This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
8 Free MIT Courses to Learn DataScience Online; The Complete Collection Of Data Repositories - Part 1; DBSCAN Clustering Algorithm in Machine Learning; Introductory Pandas Tutorial; People Management for AI: Building High-Velocity AI Teams.
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for Data Analysis. in 2022, according to the PYPL Index.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Big Ideas What to look out for in 2022 1. Team Building the right datascience team is complex.
Bureau of Labor Statistics predicting a 35% increase in job openings from 2022 to 2032. Industry Adoption: Widespread Implementation: AI and datascience are being adopted across various industries, including healthcare, finance, retail, and manufacturing, driving increased demand for skilled professionals.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and data preparation activities.
Most DataScience enthusiasts know how to write queries and fetch data from SQL but find they may find the concept of indexing to be intimidating. This blog will aim to clear concepts of how this additional tool can help you efficiently access data, especially when there are clear patterns involved.
Looking back ¶ When we started DrivenData in 2014, the application of datascience for social good was in its infancy. There was rapidly growing demand for datascience skills at companies like Netflix and Amazon. Weve run 75+ datascience competitions awarding more than $4.7
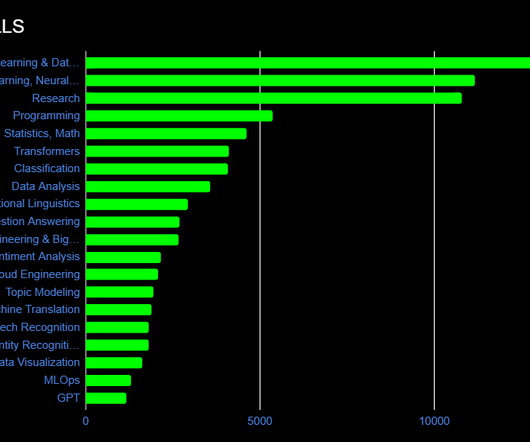
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise.
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group. See some of the datasets and tools we released in 2022 listed below.
Congrats on your paper being accepted into the NeurIPS 2022 Machine Learning and the Physical Sciences workshop. Thus, what became a year and a half of radiance fields and star clusters was born! CDS spoke with Harlan about the project, deep learning methods in the field of astronomy, and advice for current CDS students.
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
While the transformer design dates back to 2017, it exploded into public consciousness in 2022 with ChatGPT. Open-source LLMs allow researchers and enterprises to determine how the models are trained, which datasets are used, and where the models are hosted — whether on local CPUs or custom GPU clusters.
This is due to a deep disconnect between data engineering and datascience practices. Historically, our space has perceived streaming as a complex technology reserved for experienced data engineers with a deep understanding of incremental event processing. October 2022).
The Best Egg datascience team uses Amazon SageMaker Studio for building and running Jupyter notebooks. The datascience team must sometimes work with limited training data in the order of tens of thousands of records given the nature of their use cases.
In 2022, the term data mesh has started to become increasingly popular among Snowflake and the broader industry. This data architecture aims to solve a lot of the problems that have plagued enterprises for years.
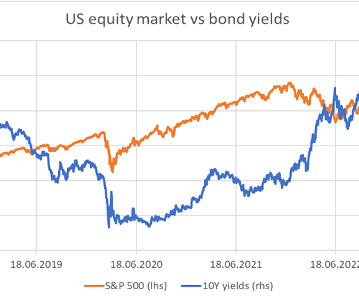
The year 2022 presented two significant turnarounds for tech: the first one is the immediate public visibility of generative AI due to ChatGPT. For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes.
William Huang is a senior data scientist at Capital One. He presented “Data and Manual Annotation Monitoring for Training Data Management” at Snorkel AI’s The Future of Data-Centric AI event in 2022. Today I’ll be talking about monitoring for training data maintenance and looking at manual annotation.
William Huang is a senior data scientist at Capital One. He presented “Data and Manual Annotation Monitoring for Training Data Management” at Snorkel AI’s The Future of Data-Centric AI event in 2022. Today I’ll be talking about monitoring for training data maintenance and looking at manual annotation.
Many companies are now utilizing datascience and machine learning , but there’s still a lot of room for improvement in terms of ROI. billion in 2022, an increase of 21.3% billion in 2022, an increase of 21.3% It continues with the selection of a clustering algorithm and the fine-tuning of a model to create clusters.
