This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
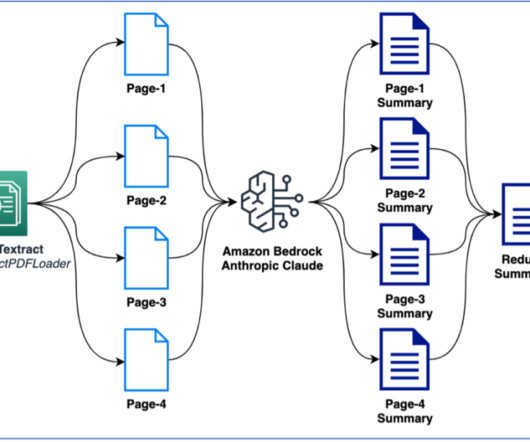
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Amazon Redshift is a database optimized for online analytical processing (OLAP), which generally entails analyzing large amounts of data and performing complex analysis, as might be done by analysts looking at historical stock prices. The first trial ran from June 2019 to May 2020 with 250 participants. June 2019 - May 2020 2.
billion on compliance in 2022 (up 19% from 2020) — costs that continue to rise despite limited improvements in effectiveness [3]. Just as a judge relies on a clerk to pull specific case files before making a decision, an LLM with RAG can query databases or documents in real time to support its compliance decisions.
This involved creating a pipeline for data ingestion, preprocessing, metadata extraction, and indexing in a vector database. Similarity search and retrieval – The system retrieves the most relevant chunks in the vector database based on similarity scores to the query.
Blog People Keep Inventing Prolly Trees Nick Tobey June 4, 2025 9 min read Multiple Discovery refers to when a scientific discovery is made independently by multiple individuals around the same time. But we did see the value in using them to build the worlds first version controlled relational database. But Paul Frazee has a theory.
Early 2020, with the push for deep learning and transformer models, Qualtrics created its first enterprise-level ML platform called Socrates. To learn more about how AI is transforming experience management, visit this blog from Qualtrics.
In this blog, we will cover how to use maps in Sigma Computing. 1) Map - Region Click on the Data pane then Table to select the Tables and Datasets option and from there, under connections, we can select Sigma sample database. Sigma offers powerful mapping capabilities that allow users to visualize geographic data effectively.
I'm JD, a Software Engineer with experience touching many parts of the stack (frontend, backend, databases, data & ETL pipelines, you name it). Also, I have two 0days and received CVEs under my name and a company research blog post to go along with it. Email: hoglan (dot) jd (at) gmail Hello! Email: tom@devsoft.co.za
Zhong, “Theseus: an Experiment in Operating System Structure and State Management,” in 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), USENIX Association, 2020, pp. Available: [link] www.usenix.org/conference/osdi20/presentation/boos [7] V. Narayanan et al., Available: [link] [8] Synopsys, Inc., “The
in 2020 , RAG has become the go-to technique for incorporating external knowledge into the LLM pipeline. The retriever pulls the documents most relevant to the query from a collection of embedded documents stored in a vector database. The knowledge base is made up of documents embedded and stored in a vector database.
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
Home Table of Contents Build a Search Engine: Deploy Models and Index Data in AWS OpenSearch Introduction What Will We Do in This Blog? What Will We Do in This Blog? By the end of this guide, you will have a fully indexed movie dataset with embeddings, ready for semantic search in the next blog. What’s Coming Next?
Thanks to the help of X41 D-Sec , GitLab , and the Sovereign Tech Agency , Rails can provide more secure versions of the tools needed for users to create database-backed web applications following the Model-View-Controller pattern. Ruby on Rails (or “Rails”) is an open source full stack web-application framework.
Hardy AstroBetter Astrobiology Magazine Astrobites Astrometry.net Astronautics Now Astronomical Journal Astronomy & Astrophysics Astronomy Picture of the Day Astrophysical Journal Beyond NERVA British Interplanetary Society Bulletin of the American Astronomical Society Cosmic Ancestry Division for Planetary Sciences European Federation of Biophysics (..)
