This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ultimately, we can use two or three vital tools: 1) [either] a simple checklist, 2) [or,] the interdisciplinary field of project-management, and 3) algorithms and data structures. In addition to the mindful use of the above twelve elements, our Google-search might reveal that various authors suggest some vital algorithms for data science.
We chose to compete in this challenge primarily to gain experience in the implementation of machine learning algorithms for data science. Summary of approach: Our solution for Phase 1 is a gradient boosted decisiontree approach with a lot of feature engineering. What motivated you to compete in this challenge?
Building a DecisionTree Model in KNIME The next predictive model that we want to talk about is the decisiontree. Unlike linear regression, which is relatively simple, decisiontrees can come in a variety of flavors and can be used for both classification and regression-type models.
From deterministic software to AI Earlier examples of “thinking machines” included cybernetics (feedback loops like autopilots) and expert systems (decisiontrees for doctors). A lot : Some algorithmic advances have lowered the cost of AI by multiple orders of magnitude. When the result is unexpected, that’s called a bug.
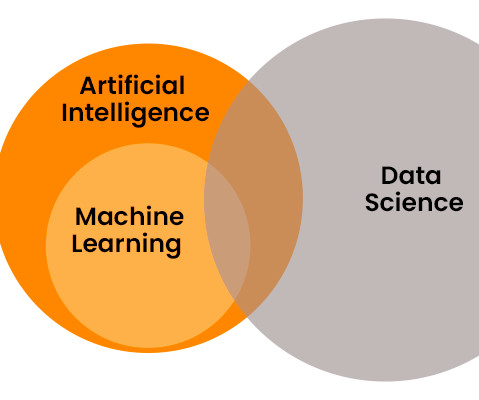
Data Science extracts insights, while Machine Learning focuses on self-learning algorithms. Key takeaways Data Science lays the groundwork for Machine Learning, providing curated datasets for ML algorithms to learn and make predictions. Emphasises programming skills, understanding of algorithms, and expertise in Data Analysis.
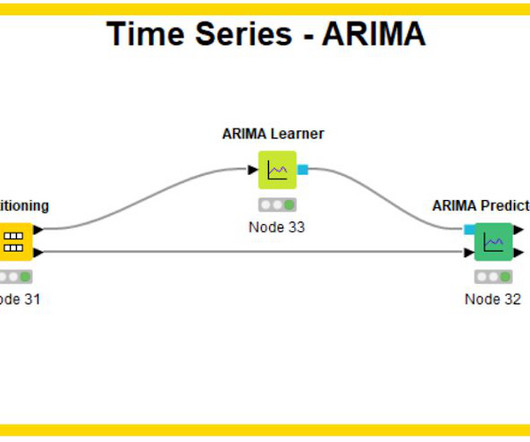
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. This one is a widely used ML algorithm that is mostly focused on capturing complex patterns within tabular datasets.
The remaining features are horizontally appended to the pathology features, and a gradient boosted decisiontree classifier (LightGBM) is applied to achieve predictive analysis. Pathology-Omic Research Platform for Integrative Survival Estimation (PORPOISE) PORPOISE ( Chen et al., Although Chen et al.,
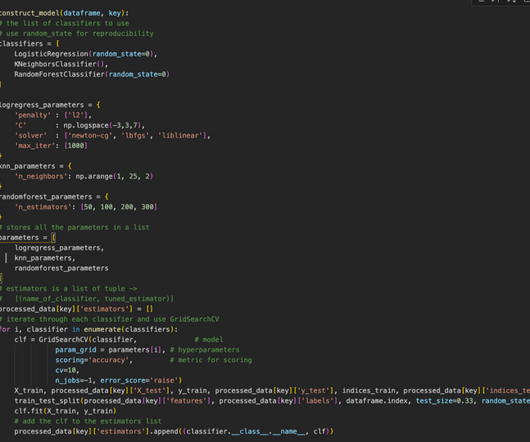
Choose the appropriate algorithm: Select the AI algorithm that best suits the problem you want to solve. Several algorithms are available, including decisiontrees, neural networks, and support vector machines. This involves feeding the algorithm with data and tweaking it to improve its accuracy.
Key Takeaways: As of 2021, the market size of Machine Learning was USD 25.58 The specific techniques and algorithms used can vary based on the nature of the data and the problem at hand. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. CAGR during 2022-2030.
Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. Figure 11 Model Architecture The algorithms and models used for the first three classifiers are essentially the same. In addition, each tree in the forest is made up of a random selection of the best attributes.
Bureau of Labor Statistics predicts that employment for Data Scientists will grow by 36% from 2021 to 2031 , making it one of the fastest-growing professions. These statistics underscore the significant impact that Data Science and AI are having on our future, reshaping how we analyse data, make decisions, and interact with technology.
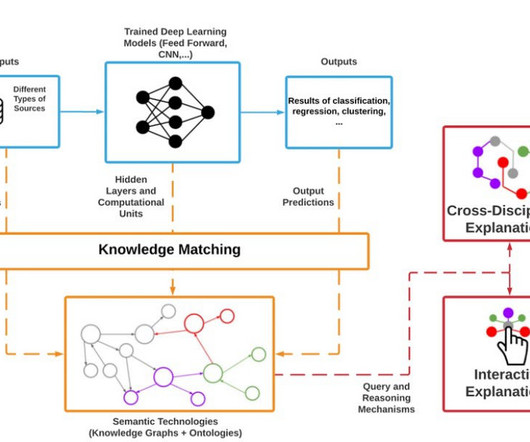
Source: ResearchGate Explainability refers to the ability to understand and evaluate the decisions and reasoning underlying the predictions from AI models (Castillo, 2021). Algorithmic Accountability: Explainability ensures accountability in machine learning and AI systems.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Phase 2 [Build IT!] Phase 3 [Put IT All Together!]
Say, for example, you wanted to summarize the 2021 State of the Union Address –an hour and 43-minute long video. Taking this intuition further, we might consider the TextRank algorithm. Google uses an algorithm called PageRank in order to rank web pages in their search engine results. 67:34: He said the U.S.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content