This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Team Building the right datascience team is complex. Download the free, unabridged version here.
They’re looking to hire experienced data analysts, data scientists and data engineers. With big data careers in high demand, the required skillsets will include: Apache Hadoop. Software businesses are using Hadoop clusters on a more regular basis now. Other coursework.
Yes, data created over the next three years will far exceed the amount created over the past 30 years ( Source : IDC Worldwide Global DataSphere Forecast, 2020-2024). This explains why pressure on DataScience teams is growing every day. Can I put all my data into one project without over-engineering?
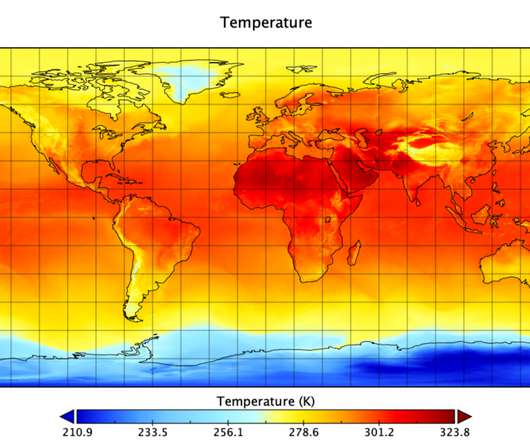
The plots below are created from 33,554,432 data points like a picture on an 8K TV screen is created from pixels. Therefore, in most cases they are interested in historical data for a specific location. So, instead of storing data by hours, the data will be stored by months and spatially partitioned.
Detecting drought in January 2020 (on the left) using the EVI vegetation index Yellow means very healthy vegetation while dark green means unhealthy. In the context of Sentinel-2 data, K-means facilitates the grouping of similar pixels according to their spectral characteristics and EVI values.
sThe recent years have seen a tremendous surge in data generation levels , characterized by the dramatic digital transformation occurring in myriad enterprises across the industrial landscape. The amount of data being generated globally is increasing at rapid rates. Big data and data warehousing.
There were 4 clusters of users that this report broke down to understand the behavior and tendencies of different users. Cluster 2 : Swap Count : Extremely High (around 54,127 swaps on average) Volume in USD : Extremely High (around $4.43 Cluster 3 : Swap Count : Low (around 10 swaps on average) Volume in USD : Moderate (around $60.25
In this blog, we’ll explain what makes up the Snowflake Data Cloud, how some of the key components work, and finally some estimates on how much it will cost your business to utilize Snowflake. What is the Snowflake Data Cloud?
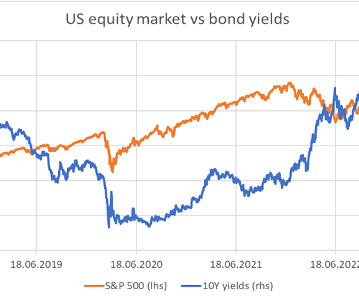
For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes. Originally posted on OpenDataScience.com Read more datascience articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels!
If you’re training one model, you’re probably training a dozen — hyperparameter optimization, multi-user clusters, & iterative exploration all motivate multi-model training, blowing up compute demands further still. Industry clusters receive jobs from hundreds of users & pipelines. Second, resource apportioning.
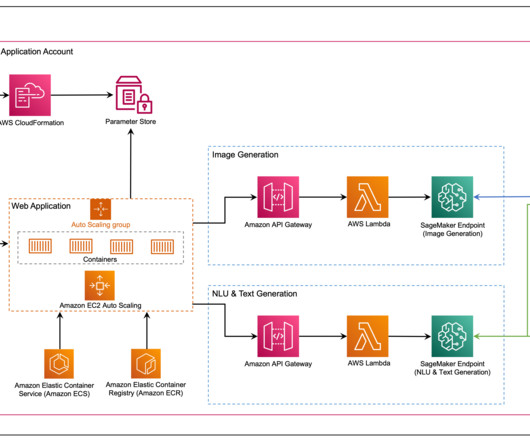
Solution overview The web application is built on Streamlit , an open-source Python library that makes it easy to create and share beautiful, custom web apps for ML and datascience. Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines.
The model is trained on gameplay data from Bleeding Edge, a 2020 multiplayer game developed by NinjaTheory. Its been amazing to see the variety of ways Microsoft Research has used the Bleeding Edge environment and data to explore novel techniques in a rapidly moving AI industry , said Gavin Costello, Technical Director at NinjaTheory.
Feature engineering Game tracking data is captured at 10 frames per second, including the player location, speed, acceleration, and orientation. Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation.
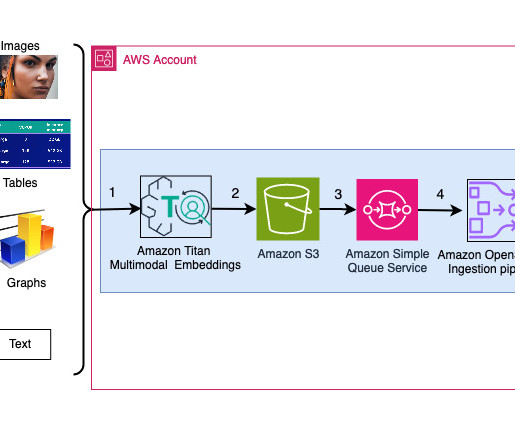
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. Each node processes a subset of the files and this brings down the overall time required to ingest the data into OpenSearch Service.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
It turned out that a better solution was to annotate data by using a clustering algorithm, in particular, I chose the popular K-means. This means that it can infer knowledge from data without a supervised signal (i.e. So I simply run the K-means on the whole dataset, partitioning it into 4 different clusters. Handel, J.
