This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Under Settings , enter a name for your database cluster identifier. You can verify the output by cross-referencing the PDF, which has a target as $12 million for the in-store sales channel in 2020. Delete the Aurora MySQL instance and Aurora cluster. Choose Create database. Select Aurora , then Aurora (MySQL compatible).
Within a year, we built a world-class inference platform processing over 2 billion video frames daily using dynamically scaled Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Despite this, exciting events like the AWS DeepRacer F1 Pro-Am kept the community engaged.
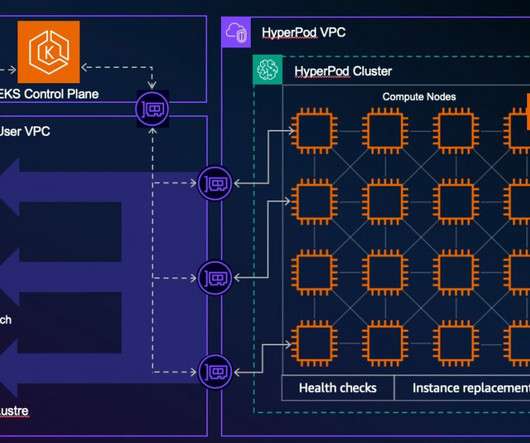
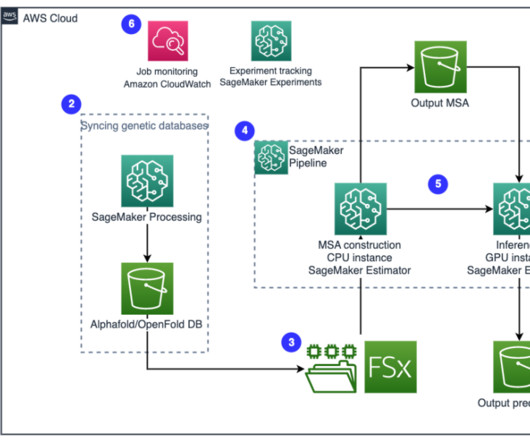
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
I have about 3 YoE training PyTorch models on HPC clusters and 1 YoE optimizing PyTorch models, including with custom CUDA kernels. Also, I have two 0days and received CVEs under my name and a company research blog post to go along with it. I currently work at a public HPC center, where I am also doing a PhD. Email: tom@devsoft.co.za
Home Table of Contents Build a Search Engine: Deploy Models and Index Data in AWS OpenSearch Introduction What Will We Do in This Blog? What Will We Do in This Blog? By the end of this guide, you will have a fully indexed movie dataset with embeddings, ready for semantic search in the next blog. What’s Coming Next?
Follow with RSS or E-Mail Follow by E-Mail Get new posts by email: Advanced Propulsion Research Exoplanet Projects (Earth) AFOE Amateur Exoplanet Archive Anglo-Australian Planet Search APACHE Project ASTEP: Antarctic Search for Transiting Extrasolar Planets ASTRA Astro Gregas Atacama Large Millimetre Array Automated Planet Finder Berlin Exoplanet Search (..)
It seems like that's not the main focus of your org, but I was pleased to see a reference to RCV in your blog: [0] [0]: https://goodparty.org/blog/article/final-five-voting-explain. reply bravesoul2 3 hours ago | root | parent | next [–] I live in Australia and we have preferential voting.
You can also read this article on Kablamo Engineering Blog. Detecting drought in January 2020 (on the left) using the EVI vegetation index Yellow means very healthy vegetation while dark green means unhealthy. K-means is basically like sorting colored balls into groups by finding their average colors.
