This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
He highlights innovations in data, infrastructure, and artificial intelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
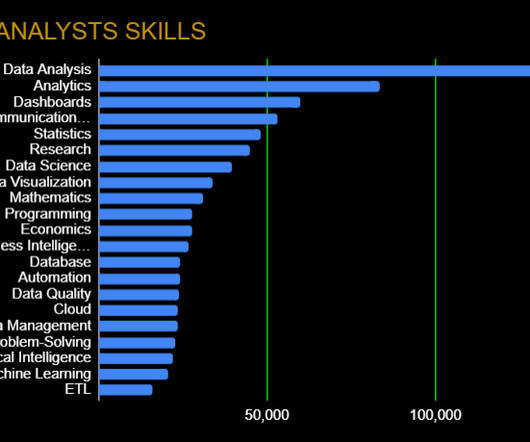
Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently. We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023. Sign up now, start learning today !
Uber understood that digital superiority required the capture of all their transactional data, not just a sampling. They stood up a file-based datalake alongside their analytical database. Because much of the work done on their datalake is exploratory in nature, many users want to execute untested queries on petabytes of data.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Redefining cloud database innovation: IBM and AWS In late 2023, IBM and AWS jointly announced the general availability of Amazon relational database service (RDS) for Db2. This service streamlines data management for AI workloads across hybrid cloud environments and facilitates the scaling of Db2 databases on AWS with minimal effort.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution.
He is currently leading the Data, Advanced Analytics & Cloud Development team in the Digital, IT, Transformation & Operational Excellence department at Cepsa Química, with a focus in feeding the corporate datalake and democratizing data for analysis, machine learning projects, and business analytics.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
Sources The sources involved could influence or determine the options available for the data ingestion tool(s). These could include other databases, datalakes, SaaS applications (e.g. Data flows from the current data platform to the destination. Below are a few of the items that need to be taken into account.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access. Watsonx.data allows customers to augment data warehouses such as Db2 Warehouse and Netezza and optimize workloads for performance and cost.
But it has been sunset by its original creator in April 2023, who recommends switching to JupySQL , which is an actively maintained fork. This typically involves dealing with complexities such as ensuring secure and simple access to internal data warehouses, datalakes, and databases.
The use of separate data warehouses and lakes has created data silos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
In transitional modeling, we’d add new atoms: Subject: Customer#1234 Predicate: hasEmailAddress Object: "john.new@example.com" Timestamp: 2023-07-24T10:00:00Z The old email address atoms are still there, giving us a complete history of how to contact John. Both persistent staging and datalakes involve storing large amounts of raw data.
If youve ever managed large Parquet or CSV datasets on Amazon S3 especially using AWS Glue youve likely faced data consistency, schema evolution, and query performance challenges. Apache Iceberg flips that model on its head by bringing database-like capabilities to your datalake. impl", "org.apache.iceberg.aws.s3.S3FileIO")
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content