This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
Using the “Top Spotify songs from 2010-2019” dataset on Kaggle ( [link] ), we read it into a Python – Pandas Data Frame. This is a default index created by python for this dataset, while considering the first column present in the csv file as an “unnamed” column. You may only build a single Primary or Clustered index on a table.
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
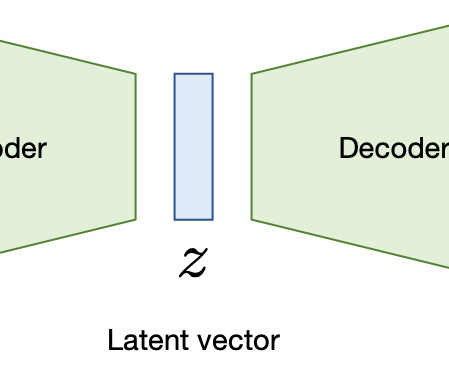
To build L-Eval, the authors first created four new datasets: Coursera (educational content), SFiction (science fiction stories), CodeU (Python codebases), and LongFQA (financial earnings). Clustering : Aggregating and grouping relevant information from multiple sources based on specific criteria.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Working on community projects improved my skills in Python, Jupyter, numpy, pandas, and ROS. Within a year, we built a world-class inference platform processing over 2 billion video frames daily using dynamically scaled Amazon Elastic Kubernetes Service (Amazon EKS) clusters.
Bureau of Labor Statistics predicting a 35% increase in job openings from 2022 to 2032. This is used for tasks like clustering, dimensionality reduction, and anomaly detection. For example, clustering customers based on their purchase history to identify different customer segments.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deep learning training. On the Amazon ECS console, choose Clusters in the navigation pane. Choose Create.
In 2022, we expanded our research interactions and programs to faculty and students across Latin America , which included grants to women in computer science in Ecuador. See some of the datasets and tools we released in 2022 listed below. We work towards inclusive goals and work across the globe to achieve them.
You can deploy and use the Falcon LLMs with a few clicks in SageMaker Studio or programmatically through the SageMaker Python SDK. For example, GPT-3 (2020) and BLOOM (2022) feature around 175 billion parameters, Gopher (2021) has 230 billion parameters, and MT-NLG (2021) 530 billion parameters. In 2022, Hoffman et al.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
Machine learning for text extraction with Python is one of the best combos out there for this task. In this blog post, we’ll talk about how one can use Machine learning and Python to perform text extraction with the highest level of accuracy. Python has a network of libraries for tasks related to text processing and machine learning.
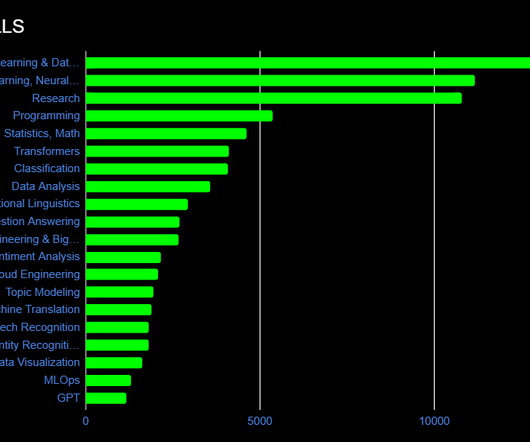
They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization. Here’s a list of key skills that are typically covered in a good data science bootcamp: Programming Languages : Python : Widely used for its simplicity and extensive libraries for data analysis and machine learning.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. The response only cites sources that are relevant to the query.
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. NLP Programming Languages It shouldn’t be a surprise that Python has a strong lead as a programming language of choice for NLP.
They’re available through the SageMaker Python SDK. In these cases, you might be able to speed up the process by distributing training over multiple machines or processes in a cluster. Dask is an open-source parallel computing library that allows for distributed parallel processing of large datasets in Python.
