This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
Bureau of Labor Statistics predicting a 35% increase in job openings from 2022 to 2032. Let’s dig into some of the most asked interview questions from AI Scientists with best possible answers Core AI Concepts Explain the difference between supervised, unsupervised, and reinforcement learning.
Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find. That’s not a path to improvement.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. In March of 2022, DeepMind released Chinchilla AI.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. In March of 2022, DeepMind released Chinchilla AI.
The use of human teleoperation as a fallback mechanism is increasingly popular in modern robotics companies: Waymo calls it “fleet response,” Zoox calls it “TeleGuidance,” and Amazon calls it “continual learning.” A remote human teleoperator at Phantom Auto, a software platform for enabling remote driving over the Internet.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. during the forecast period.
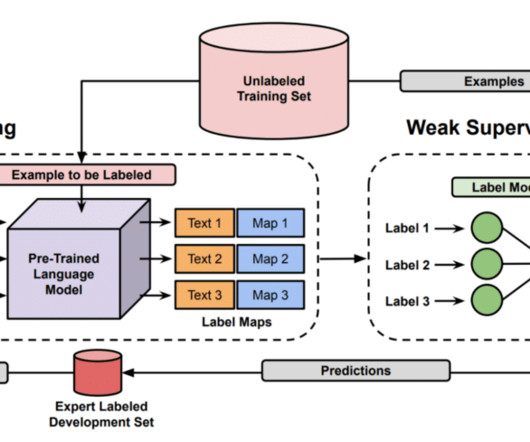
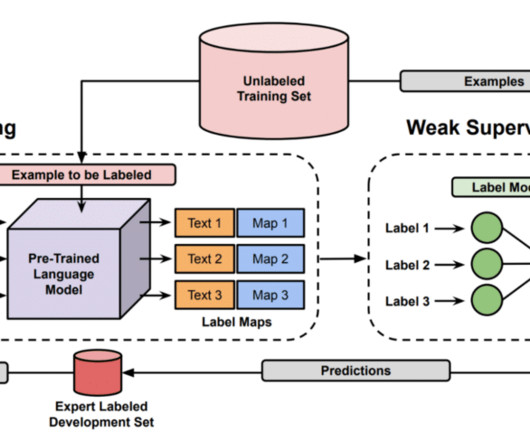
However, this requires access to a labeled data set—and we’re back to the world of supervisedlearning! Each combines foundation model outputs with weak supervision in order to obtain improved performance while sidestepping label-hungry fine-tuning methods. What can be done in settings with little or no labeled data?
However, this requires access to a labeled data set—and we’re back to the world of supervisedlearning! Each combines foundation model outputs with weak supervision in order to obtain improved performance while sidestepping label-hungry fine-tuning methods. What can be done in settings with little or no labeled data?
As the global Machine Learning market expands—valued at USD 35.80 billion in 2022 and projected to reach USD 505.42 This article explores the various methods, benefits, and applications of Data Augmentation in Machine Learning, highlighting its essential role in enhancing model performance and overcoming data limitations.
Introduction Machine Learning is critical in shaping modern technologies, from autonomous vehicles to personalised recommendations. The global Machine Learning market was valued at USD 35.80 billion in 2022 and is expected to grow significantly, reaching USD 505.42 Common SupervisedLearning tasks include classification (e.g.,
Today, 35% of companies report using AI in their business, which includes ML, and an additional 42% reported they are exploring AI, according to the IBM Global AI Adoption Index 2022. Using AutoML or AutoAI, opensource libraries such as scikit-learn and hyperopt, or hand coding in Python, ML engineers create and train the ML models.
supervisedlearning and time series regression). For code-first users, we offer a code experience too, using the AP—both in Python and R—for your convenience. The machine learning life cycle always starts with the dataset. AI Experience 2022 Recordings. The process I will present will be using the DataRobot GUI.
The global Machine Learning market continues to expand. billion in 2022 and is projected to reach USD 505.42 Thus, the significance of repositories like the UCI Machine Learning repository grows. These datasets are crucial for developing, testing, and validating Machine Learning models and for educational purposes.
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference. And that’s the power of self-supervisedlearning. A transcript of Koul’s talk is provided below.
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference. And that’s the power of self-supervisedlearning. A transcript of Koul’s talk is provided below.
Introduction Machine Learning is rapidly transforming industries. billion in 2022 to approximately USD 771.38 A Machine Learning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency. The global market is projected to grow from USD 38.11
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. Prompted to write a Python function to evaluate the quality of scientists based on a JSON description of their race and gender, it generated code that favored only white, male scientists. “Is
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” Then OpenAI released ChatGPT in Novermber 2022.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” Then OpenAI released ChatGPT in Novermber 2022.
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. It is very easy for a data scientist to use Python or R and create machine learning models without input from anyone else in the business operation. .
Data2Vec: A General Framework For Self-SupervisedLearning in Speech, Vision and Language. Check out my introductory article here that acts as a roadmap through the architecture. References Baevski, A., and Auli, M., Available from: [link]. Bojanowski, P., and Mikolov, T., Enriching Word Vectors with Subword Information. arXiv.org.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: Support Vector Machine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
Chip Huyen, co-founder and CEO of Claypot AI gave a presentation entitled “Platform for Real-Time Machine Learning” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. I’m a co-founder of Claypot AI, and I assist with machine learning AI systems designed at Stanford. Hello, my name is Chip.
Chip Huyen, co-founder and CEO of Claypot AI gave a presentation entitled “Platform for Real-Time Machine Learning” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. I’m a co-founder of Claypot AI, and I assist with machine learning AI systems designed at Stanford. Hello, my name is Chip.
Chip Huyen, co-founder and CEO of Claypot AI gave a presentation entitled “Platform for Real-Time Machine Learning” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. I’m a co-founder of Claypot AI, and I assist with machine learning AI systems designed at Stanford. Hello, my name is Chip.
Supervisedlearning can help tune LLMs by using examples demonstrating some desired behaviors, which is called supervised fine-tuning (SFT). This method is called reinforcement learning from human feedback ( Ouyang et al. This leads to responses that are untruthful, toxic, or simply not helpful to the user.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content