This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
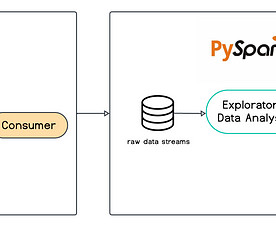
Last Updated on February 29, 2024 by Editorial Team Author(s): Hira Akram Originally published on Towards AI. Within this article, we will explore the significance of these pipelines and utilise robust tools such as ApacheKafka and Spark to manage vast streams of data efficiently. Next, we run an SQL query to extract the data.
Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more. Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as ApacheKafka. This also means that it comes with a large community and comprehensive documentation.
billion by 2031, growing at a CAGR of 25.55% during the forecast period from 2024 to 2031. million in 2024 and is projected to grow at a CAGR of 26.8% billion in 2024 to USD 774.00 during the forecast period from 2024 to 2032. The global data warehouse as a service market was valued at USD 9.06 from 2025 to 2030.
billion in 2024 and reach a staggering $924.39 What is Apache Hive? Hive is a data warehouse tool built on Hadoop that enables SQL-like querying to analyse large datasets. What are the Key Features of Apache Hive? Explain the Role of Apache HBase. What is ApacheKafka, and Why is it Used?
It manipulates data using SQL (Structured Query Language). It offers high performance and supports SQL queries, making it a modern solution for large-scale applications. Facebook As of 2024, Facebook is the largest social media platform globally, boasting approximately 3.07 Famous examples include MySQL , PostgreSQL, and Oracle.
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content