This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Working on community projects improved my skills in Python, Jupyter, numpy, pandas, and ROS. Within a year, we built a world-class inference platform processing over 2 billion video frames daily using dynamically scaled Amazon Elastic Kubernetes Service (Amazon EKS) clusters.
Software businesses are using Hadoop clusters on a more regular basis now. Take coursework in Python code, Java, Scala, a multi-paradigm, high-level programming language and C or C++. The post Big Data Skill sets that Software Developers will Need in 2020 appeared first on SmartData Collective. Programming Language.
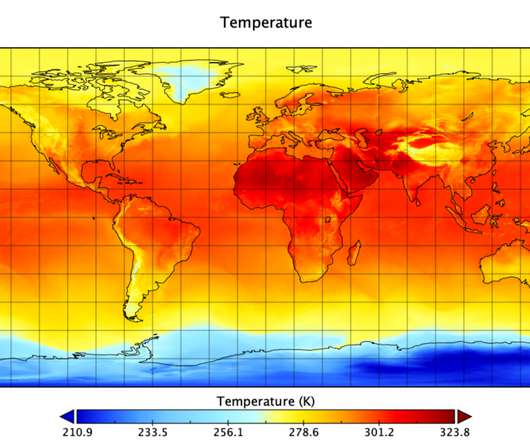
Temperature observation at 1pm UTC on June 15, 2020 Wind speed observation at 1pm UTC on June 15, 2020 Data usage Most of our clients use weather data as a variable in their linear regression model and other machine learning models. The python script below reads hourly files and reorganizes data into monthly files.
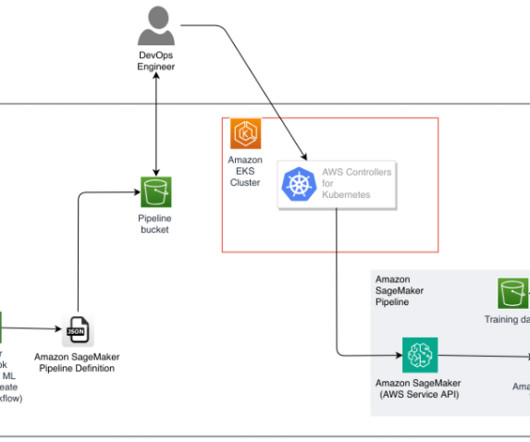
ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. Prerequisites To follow along, you should have the following prerequisites: An EKS cluster where the ML pipeline will be created. kubectl for working with Kubernetes clusters.
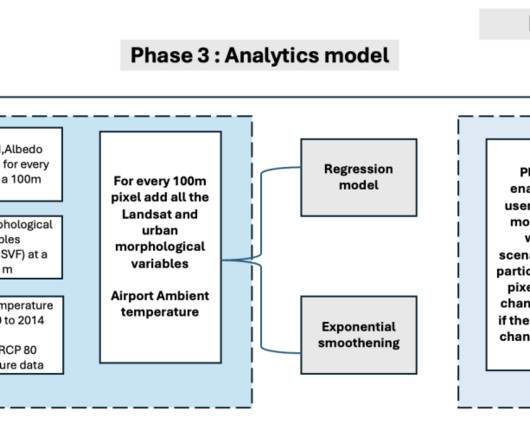
A grid system is established with a 48-meter grid size using Mapbox’s Supermercado Python library at zoom level 19, enabling precise spatial analysis. Among these models, the spatial fixed effect model yielded the highest mean R-squared value, particularly for the timeframe spanning 2014 to 2020.
You can deploy and use the Falcon LLMs with a few clicks in SageMaker Studio or programmatically through the SageMaker Python SDK. In early 2020, research organizations across the world set the emphasis on model size, observing that accuracy correlated with number of parameters. 24xlarge instances, cumulating in 384 NVIDIA A100 GPUs.
Memory-safe languages like Java and Python automate allocating and deallocating memory, though there are still ways to work around the languages’ built-in protections. In 2022, security wasn’t in the news as often as it was in 2020 and 2021. C and C++ still require programmers to do much of their own memory management.
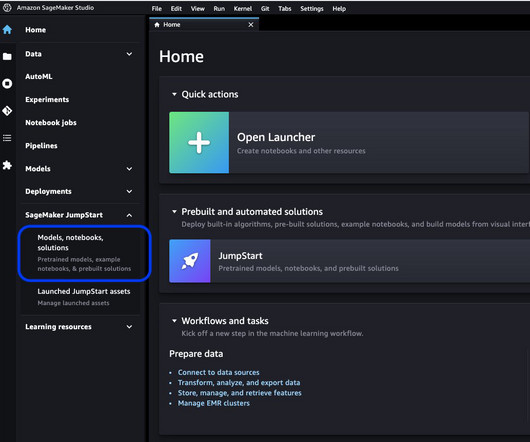
You can also access JumpStart models using the SageMaker Python SDK. The AWS CDK is an open-source software development framework to define your cloud application resources using familiar programming languages like Python. Prerequisites You must have the following prerequisites: An AWS account The AWS CLI v2 Python 3.6
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
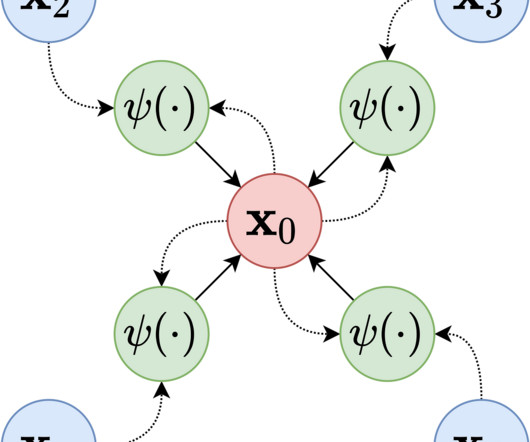
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We package this code into Python scripts that are provided to the SageMaker Processing Job via a custom container.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
One very simple example (introduced in 2015) is Nothing : Another, introduced in 2020, is Splice : An old chestnut of Wolfram Language design concerns the way infinite evaluation loops are handled. but with things like clustering). There’s one setup for interpreted languages like Python. Let’s start with Python.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. He currently is working on Generative AI for data integration.
In particular, my code is based on rospy, which, as you might guess, is a python package allowing you to write code to interact with ROS. It turned out that a better solution was to annotate data by using a clustering algorithm, in particular, I chose the popular K-means. I then trained the SVM on this dataset. in both metrics.
Image by Author Large Language Models (LLMs) entered the spotlight with the release of OpenAI’s GPT-3 in 2020. Python : Great for including AI in Python-based software or data pipelines. LangChain is provided in two programming languages: Python and JavaScript. models by OpenAI. What Does LangChain Address?
