This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, DataScience, Machine Learning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
For decades, managing data essentially meant collecting, storing, and occasionally accessing it. That has all changed in recent years, as businesses look for the critical information that can be pulled from the massive amounts of data being generated, accessed, and stored in myriad locations, from corporate data centers to the cloud.
With that, data analytics tools have become more imperative than ever, as they can help organizations analyze changing business patterns as well as offer insightful visibility […]. The post Three Ways Data Analytics Will Progress in 2022 and Beyond appeared first on DATAVERSITY.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any datascience and machine learning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
Why does AI need an open data lakehouse architecture? from 2022 to 2026. Another IDC study showed that while 2/3 of respondents reported using AI-driven data analytics, most reported that less than half of the data under management is available for this type of analytics.
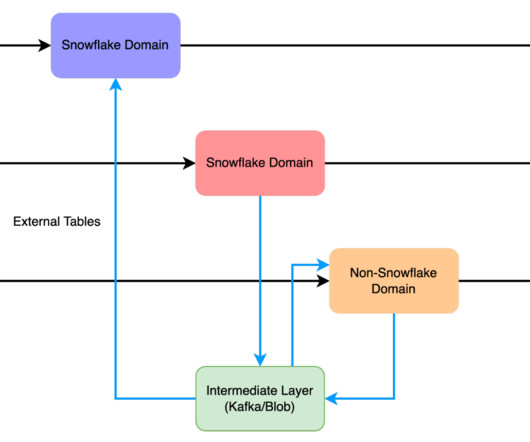
In 2022, the term data mesh has started to become increasingly popular among Snowflake and the broader industry. This data architecture aims to solve a lot of the problems that have plagued enterprises for years. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir. He then joined Getir in 2019 and currently works as DataScience & Analytics Manager.
Overview of solution Five people from Getir’s datascience team and infrastructure team worked together on this project. He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. She joined Getir in 2022, and has been working as a Data Scientist.
February 14, 2022 - 6:11pm. February 15, 2022. They had datascience groups, they had an AI center of excellence, they had investments, they were developing proof of concepts—trying to figure out the art of the possible. Vidya Setlur. Director of Research, Tableau. Kristin Adderson.
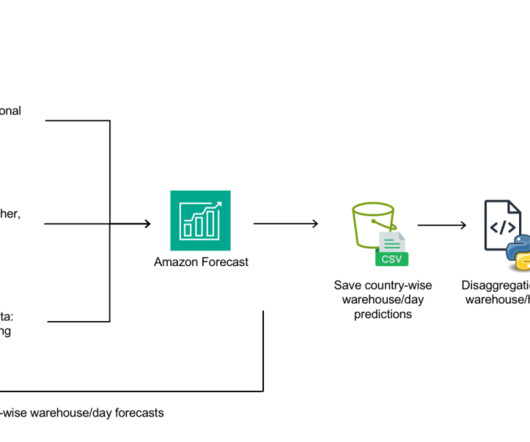
Manager DataScience at Marubeni Power International. Data collection and ingestion The data collection and ingestion layer connects to all upstream data sources and loads the data into the datalake. 11/7/2022 17 RT Energy LCIENEGA_6_N001 5.15 $105.34 He holds a Ph.D.
February 14, 2022 - 6:11pm. February 15, 2022. They had datascience groups, they had an AI center of excellence, they had investments, they were developing proof of concepts—trying to figure out the art of the possible. Vidya Setlur. Director of Research, Tableau. Kristin Adderson.
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. Results The following table summarizes the results using the baseline and the customized neural network models, with 7/1/2022 as the train/test split point.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. Use this guide to get started with your prompt engineering skills!
Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. He joined Getir in 2019 and currently works as a Senior DataScience & Analytics Manager. She then joined Getir in 2022 as a Senior Data Scientist working on forecasting and search engine projects.
Amazon Simple Storage Service (Amazon S3) object storage acts as a content datalake. TR built processes to securely access data from the content datalake to users’ experimentation workspaces while maintaining required authorization and auditability. TR worked closely with the SageMaker service team on this issue.
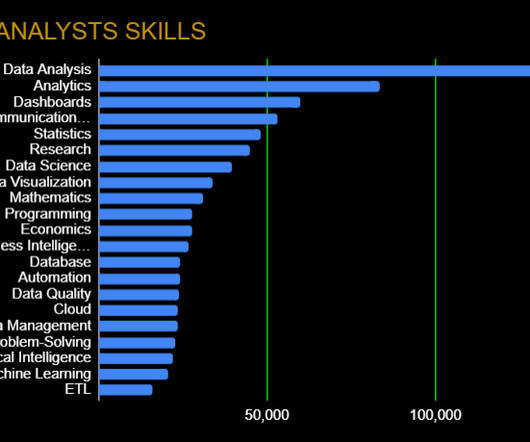
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently. Cloud Services: Google Cloud Platform, AWS, Azure.
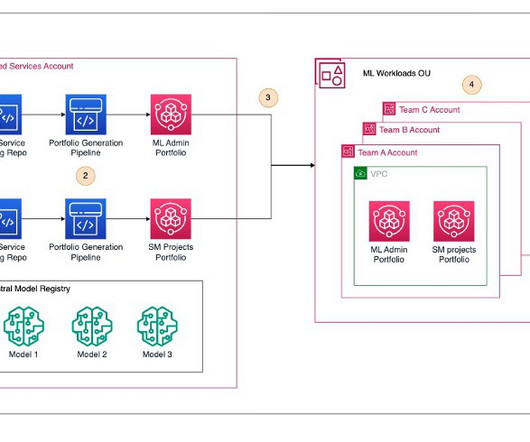
Datascience teams often face challenges when transitioning models from the development environment to production. Usually, there is one lead data scientist for a datascience group in a business unit, such as marketing. ML Dev Account This is where data scientists perform their work.
