This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Also: Introduction to NaturalLanguageProcessing (NLP); Anomaly Detection, A Key Task for AI and Machine Learning, Explained; How to Become a (Good) DataScientist — Beginner Guide.
Also: Activation maps for deep learning models in a few lines of code; The 4 Quadrants of Data Science Skills and 7 Principles for Creating a Viral Data Visualization; OpenAI Tried to Train AI Agents to Play Hide-And-Seek but Instead They Were Shocked by What They Learned; 10 Great Python Resources for Aspiring DataScientists.
This week, find out what the future of analytics and data science holds; get an introduction to spaCy for naturallanguageprocessing; find out how to use time series analysis for baseball; get to know your data; read 6 bits of advice for datascientists; and much, much more!
Also: 12 things I wish I'd known before starting as a DataScientist; 10 Free Top Notch NaturalLanguageProcessing Courses; The Last SQL Guide for Data Analysis; The 4 Quadrants of #DataScience Skills and 7 Principles for Creating a Viral DataViz.
Building bridges : Think of a young developer who attended an AI conference back in 2019. The speaker is Andrew Madson, a data analytics leader and educator. The event is for anyone interested in learning about generative AI and data storytelling, including business leaders, datascientists, and enthusiasts.
Fastweb , one of Italys leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019. With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties.
Their applications range from utilizing video, audio, and behavioral data to better understand the connection between patients, disease, and treatment, to improving diagnostics for lung cancer, providing voice-powered care assistance, and creating accessible and affordable health systems through naturallanguageprocessing (NLP) and AI.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses naturallanguageprocessing (NLP) techniques to extract valuable insights from textual data.
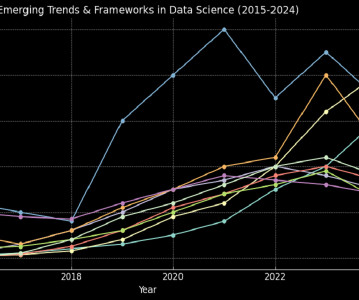
The Early Years: Laying the Foundations (20152017) In the early years, data science conferences predominantly focused on foundational topics like data analytics , visualization , and the rise of big data. The Deep Learning Boom (20182019) Between 2018 and 2019, deep learning dominated the conference landscape.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
Srinivas Alva is a DataScientist at ZS Associates, specializing in the transformation of high-grade research into commercial solutions. degree in AI and ML specialization from Gujarat University, earned in 2019. His expertise and experience make him a valuable asset in the field of data science and Generative AI.
2019 Apr;179(4):561-569. Epub 2019 Jan 31. DataScientist with 8+ years of experience in Data Science and Machine Learning. Factors affecting quality of life in children and adolescents with hypermobile Ehlers-Danlos syndrome/hypermobility spectrum disorders. Am J Med Genet A. doi: 10.1002/ajmg.a.61055.
Image from Hugging Face Hub Introduction Most naturallanguageprocessing models are built to address a particular problem, such as responding to inquiries regarding a specific area. This restricts the applicability of models for understanding human language. Alex Warstadt et al. print("1-",qqp["train"].homepage)
AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the data science community. The bertweet-base-hate model also uses the base BertTweet FM but is further pre-trained on 19,600 tweets that were deemed as hate speech 8 (Basile 2019).
This is a guest post co-authored with Ville Tuulos (Co-founder and CEO) and Eddie Mattia (DataScientist) of Outerbounds. Historically, naturallanguageprocessing (NLP) would be a primary research and development expense.