For instance, you could extract a few noisy metrics, such as a general “positivity” sentiment score that you track in a dashboard, while you also produce more nuanced clustering of the posts which are reviewed periodically in more detail. You might want to view the data in a variety of ways. The results in Section 3.7,
Develop Programming Skills Master programming languages such as Python, R, or Java, which are widely used in AI development. Explore topics such as regression, classification, clustering, neural networks, and natural language processing. billion in 2020. Moreover, the AI market in India is projected to grow at a CAGR of 20.2%
With SageMaker Processing, you can run a long-running job with a proper compute without setting up any compute cluster and storage and without needing to shut down the cluster. Data is automatically saved to a specified S3 bucket location. that runs run_alphafold.py
In May 2020, researchers in their paper “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” explored models which combine pre-trained parametric and non-parametric memory for language generation. Code in python, java etc. In majority of the use-case, these costs are prohibitive. Data in json, csv etc.
A myriad of instruction tuning research has been performed since 2020, producing a collection of various tasks, templates, and methods. SageMaker Python SDK Finally, you can programmatically deploy an endpoint through the SageMaker SDK. You can choose a Flan-T5 model card to deploy a model endpoint through the user interface.
Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK. All the steps in this demo are available in the accompanying notebook Fine-tuning text generation GPT-J 6B model on a domain specific dataset.
Like most of the world, I spent even more time indoors in 2020 than I usually do. Or cluster them first, and see if the clustering ends up being useful to determine who to assign a ticket to? You know all about LDA and topic modeling , so you go ahead and create the clusters easily.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., We implemented the MBD approach using the Python programming language, with the scikit-learn and NetworkX libraries for feature selection and structure learning, respectively.
We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR. This is the example from California from 2020. Python train.py, and give it the path to all your images. So here’s this example. We have this tile of a satellite.
We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR. This is the example from California from 2020. Python train.py, and give it the path to all your images. So here’s this example. We have this tile of a satellite.
Clustering health aspects ? We can package the pipeline via spacy package and install it with pip to use it directly in python ?. Clustering health aspects Health aspects can have many synonyms or similar contexts such as: ” sore throat ”, ” itchy throat ”, or ” swollen throat ”. Section 2: Understanding the problem 4.3
Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK. All the steps in this demo are available in the accompanying notebook Fine-tuning text generation GPT-J 6B model on a domain specific dataset.
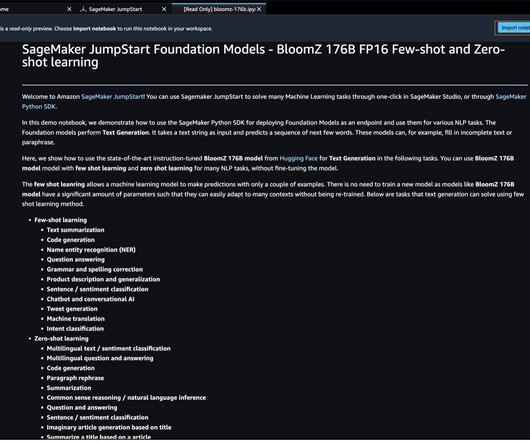
In this post and accompanying notebook, we demonstrate how to deploy the BloomZ 176B foundation model using the SageMaker Python simplified SDK in Amazon SageMaker JumpStart as an endpoint and use it for various natural language processing (NLP) tasks. You can also access the foundation models thru Amazon SageMaker Studio.
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well. data # Assing local directory path to a python variable local_data_path = "./data/" This was created in Step-2 above.
Redmon and Farhadi (2017) published YOLOv2 at the CVPR Conference and improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters. One good news is that YOLOv8 has a command line interface, so you do not need to run Python training and testing scripts. Python-3.9.16 torch-1.13.1+cu116
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