There were 4 clusters of users that this report broke down to understand the behavior and tendencies of different users. Cluster 2 : Swap Count : Extremely High (around 54,127 swaps on average) Volume in USD : Extremely High (around $4.43 Cluster 3 : Swap Count : Low (around 10 swaps on average) Volume in USD : Moderate (around $60.25
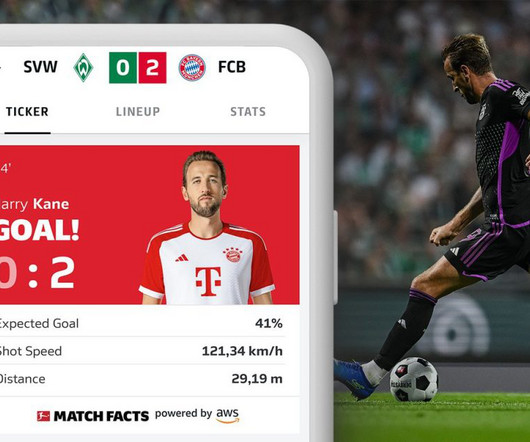
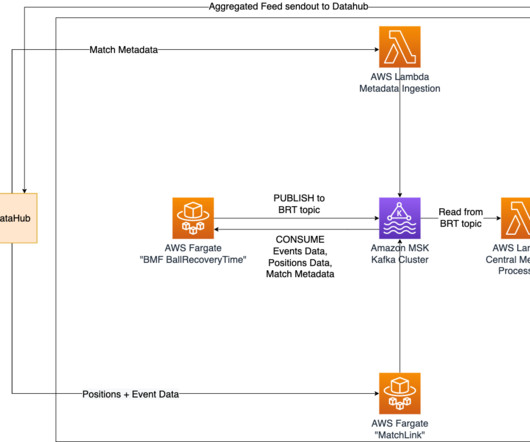
We analyzed around 215 matches from the Bundesliga 2022–2023 season. Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. His skills and areas of expertise include application development, datascience, and machine learning (ML). fast shots.
In these cases, you might be able to speed up the process by distributing training over multiple machines or processes in a cluster. This post discusses how SageMaker LightGBM helps you set up and launch distributed training, without the expense and difficulty of directly managing your training clusters. The processed data takes 8.5
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. Figure 5 provides an overview of the various data mining techniques commonly used in recommendation engines today, and we’ll delve into each of these techniques in more detail.
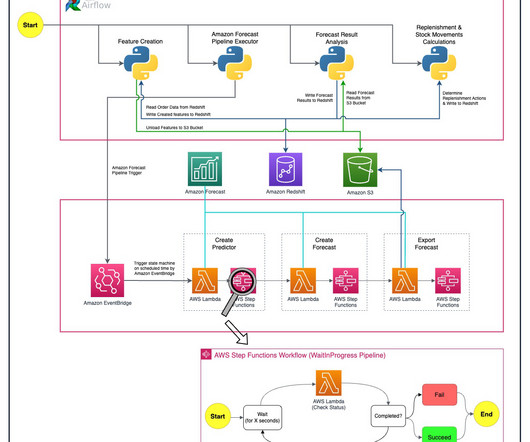
Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. Algorithm Selection Amazon Forecast has six built-in algorithms ( ARIMA , ETS , NPTS , Prophet , DeepAR+ , CNN-QR ), which are clustered into two groups: statististical and deep/neural network.
This style of play is also evident when you look at the ball recovery times for the first 24 match days in the 2022/23 season. Let’s look at certain games played by Cologne in the 2022/23 season. His skills and areas of expertise include application development, datascience, machine learning, and big data.
The company has built a second supercomputing cluster, connecting over 10,000 Nvidia processors, enabling the training of large AI models. This investment was made before US restrictions on advanced chip exports to China took effect in mid-2022. DeepSeek-V2’s performance has been impressive.
With “Science of Gaming” as their core philosophy, they have enabled a vision of end-to-end informatics around game dynamics, game platforms, and players by consolidating orthogonal research directions of game AI, game datascience, and game user research. The already existing solution through Step Functions had limitations.
For example, NVIDIA Triton Inference Server, a high-performance open-source inference software, was natively integrated into the SageMaker ecosystem in 2022. Prior to this role, he was the Head of DataScience for Amazon’s EU Customer Service.
The dataset “ Domestic and international collaboration in AI publications “ contains data on the international collaboration in AI scientific publications. For this post, I selected AI collaboration data for 2022. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
The introduction of ChatGPT in November 2022 upended the AI landscape. Corporate leaders soon urged datascience teams to use large language models (LLMs), and datascience teams turned to fine-tuning and retrieval-augmented generation (RAG) to mitigate generative AI (genAI) shortcomings.
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards DataScience , 2018 ).
It is a mathematical framework that aims to capture the underlying patterns, trends, and structures present in the data. In 2022, around 97% of the companies invested in Big Data and 91% of them invested in AI, clearly stamping that data is becoming the linchpin for successful business. The Data Analytics course by Pickl.AI
In 2022 I actually joined the lab and here we are today. My data sources are usually news, logs and web documents. It’s petabytes of data, so a lot of my time is spent processing it. I mostly use U-SQL, a mix between C# and SQL that can distribute in very large clusters. I use PyTorch for that.
Datascience teams often face challenges when transitioning models from the development environment to production. Usually, there is one lead data scientist for a datascience group in a business unit, such as marketing. ML Dev Account This is where data scientists perform their work.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
The introduction of ChatGPT in November 2022 upended the AI landscape. Corporate leaders soon urged datascience teams to use large language models (LLMs), and datascience teams turned to fine-tuning and retrieval-augmented generation (RAG) to mitigate generative AI (genAI) shortcomings.