Gergely Orosz , creator of The Pragmatic Engineer newsletter, mentioned in a blog post that software engineering job openings have hit a five-year low globally, with a 35% decrease in vacancies compared to January 2020. Recently, he said that 90% of what programmers write today is ‘boilerplate’. According to Indeed data, there are 3.5
We are also hiring for other engineering and growth roles - https://supabase.com/careers reply manish_gill 9 hours ago | prev | next [–] ClickHouse | Senior Software Engineer - Cloud Infrastructure / Kubernetes | Remote (US / EU preferred) ClickHouse is a popular, Open-Source OLAP Database.
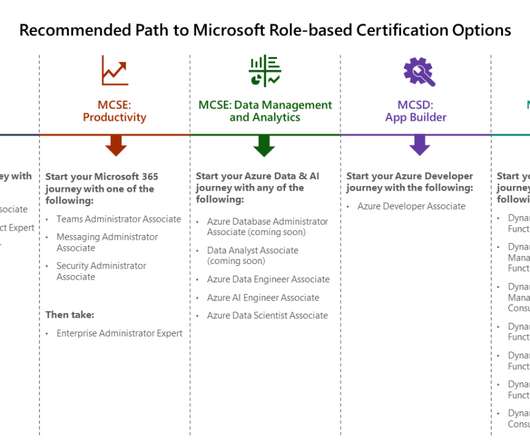
The following Microsoft certifications are set to retire in 2020. June 30, 2020 is the scheduled end date, so people are encouraged to pass the exams before that date. More details and questions and answers can be found at the bottom of the Microsoft retires certifications blog post. What to do now?
The Story of the Name Patrick Lewis, lead author of the 2020 paper that coined the term , apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI. Another great advantage of RAG is it’s relatively easy.
Can you believe we’re entering the 10th year of this blog series? You can find Mark on LinkedIn , Twitter , and on his Sons of Hierarchies blog. Jiselle Howe reflects on her 2020 experiences and learnings, plus shares her 2021 ambitions. You can also check out the blogs I follow here. January 20, 2021 - 10:39pm.
zettabytes more than in 2020. The post Not Every Database Is the Same: Graph vs. Relational appeared first on DATAVERSITY. Mirroring this sentiment, Statista predicts that data creation will grow to more than 180 zettabytes by 2025, which is about 118.8 This vast, and ever-increasing, volume […].
This is so that the output generated using the IDP workflow can be consumed into a downstream system, for example a relational database. For example, we can follow prompt engineering best practices to fine-tune an LLM to format dates into MM/DD/YYYY format, which may be compatible with a database DATE column.
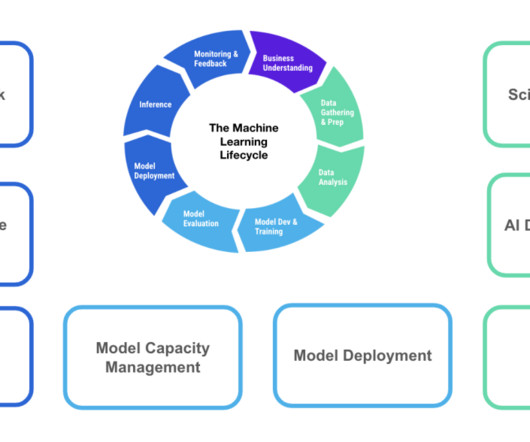
VC Investment in AI firms rose from USD 3 billion in 2012 to close to USD 75 billion in 2020 This trend led to the proliferation of companies developing tools to address different pain points in the machine learning lifecycle. While this investment has driven progress and innovation in the field, it has also given rise to a new problem.