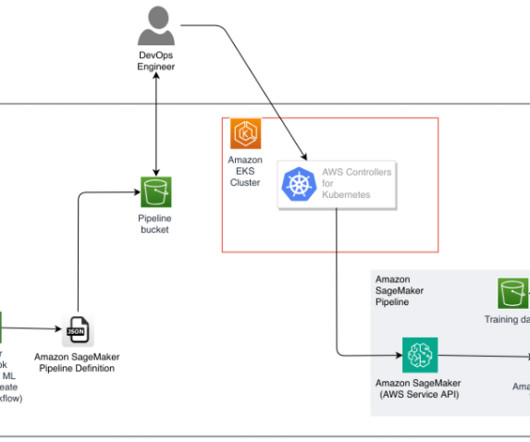
ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. Prerequisites To follow along, you should have the following prerequisites: An EKS cluster where the ML pipeline will be created. kubectl for working with Kubernetes clusters.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Aligning SMP with open source PyTorch Since its launch in 2020, SMP has enabled high-performance, large-scale training on SageMaker compute instances. To mitigate this problem, SMP v2.0
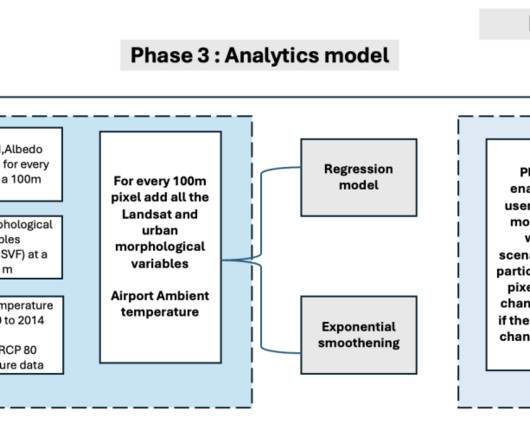
Among these models, the spatial fixed effect model yielded the highest mean R-squared value, particularly for the timeframe spanning 2014 to 2020. SageMaker Processing enables the flexible scaling of compute clusters to accommodate tasks of varying sizes, from processing a single city block to managing planetary-scale workloads.
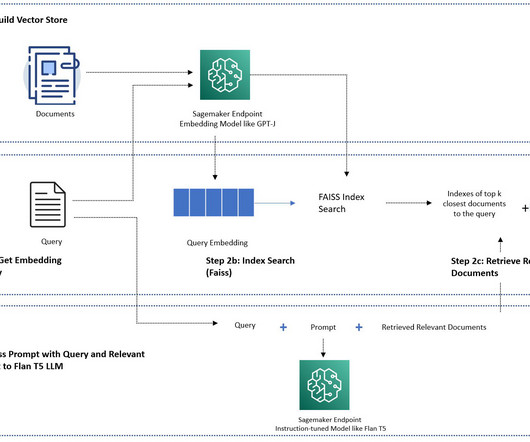
The Story of the Name Patrick Lewis, lead author of the 2020 paper that coined the term , apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI. Another great advantage of RAG is it’s relatively easy.
With Amazon EKS support in SageMaker HyperPod you can orchestrate your HyperPod Clusters with EKS. With the new deployment capabilities, customers can now leverage HyperPod clusters across the full generative AI development lifecycle from model training and tuning to deployment and scaling. Laurent Sifre, Co-founder & CTO, H.AI
Keep in mind that big data drives search engines in 2020. It’s a bad idea to link from the same domain, or the same cluster of domains repeatedly. Your link should be contextually relevant to the blog; in other words, it shouldn’t stand out as promotional. Big data is critical for linkbuilding in 2020.
This blog post is co-written with Dr. Ebtesam Almazrouei, Executive Director–Acting Chief AI Researcher of the AI-Cross Center Unit and Project Lead for LLM Projects at TII. In early 2020, research organizations across the world set the emphasis on model size, observing that accuracy correlated with number of parameters.
Businesses today rely on real-time big data analytics to handle the vast and complex clusters of datasets. From 2010 to 2020, there has been a 5000% growth in the quantity of data created, captured, and […] Here’s the state of big data today: The forecasted market value of big data will reach $650 billion by 2029.
Since 2020, Ubotica has been providing space AI capabilities to the European Space Agency and NASA JPL. The initial install is a Red Hat OpenShift Kubernetes Service (ROKS) cluster , on which Ubotica will be deploying components to create a hybrid cloud AI platform.
This blog was originally written by Keith Smith and updated for 2024 by Justin Delisi. In this blog, we’ll explain what makes up the Snowflake Data Cloud, how some of the key components work, and finally some estimates on how much it will cost your business to utilize Snowflake. What is the Snowflake Data Cloud?
