the first time, follow the instructions at Getting started with the AWS CLI.
Throughout these examples, you will learn how the comprehensive suite of AWS services, including Amazon Bedrock and Amazon SageMaker , are the key to success. The quality assurance process includes automated testing methods combining ML-, algorithm-, or LLM-based evaluations. The team extensively used fine-tuned SLMs.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Through Bedrock Marketplace, organizations can use Nemotron’s advanced capabilities while benefiting from the scalable infrastructure of AWS and NVIDIA’s robust technologies. Marc Karp is an ML Architect with the Amazon SageMaker Service team.
At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society. Achieving ISO/IEC 42001 certification means that an independent third party has validated that AWS is taking proactive steps to manage risks and opportunities associated with AI development, deployment, and operation.
AWS Field Experience (AFX) empowers Amazon Web Services (AWS) sales teams with generative AI solutions built on Amazon Bedrock , improving how AWS sellers and customers interact. Last year, AFX introduced Account Summaries as the first in a forthcoming lineup of tools designed to support and streamline sales workflows.
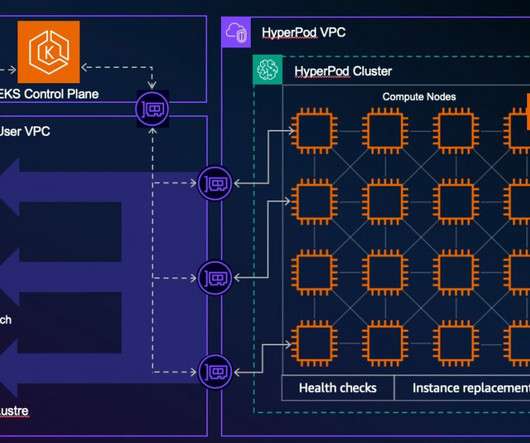
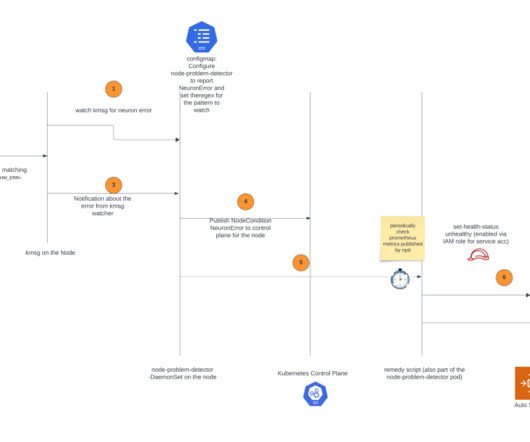
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
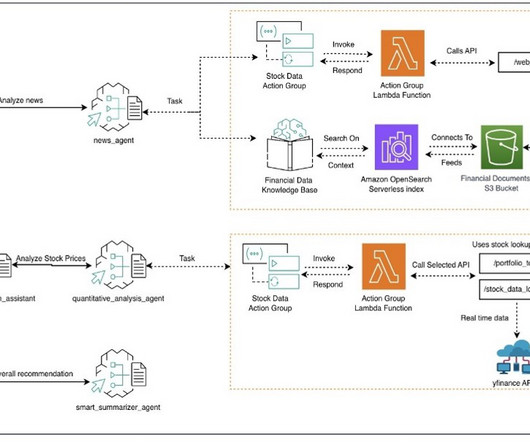
You also need to deploy two AWS CloudFormation stacks: web_search and stock_data. You can also explore and run Amazon Bedrock multi-agent collaboration workshop with AWS specialists or on your own. About the Authors Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. The example extracts and contextualizes the buildspec-1-10-2.yml
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. You can track these job status details in both the AWS Management Console and AWS SDK. You are given a question and a set of possible functions.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. The import job can be invoked using the AWS Management Console or through APIs. Service access role.
" — James Lin, Head of AI ML Innovation, Experian The Path Forward: From Lab to Production in Days, Not Months Early customers are already experiencing the transformation Agent Bricks delivers – accuracy improvements that double performance benchmarks and reduce development timelines from weeks to a single day.
Since launching in June 2023, the AWS Generative AI Innovation Center team of strategists, data scientists, machine learning (ML) engineers, and solutions architects have worked with hundreds of customers worldwide, and helped them ideate, prioritize, and build bespoke solutions that harness the power of generative AI.
This post is part of an ongoing series on governing the machine learning (ML) lifecycle at scale. To start from the beginning, refer to Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker.
Amazon SageMaker HyperPod recipes At re:Invent 2024, we announced the general availability of Amazon SageMaker HyperPod recipes. This design simplifies the complexity of distributed training while maintaining the flexibility needed for diverse machine learning (ML) workloads, making it an ideal solution for enterprise AI development.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This feature is only supported when using inference components.
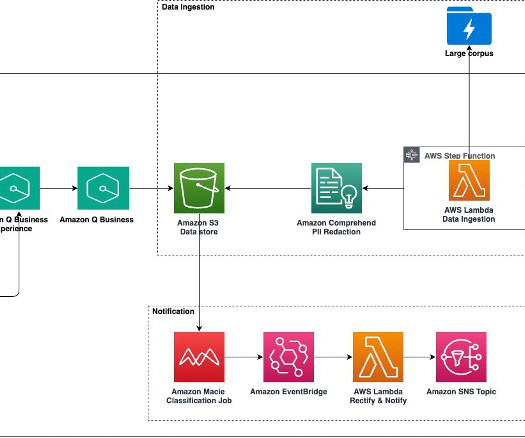
To solve this problem, this post shows you how to apply AWS services such as Amazon Bedrock , AWS Step Functions , and Amazon Simple Email Service (Amazon SES) to build a fully-automated multilingual calendar artificial intelligence (AI) assistant. It lets you orchestrate multiple steps in the pipeline.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
Over the last 18 months, AWS has announced more than twice as many machine learning (ML) and generative artificial intelligence (AI) features into general availability than the other major cloud providers combined. The following figure highlights where AWS lands in the DSML Magic Quadrant.
According to New Relic’s 2024 Observability Forecast , businesses face a median annual downtime of 77 hours from high-impact outages. To get started on training, enroll for free Amazon Q training from AWS Training and Certification. Customer Solutions Manager at AWS. Solutions Architect at AWS. million per hour.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























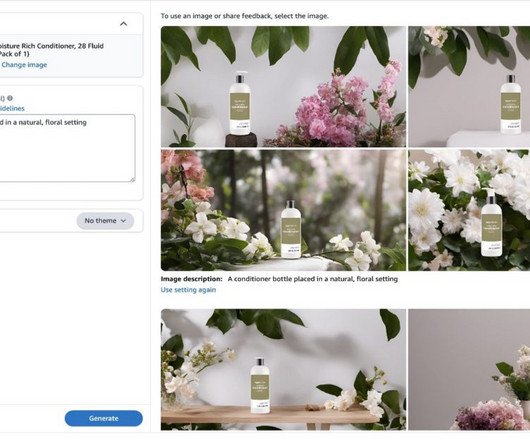





















Let's personalize your content