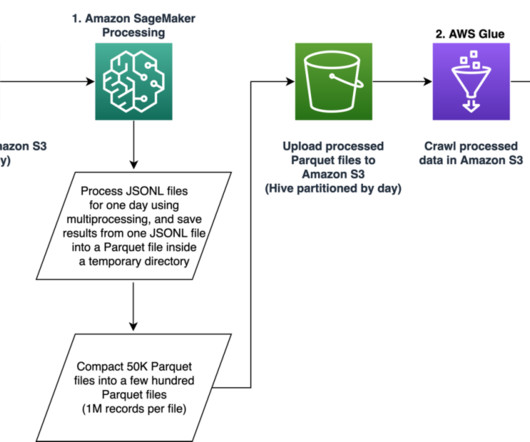
The following is the sample code to schedule a SageMaker Processing job for a specified day, for example 2020-01-01, using the SageMaker SDK. store_parquet_metadata( path='s3://bucket/processed/table-name/', database="database_name", table="table_name", dataset=True, mode="overwrite", sampling=1.0, session.Session().region_name
Under Vector database , select Quick create a new vector store. Using the specified chunking strategy, the knowledge base converts the documents in the S3 bucket to vector embeddings, which are stored in the default Amazon OpenSearch serverless vector database. What are the international operating expenses in 2020, 2021 and 2022?
When reflecting on 2020, the effects of COVID-19 have touched nearly every corner of the globe, spanning continents, age groups and industries. Click to learn more about author Samantha Humphries.
In May 2020, researchers in their paper “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” explored models which combine pre-trained parametric and non-parametric memory for language generation. Vectors are typically stored in Vector Databases which are best suited for searching. What is a Vector Database?
In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. for text in texts: text.metadata = {"audio_url": text.metadata["audio_url"]} Embed texts Next up we create embeddings for all of our texts and load them into a Chroma vector database.
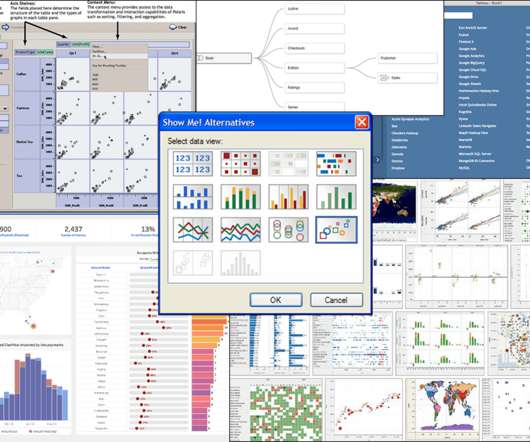
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. Query allowed customers from a broad range of industries to connect to clean useful data found in SQL and Cube databases.
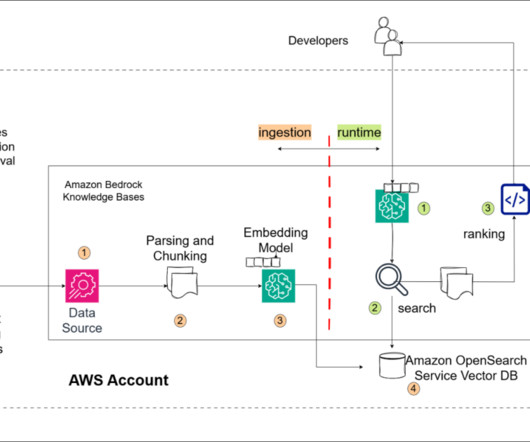
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. The document embeddings are split into chunks and stored as indexes in a vector database. We use the Amazon letters to shareholders dataset to develop this solution.
November 17, 2020 - 12:48am. December 15, 2020. Stay tuned for more details in a future blog post. We’re expanding Tableau’s spatial database connections to make solving location-based questions easier than ever. Emily Chen. Product Marketing Specialist, Tableau. Spencer Czapiewski. The newest release of Tableau is here!
To help data practitioners, this blog will cover eight of the top data versioning tools in the market. Best data version control tools for 2024 Now that you have a clear understanding of the expectations of the blog, let’s explore each one of them, starting with DagsHub. Why do we need to version our data?
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
Can you believe we’re entering the 10th year of this blog series? You can find Mark on LinkedIn , Twitter , and on his Sons of Hierarchies blog. Jiselle Howe reflects on her 2020 experiences and learnings, plus shares her 2021 ambitions. You can also check out the blogs I follow here. January 20, 2021 - 10:39pm.