Most winners and other competitive solutions had cross-validation scores clustered in the range from 8590 KAF, with 3rd place winner rasyidstat standing out with score of 79.5 Unlike typical datascience competitions, there's no predefined training dataset provided. Won by rasyidstat. quantile corrections.
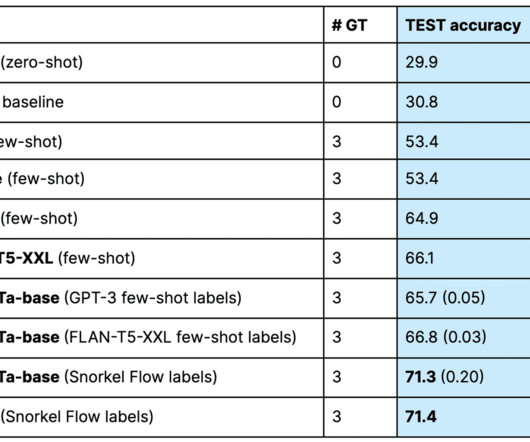
2022’s paper. Hence it is possible to train the downstream task with a few labeled data. 2022 Deep learning notoriously needs a lot of data in training. However, in remote sensing, getting a sufficient number of labeled data remains a challenge. 2022 Figure 3. 2022 Figure 4. Image: Wang et al.,
To run this job repeatedly on a schedule, you had to set up, configure, and oversee cloud infrastructure to automate deployments, resulting in a diversion of valuable time away from core datascience development activities.
billion in 2022 and is projected to reach USD 505.42 It is a central hub for researchers, data scientists, and Machine Learning practitioners to access real-world data crucial for building, testing, and refining Machine Learning models. Clustering : Datasets that involve grouping data into clusters without predefined labels.
The NLP Community Survey , which asks many of these questions and more, was conducted from May to June 2022. Other participating CDS authors include CDS PhD students, Angelica Chen , Nikita Nangia , and Jason Phang as well as CDS Associate Professor of Linguistics and DataScience, Sam Bowman.
Team / participant Features Models Data sources NASAPalooza Paper search, paper recommendation, doc upload, paper summarization, chatbot, people search, keyword extraction, topic trends, dataset analysis GPT-3.5 His expertise and experience make him a valuable asset in the field of datascience and Generative AI.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















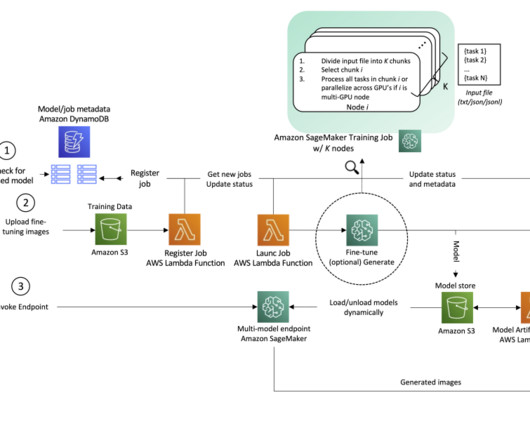
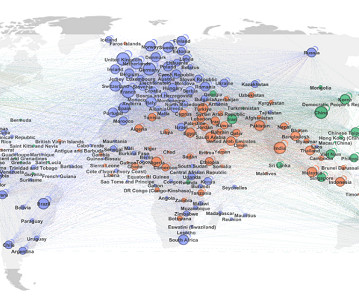
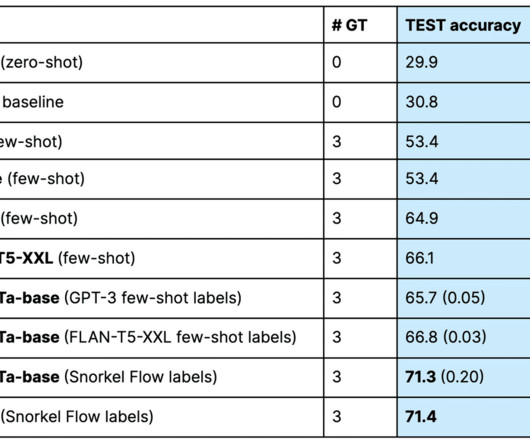



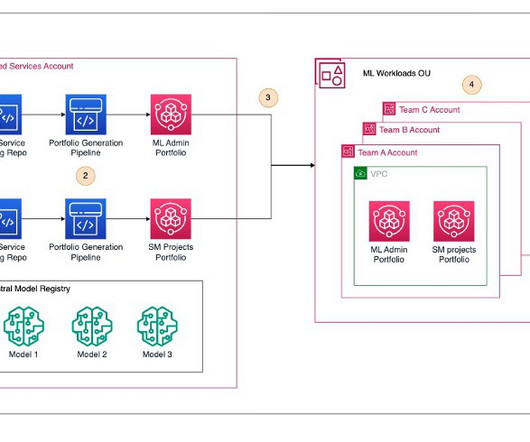












Let's personalize your content