Union of business and data teams The success of ML projects lies in the strong collaboration between the data team and the business team. Such continuous alliance of the business team helps the datascience team to create ML models that have the potential to add significant business value.
Explore topics such as regression, classification, clustering, neural networks, and natural language processing. There are several online platforms offering courses in artificial intelligence, datascience, machine learning and others. billion in 2020. to reach US$ 7.8 billion by 2025 from US$ 3.1 Moreover, pickle.AI
Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. He currently is working on Generative AI for data integration.
You might want to view the data in a variety of ways. For instance, you could extract a few noisy metrics, such as a general “positivity” sentiment score that you track in a dashboard, while you also produce more nuanced clustering of the posts which are reviewed periodically in more detail. The results in Section 3.7,
We get the following response: """For model: huggingface-text2text-flan-t5-xxl, the generated output is: the Managed Spot Training is a subscriptions product available for the following instances: DataScience Virtual Machine (DSVM), DSVM High, and DSVM Low. """ As you can see, the response is not accurate.
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and Data Pipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Data Summarization : LangChain can create applications that summarize long documents.
Image Source: NVIDIA A100 — The Revolution in High-Performance Computing The A100 is the pioneer of NVIDIA’s Ampere architecture and emerged as a GPU that redefined computing capability when it was introduced in the first half of 2020. Similarly, the number of GPUs needed depends on the data type, size, and models used.
Finally, monitor and track the FL model training progression across different nodes in the cluster using the weights and biases (wandb) tool, as shown in the following screenshot. 2020): e0235424. Please follow the steps listed here to install wandb and setup monitoring for this solution. ACM Computing Surveys (CSUR) , 54 (6), pp.1-36.
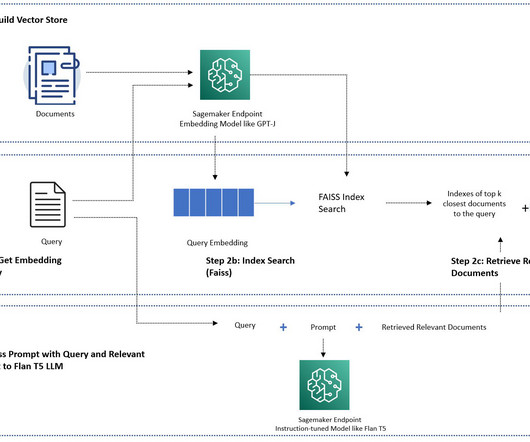
In May 2020, researchers in their paper “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” explored models which combine pre-trained parametric and non-parametric memory for language generation. In majority of the use-case, these costs are prohibitive. However, now they recommend ada v2 for all tasks.
What’s really important in the before part is having production-grade machine learning data pipelines that can feed your model training and inference processes. And that’s really key for taking datascience experiments into production. And so that’s where we got started as a cloud data warehouse.
What’s really important in the before part is having production-grade machine learning data pipelines that can feed your model training and inference processes. And that’s really key for taking datascience experiments into production. And so that’s where we got started as a cloud data warehouse.
Both types of computing can be done without a data center, but it would require specialized equipment and a significant investment. For HPC, it’s possible to use a cluster of powerful workstations or servers, each with multiple processors and large amounts of memory.
These algorithms help legal professionals swiftly discover essential information, speed up document review, and assure comprehensive case analysis through approaches such as document clustering and topic modeling. Here are some resources for more information: Hutchinson, T. Records Management Journal , 30 (2), 155–174.
c/o Ernst & Young LLPSeattle, Washington Attention: Corporate Secretary (2) For the purpose of Article III of the Securities Exchange Act of 1934, the registrant’s name and address are as follows:(3) The registrant’s Exchange Act reportable time period is from and includingJanuary 1, 2020 to the present.(4)
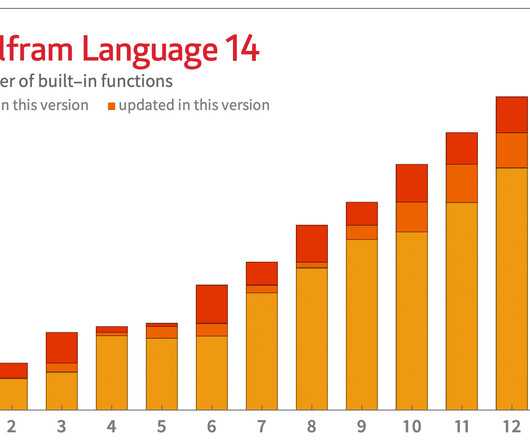
One very simple example (introduced in 2015) is Nothing : Another, introduced in 2020, is Splice : An old chestnut of Wolfram Language design concerns the way infinite evaluation loops are handled. but with things like clustering). And in Version 13.2 But 35 years later we routinely deal with gigabytes.
We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR. This is the example from California from 2020. So now that we have the data, we now do what we’ve talked about, the theory: self-supervised learning.
We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR. This is the example from California from 2020. So now that we have the data, we now do what we’ve talked about, the theory: self-supervised learning.
c/o Ernst & Young LLPSeattle, Washington Attention: Corporate Secretary (2) For the purpose of Article III of the Securities Exchange Act of 1934, the registrant’s name and address are as follows:(3) The registrant’s Exchange Act reportable time period is from and includingJanuary 1, 2020 to the present.(4)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content