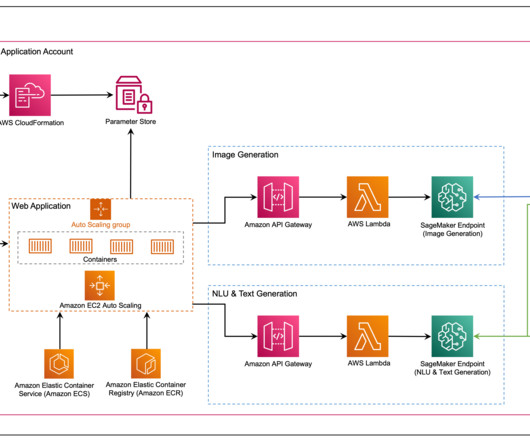





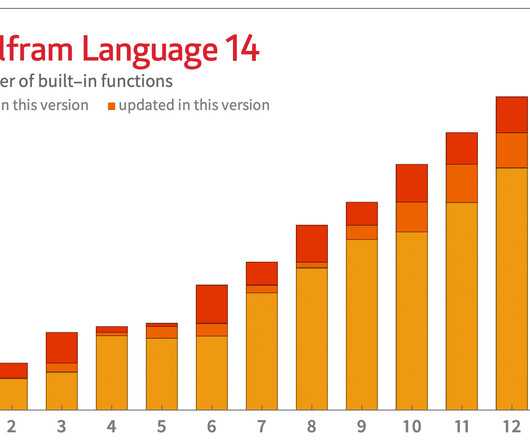





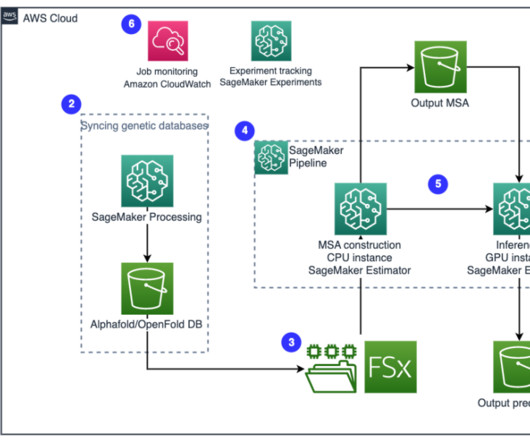


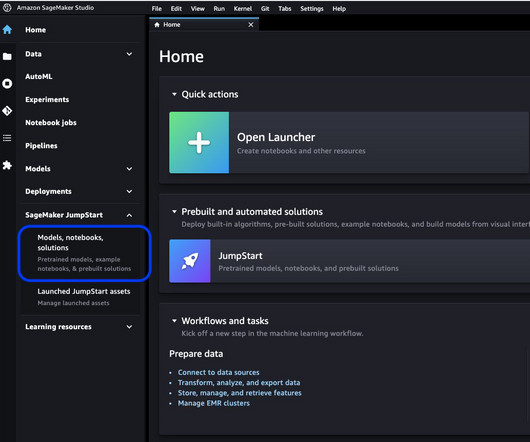












Let's personalize your content