This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After taking some free online courses in Python and machine learning, he quickly became immersed in a fascinating new world of data and algorithms. She told him about programming languages and what the career was like, and out of curiosity he decided to take an online Python course. So I began to take it seriously.”
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Zero, “ How to write better scientific code in Python,” Towards Data Science, Feb. 15, 2022. [4] Galarnyk, “ Considerations for Deploying Machine Learning Models in Production,” Towards Data Science, Nov.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. in Ecology, he brings a unique perspective to statistics, spatial analysis, and real-world data applications.
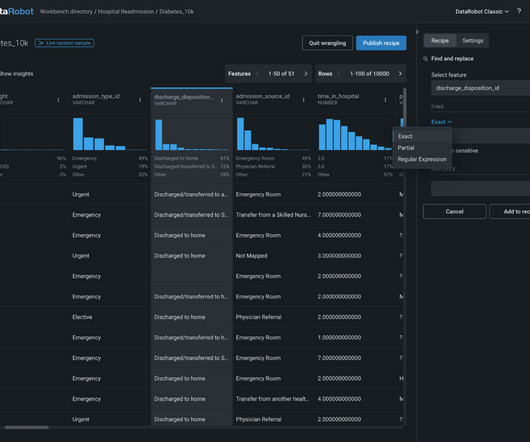
Secure, Seamless, and Scalable ML DataPreparation and Experimentation Now DataRobot and Snowflake customers can maximize their return on investment in AI and their cloud data platform. Automated datapreparation and well-defined APIs allow you to quickly frame business problems as training datasets.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring. That is a huge improvement and time savings because in 2022, 4 million pet profiles were uploaded.
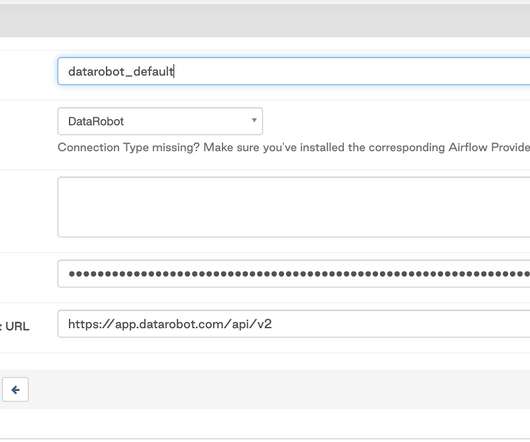
The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index). The integration uses the DataRobot Python API Client , which communicates with DataRobot instances via REST API. DataRobot Python API Client >= 2.27.1.
LangChain is an open source Python library designed to build applications with LLMs. Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on. For more detailed steps to prepare the data, refer to the GitHub repo.
Data Engineers work to build and maintain data pipelines, databases, and data warehouses that can handle the collection, storage, and retrieval of vast amounts of data. Future of Data Engineering The Data Engineering market will expand from $18.2 billion in 2022 to grow at a whopping 36.7%
Today, 35% of companies report using AI in their business, which includes ML, and an additional 42% reported they are exploring AI, according to the IBM Global AI Adoption Index 2022. MLOps fosters greater collaboration between data scientists, software engineers and IT staff.
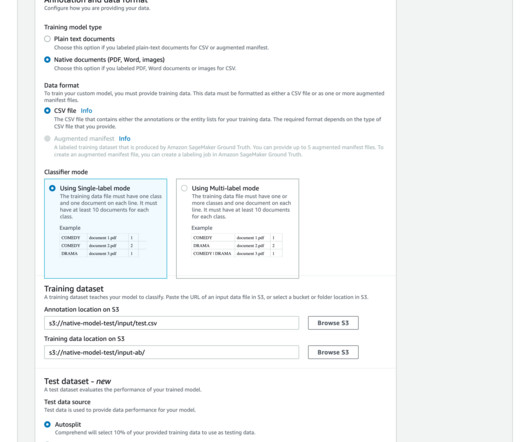
At AWS re:Invent 2022, Amazon Comprehend , a natural language processing (NLP) service that uses machine learning (ML) to discover insights from text, launched support for native document types. This new feature gave you the ability to classify documents in native formats (PDF, TIFF, JPG, PNG, DOCX) using Amazon Comprehend.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. billion in 2022 and is expected to grow to USD 505.42
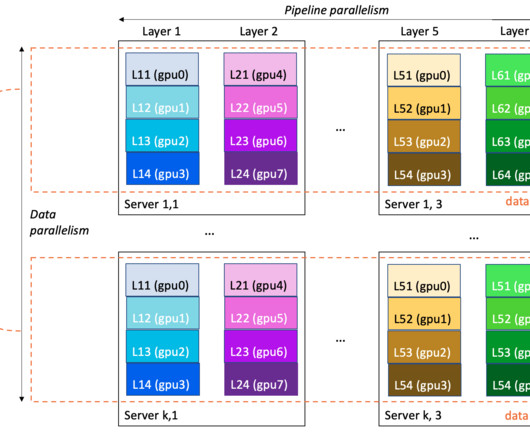
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed.
billion in 2022 and is projected to reach USD 505.42 The two most common formats are: CSV (Comma-Separated Values) : A widely used format for tabular data, CSV files are simple to use and can be opened in various tools, such as Excel, R, Python, and others. The global Machine Learning market continues to expand. billion by 2031.
As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. The global Big Data and Data Engineering Services market, valued at USD 51,761.6 million in 2022, is projected to grow at a CAGR of 18.15% , reaching USD 140,808.0
billion in 2022 and is expected to grow significantly, reaching USD 505.42 Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. It offers extensive support for Machine Learning, data analysis, and visualisation.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. Data extraction and massage, delivery to destinations like Google/Meta/TikTok/etc.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Metaflow differs from other pipelining frameworks because it can load and store artifacts (such as data and models) as regular Python instance variables.
Introduction Six months ago, when I started learning data science with my first Python project ( LINK ) — a simple text classification problem for the Yelp review data, the focus was learning how to implement basic sk-learn modules to get the results out in a Jupyter notebook environment. This means, for example, executing main.py
An end-to-end Machine Learning Project has the following steps: Problem statement Data Collection Data Visualisation DataPreparation Building a Model Deployment of the Model Figure 1: Process of an End-to-End Machine Learning Project Problem Statement Let’s say you are working as a Data Scientist at a hospital.
Solution overview To implement our RAG workflow on SageMaker JumpStart, we use a popular open source Python library known as LangChain. SageMaker JumpStart simplifies this process because the model artifacts, data, and container specifications are all pre-packaged for optimal inference.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
We then also cover how to fine-tune the model using SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 models using the SageMaker Python SDK. billion in 2022.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content