The blog post “ How to use VPN with a VPC hub-and-spoke architecture ” describes the project. Dimitri Blog posts – In Adding Instance Storage to an Existing VPC VSI , I describe the process I took to update an existing virtual server instance (VSI) and add instance storage to it. Security-wise, there was much more.
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. Select the notebook aws-llm-apps-blog and choose Open JupyterLab. RAG models were introduced by Lewis et al.
For further details please reference our blog on how to evaluate speech recognition models. Building on In-House Hardware Conformer-2 was trained on our own GPU compute cluster of 80GB-A100s. PPNER measures a model’s performance specifically for proper nouns, by using a character-based metric called Jaro-Winkler similarity.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition.
Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines. On the Amazon ECS console, you can see the clusters on the Clusters page. Model data is stored on Amazon Simple Storage Service (Amazon S3) in the JumpStart account. for the full code.
Since its launch in 2020, DATA ONE has been successfully adopted by multinational companies across sectors, including insurance and banking, automotive, energy and utilities, manufacturing, logistics and telco. Nodes are grouped together in homogeneous clusters, but different clusters can be optimized for different types of workloads.
For a given frame, our features are inspired by the 2020 Big Data Bowl Kaggle Zoo solution ( Gordeev et al. ): we construct an image for each time step with the defensive players at the rows and offensive players at the columns. He started at the NFL in February 2020 as a Data Scientist and was promoted to his current role in December 2021.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN.
Fight sophisticated cyber attacks with AI and ML When “virtual” became the standard medium in early 2020 for business communications from board meetings to office happy hours, companies like Zoom found themselves hot in demand. They also became prime targets for the next big cyberattack.
If you’re training one model, you’re probably training a dozen — hyperparameter optimization, multi-user clusters, & iterative exploration all motivate multi-model training, blowing up compute demands further still. Industry clusters receive jobs from hundreds of users & pipelines. Second, resource apportioning.
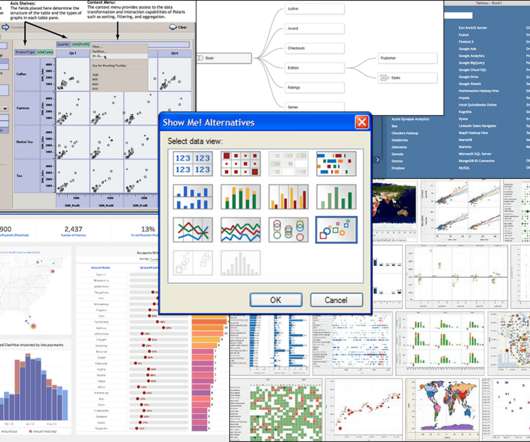
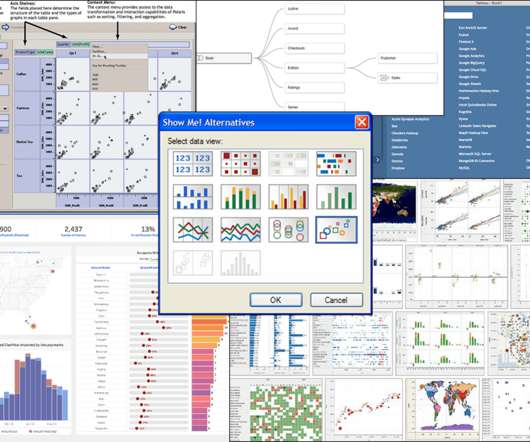
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance.
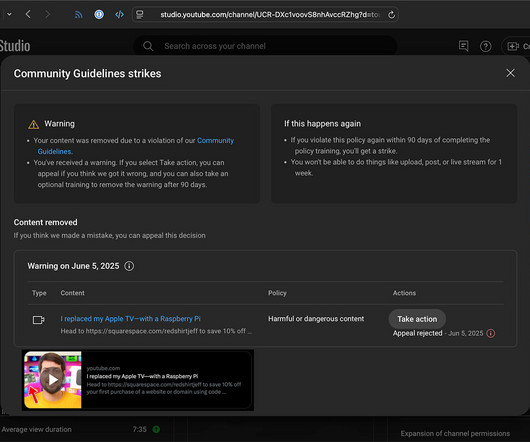
Skip to main content Jeff Geerling Main menu Merch About Blog Projects Self-hosting your own media considered harmful June 5, 2025 I just received my second community guidelines violation for my video demonstrating the use of LibreELEC on a Raspberry Pi 5, for 4K video playback.
Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. But the issue we found was that MP is efficient in single-node clusters, but in a multi-node setting, the inference isn’t efficient. 2020 or Hoffman et al., 2020 or Hoffman et al.,
In this blog, we will unfold the benefits of Power BI and key Power BI features , along with other details. In 2020, manufacturing companies majorly adopted the BI tools Key Power BI Features So, what are the key features of Power BI that make it a useful tool for businesses across different industrial spectrums? What is Power BI?
In this blog post, we will dive deeper into the Netflix movies and series recommendation systems ( Figure 1 ). Figure 2: Multi-dimensionality of Netflix recommendation system (source: Basilico, “Recent Trends in Personalization at Netflix,” NeurIPS , 2020 ). And it goes on to personalize title images, trailers, metadata, synopsis, etc.
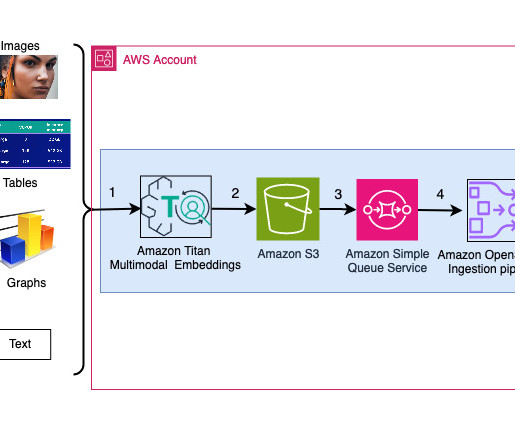
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
In May 2020, researchers in their paper “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” explored models which combine pre-trained parametric and non-parametric memory for language generation. In majority of the use-case, these costs are prohibitive. It is generally considered an offline process.
When AWS launched purpose-built accelerators with the first release of AWS Inferentia in 2020, the M5 team quickly began to utilize them to more efficiently deploy production workloads , saving both cost and reducing latency. Like many ML organizations, accelerators are largely used to accelerate DL training and inference.
This blog will briefly introduce and compare the A100, H100, and H200 GPUs. Image Source: NVIDIA A100 — The Revolution in High-Performance Computing The A100 is the pioneer of NVIDIA’s Ampere architecture and emerged as a GPU that redefined computing capability when it was introduced in the first half of 2020. How Many Are Needed?
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance.
This blog post is co-written with Chaoyang He and Salman Avestimehr from FedML. Finally, monitor and track the FL model training progression across different nodes in the cluster using the weights and biases (wandb) tool, as shown in the following screenshot. 2020): e0235424. ACM Computing Surveys (CSUR) , 54 (6), pp.1-36.
With SageMaker Processing, you can run a long-running job with a proper compute without setting up any compute cluster and storage and without needing to shut down the cluster. Data is automatically saved to a specified S3 bucket location.
For instance, you could extract a few noisy metrics, such as a general “positivity” sentiment score that you track in a dashboard, while you also produce more nuanced clustering of the posts which are reviewed periodically in more detail. You might want to view the data in a variety of ways. The results in Section 3.7,
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. RAG retrieves data from outside the language model (non-parametric) and augments the prompts by adding the relevant retrieved data in context.
Image by Author Large Language Models (LLMs) entered the spotlight with the release of OpenAI’s GPT-3 in 2020. Document Retrieval and Clustering: LangChain can simplify retrieval and clustering using embedding models. We have seen exploding interest in LLMs and in a broader discipline, Generative AI. models by OpenAI.
A myriad of instruction tuning research has been performed since 2020, producing a collection of various tasks, templates, and methods. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content