Python The code has been tested with Python version 3.13. For clarity of purpose and reading, weve encapsulated each of seven steps in its own Python script. Return to the command line, and execute the script: python create_invoke_role.py Return to the command line and execute the script: python create_connector_role.py
Memory-safe languages like Java and Python automate allocating and deallocating memory, though there are still ways to work around the languages’ built-in protections. In 2022, security wasn’t in the news as often as it was in 2020 and 2021. C and C++ still require programmers to do much of their own memory management.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
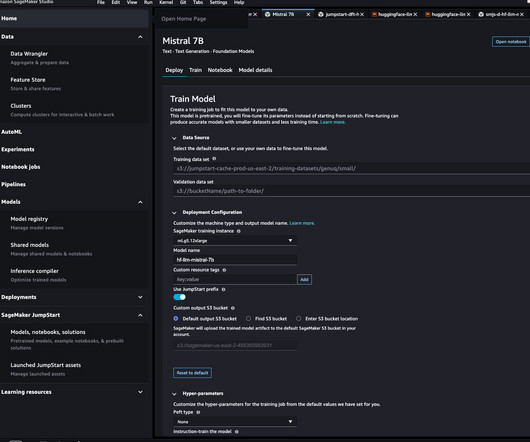
You can now fine-tune and deploy Mistral text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. You can fine-tune the models using either the SageMaker Studio UI or SageMaker Python SDK. The model is made available under the permissive Apache 2.0
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. For this reason, many DJL users also use it for inference only.
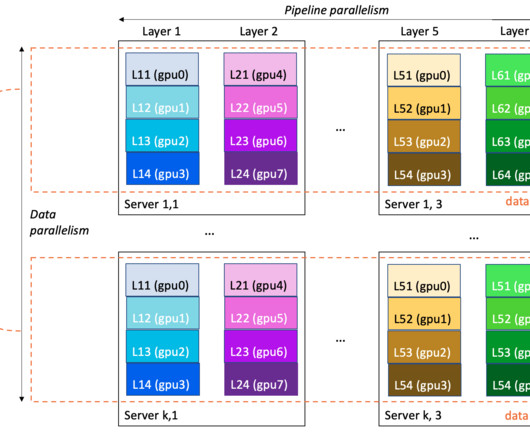
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom.
Big Ideas What to look out for in 2022 1. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Automation Automating data pipelines and models ➡️ 6. Deployment How to build sustainable, scalable live systems ?
October 2022). This function makes it easy to define custom aggregation functions in Python. Here, the Pandas UDF simplifies the hand-off between complex distributed event streaming and locally scoped Python functions. When combined with event-time windows, analyzing the embeddings in real-time becomes much more feasible.
Engineers must manually write custom data preprocessing and aggregation logic in Python or Spark for each use case. For this post, we refer to the following notebook , which demonstrates how to get started with Feature Processor using the SageMaker Python SDK. 50195| 1686627154| | 6| Acura TLX A-Spec| 2023| New| NA|50195.00|50195|
To help simplify the process of moving from interactive notebooks to batch jobs, in December 2022, Amazon SageMaker Studio and Studio Lab introduced the capability to run notebooks as scheduled jobs, using notebook-based workflows. Prerequisites For this post, we assume a locally hosted JupyterLab environment. or higher).
Further, it will provide a step-by-step guide on anomaly detection Machine Learning python. CAGR during 2022-2030. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. How to do Anomaly Detection using Machine Learning in Python?
This step-function instantiated a cluster of instances to extract and process data from S3 and the further steps of pre-processing, training, evaluation would run on a single large EC2 instance. We could re-use the previous Sagemaker Python SDK code to run the modules individually into Sagemaker Pipeline SDK based runs.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 On the server side, we opted for Python. I have been actively engaged in the "AI Engineer" community since it sprang up in November 2022. bge-small-en-v1.5
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. billion in 2022 and is expected to grow to USD 505.42 Key Takeaways Strong programming skills in Python and R are vital for Machine Learning Engineers. during the forecast period.