Our analysis of the voluntarily reported Form FDA 1572 BMIS database reveals a potential lack of sustainability in the investigator pool, both in the United States (US) and globally (Exhibit 2). For instance, the FDA released guidance in November 2020 titled, “Enhancing the diversity of clinical trial populations.”
IBM and watsonx Assistant have been using foundation models since 2020 for advanced processing and understanding of text, including customer conversations. The post IBM watsonx Assistant transforms content into conversational answers with generative AI appeared first on IBM Blog.
During the Summer 2020 semester, Dr. Haigh utilized Alation to teach the first ‘Intro to Databases’ course. Subscribe to Alation's Blog. We collaborated on the design of the catalog for the classroom and crafted an educational plan that blended catalog features with learning materials for the students.
Dr. Shriram was selected for the Forbes 30 Under 30 2020 Class in the Gaming category. Their web application is developed using AWS Amplify. Shriram received her BA, MA, and PhD at the Stanford Virtual Human Interaction Lab. She previously worked at Google [x] and Meta’s Reality Labs.
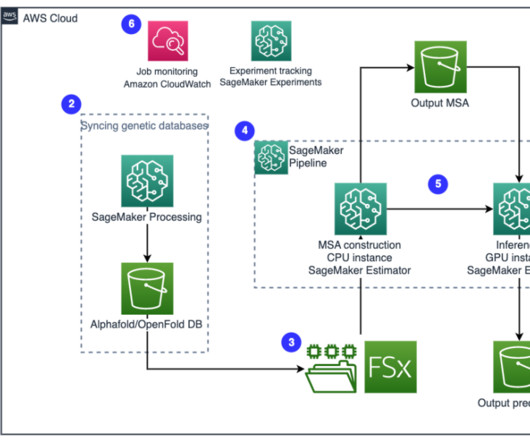
Genetic databases – A genetic database is one or more sets of genetic data stored together with software to enable users to retrieve genetic data. Several genetic databases are required to run AlphaFold and OpenFold algorithms, such as BFD , MGnify , PDB70 , PDB , PDB seqres , UniRef30 (FKA UniClust30) , UniProt , and UniRef90.
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
March, 2020: Gartner names Alation a 2020 Gartner Peer Insights Customers’ Choice for Metadata Management Solutions. June 2020: Dresner Advisory Services names Alation the #1 data catalog in its Data Catalog End-User Market Study for the 4th time. Subscribe to Alation's Blog. What do we mean by everything ?
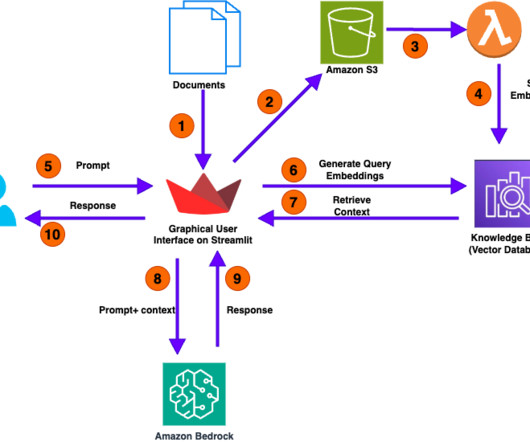
In the RAG-based approach we convert the user question into vector embeddings using an LLM and then do a similarity search for these embeddings in a pre-populated vector database holding the embeddings for the enterprise knowledge corpus. Select the notebook aws-llm-apps-blog and choose Open JupyterLab.
This blog post is co-written with Chaoyang He and Salman Avestimehr from FedML. This dataset comprises a multi-center critical care database collected from over 200 hospitals, which makes it ideal to test our FL experiments. It is available as a set of CSV files, which can be loaded into any relational database system.
This blog post is co-written with Chaoyang He and Salman Avestimehr from FedML. In the second post , we present the use cases and dataset to show its effectiveness in analyzing real-world healthcare datasets, such as the eICU data , which comprises a multi-center critical care database collected from over 200 hospitals. Background.
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. Query allowed customers from a broad range of industries to connect to clean useful data found in SQL and Cube databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content