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. About the authors Julia Hu is a Sr.
Microsoft announced the public preview availability of Datamarts in May 2022. The Datamarts capability opens endless possibilities for organizations to achieve their data analytics goals on the Power BI platform. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. The global Big Data and Data Engineering Services market, valued at USD 51,761.6 million in 2022, is projected to grow at a CAGR of 18.15% , reaching USD 140,808.0
Data Engineering plays a critical role in enabling organizations to efficiently collect, store, process, and analyze large volumes of data. It is a field of expertise within the broader domain of data management and DataScience. Future of Data Engineering The Data Engineering market will expand from $18.2
What are the similarities and differences between data centers, datalake houses, and datalakes? Data centers, datalake houses, and datalakes are all related to data storage and management, but they have some key differences. Not a cloud computer?
The re-insurance product that they introduced was inspired by collaboration between geographically dispersed teams coming together through the Alation Data Catalog. With the introduction of a new datalake, MunichRe created a new way for actuaries and business experts to explore new product concepts and test new markets.
By storing all model-training-related artifacts, your data scientists will be able to run experiments and update models iteratively. Versioning Your datascience team will benefit from using good MLOps practices to keep track of versioning, particularly when conducting experiments during the development stage. Model registry.
With this service, industrial sensors, smart meters, and OPC UA servers can be connected to an AWS datalake with just a few clicks. It’s an easy way to run analytics on IoT data to gain accurate insights. He published a book on time series analysis in 2022 and regularly writes about this topic on LinkedIn and Medium.
To answer these questions we need to look at how data roles within the job market have evolved, and how academic programs have changed to meet new workforce demands. In the 2010s, the growing scope of the data landscape gave rise to a new profession: the data scientist. A lack of data literacy slows down the process.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Begin by identifying bottlenecks in your existing pipeline, such as duplicate data collection points or slow processing times. Implement tools that allow real-time data integration and transformation to maintain accuracy and timeliness. billion in 2022, is projected to skyrocket to $142 billion by 2032, growing at a CAGR of 18.1%.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Big Data wurde für viele Unternehmen der traditionellen Industrie zur Enttäuschung, zum falschen Versprechen. Datenqualität hingegen, wurde zum wichtigen Faktor jeder Unternehmensbewertung, was Themen wie Reporting, Data Governance und schließlich dann das Data Engineering mehr noch anschob als die DataScience.
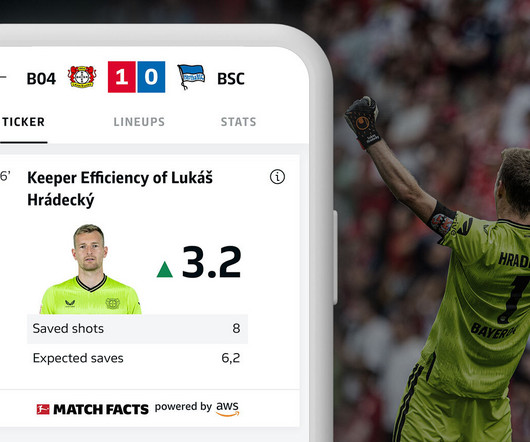
In 2022/23 so far, he has almost secured a clean sheet every other match for Die Schwarzgelben, despite the team’s inconsistency and often poor midfield performance. The information also gets stored in a datalake for future auditing and model improvements. Tareq Haschemi is a consultant within AWS Professional Services.
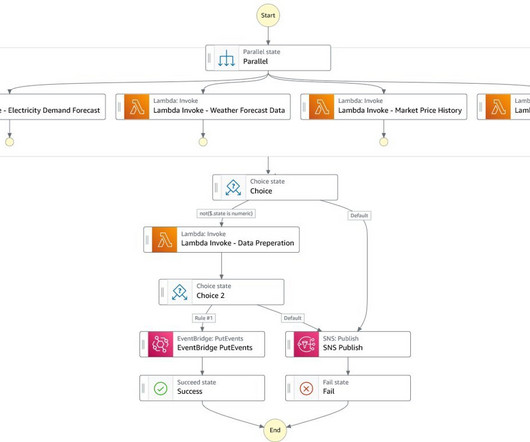
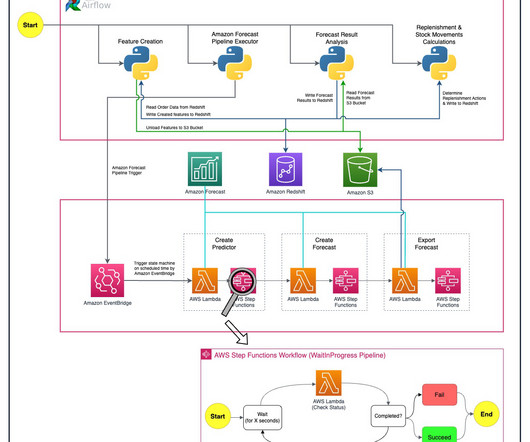
The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters. Kale v0.7.0.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/DataScience knowledge would be good. You’ll own and work with everything from distributed queues and datalakes to prompt evaluation and agentic orchestration.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content