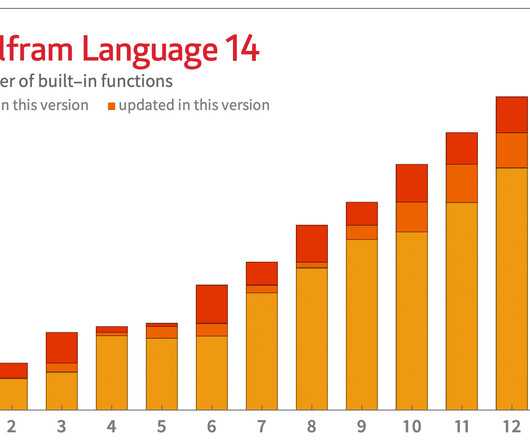
But—like everyone else—we were taken by surprise at the end of 2022 by ChatGPT and its remarkable capabilities. but with things like clustering). There’s one setup for interpreted languages like Python. Let’s start with Python. We’ve had ExternalEvaluate for evaluating Python code since 2018. But in Version 14.0
The Python library offers pre-built workflows, command-line interface, and well-documented components for customized workflow scripting, allowing users to define data loading/saving processes and modify annotation interfaces. support (dropping Python 3.7 Pydantic v2.0, and spacy-llm 0.6.
billion in 2022 and is projected to reach USD 505.42 The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more. Clustering : Datasets that involve grouping data into clusters without predefined labels. It was valued at USD 35.80 billion by 2031.
This technique is based on the concept that related information tends to cluster together. In March of 2022, DeepMind released Chinchilla AI. link] 2/3 pic.twitter.com/kBAavQ3rTC — DeepMind (@DeepMind) April 12, 2022 It is one of the best AI models. For detailed information, we previously explained Chinchilla AI.
This technique is based on the concept that related information tends to cluster together. In March of 2022, DeepMind released Chinchilla AI. link] 2/3 pic.twitter.com/kBAavQ3rTC — DeepMind (@DeepMind) April 12, 2022 It is one of the best AI models. For detailed information, we previously explained Chinchilla AI.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 3: The technical section for the project where Python and pgAdmin4 will be used. CODING STAGE In this stage we are going to code in Python 3.9 Figure 6: Project’s Dashboard 3.
Clustering — we can cluster our sentences, useful for topic modeling. Doc2Vec SBERT InferSent Universal Sentence Encoder Top 4 Sentence Embedding Techniques using Python! OpenAI’s Embedding Model With Vector Database OpenAI updated in December 2022 the Embedding model to text-embedding-ada-002. lower price.
For instance, you could extract a few noisy metrics, such as a general “positivity” sentiment score that you track in a dashboard, while you also produce more nuanced clustering of the posts which are reviewed periodically in more detail. You might want to view the data in a variety of ways.
billion in 2022 to approximately USD 771.38 Here are the core technical skills you need: Programming Languages Python and R are the most commonly used programming languages in Machine Learning. With its extensive libraries such as NumPy, pandas, and scikit-learn, Python is particularly popular for its ease of use and versatility.
billion in 2022 and is expected to grow significantly, reaching USD 505.42 Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. billion by 2031 at a CAGR of 34.20%.
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. It is very easy for a data scientist to use Python or R and create machine learning models without input from anyone else in the business operation. . Model registry.
The Curse of the LLMs 30th November, 2022 will be remembered as the watershed moment in artificial intelligence. Code in python, java etc. Retrieval Augmented Generation becomes powerful as it provides additional memory and context, and increases the confidence in LLM responses. OpenAI released ChatGPT and the world was mesmerised.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















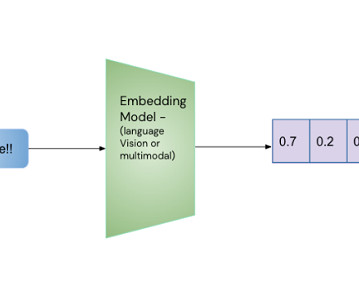


















Let's personalize your content