“Data locked away in text, audio, social media, and other unstructured sources can be a competitive advantage for firms that figure out how to use it“ Only 18% of organizations in a 2019 survey by Deloitte reported being able to take advantage of unstructured data. The majority of data, between 80% and 90%, is unstructured data.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervised learning. This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
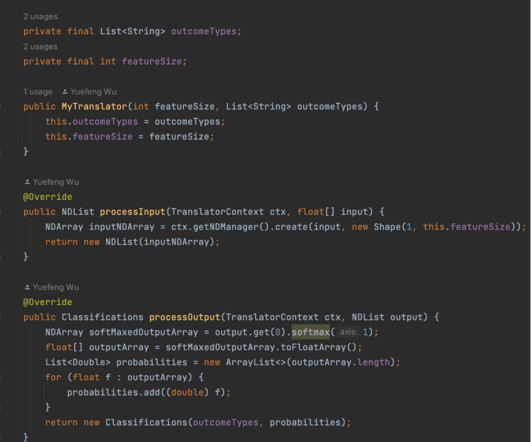
Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. The steps are as follows: Training the models – Our datascientists train the models using PyTorch and save the models as torch scripts. The DJL was created at Amazon and open-sourced in 2019.
chief datascientist, a role he held under President Barack Obama from 2015 to 2017. Bush, and has co-authored several books on data science. He leads corporate strategy for machine learning, naturallanguageprocessing, information retrieval, and alternative data. Patil served as the first U.S.
chief datascientist, a role he held under President Barack Obama from 2015 to 2017. Bush, and has co-authored several books on data science. He leads corporate strategy for machine learning, naturallanguageprocessing, information retrieval, and alternative data. Patil served as the first U.S.
In recent years, researchers have also explored using GCNs for naturallanguageprocessing (NLP) tasks, such as text classification , sentiment analysis , and entity recognition. GCNs use a combination of graph-based representations and convolutional neural networks to analyze large amounts of textual data. Richong, Z.,
Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. First, we trained a new sense2vec model on the 2019 Reddit comments , which makes for an interesting contrast to the previous 2015 vectors. In 2019, it’s mostly used in the context of cutting off communication by “ghosting”.
Advances in neural information processing systems 32 (2019). Visualizing data using t-SNE.” Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in Deep Learning and NaturalLanguageProcessing. “The Illustrated Transformer.” He obtained his Ph.D.
One of the most popular techniques for speech recognition is naturallanguageprocessing (NLP), which entails training machine learning models on enormous amounts of text data to understand linguistic patterns and structures. It was developed by Facebook AI Research and released in 2019.
The SageMaker Feature Store Feature Processor reduces this burden by automatically transforming raw data into aggregated features suitable for batch training ML models. It lets engineers provide simple data transformation functions, then handles running them at scale on Spark and managing the underlying infrastructure.
Imagine an AI system that becomes proficient in many tasks through extensive training on each specific problem and a higher-order learning process that distills valuable insights from previous learning endeavors. NaturalLanguageProcessing: With Meta-Learning, language models can be generalized across various languages and dialects.
ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. Overall, The combination of ALBERT and knowledge distillation represents a powerful approach to naturallanguageprocessing that can improve the efficiency of large-scale language models and make them more accessible to researchers and developers alike.
Photo by Fatos Bytyqi on Unsplash Introduction Did you know that in the past, computers struggled to understand human languages? But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language.
Large language models are foundation models (a kind of large neural network) that generate or embed text. The text they generate can be conditioned by giving them a starting point or “prompt,” enabling them to solve useful tasks expressed in naturallanguage or code. OpenAI’s GPT-2, finalized in 2019 at 1.5
Large language models are foundation models (a kind of large neural network) that generate or embed text. The text they generate can be conditioned by giving them a starting point or “prompt,” enabling them to solve useful tasks expressed in naturallanguage or code. OpenAI’s GPT-2, finalized in 2019 at 1.5
I came up with an idea of a NaturalLanguageProcessing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). I also got a lot more comfortable with working with huge data and therefore master the skills of a datascientist along the way.
These teams may include but are not limited to datascientists, software developers, machine learning engineers, and DevOps engineers. However, this collaborative process can often pose challenges regarding model packaging. Modularize the model Another approach to dealing with model complexity is modularization. Brownlee, J.
of the spaCy NaturalLanguageProcessing library includes a huge number of features, improvements and bug fixes. spaCy is an open-source library for industrial-strength naturallanguageprocessing in Python. Maybe you’re a grad student working on a paper, maybe you’re a datascientist working on a prototype.
More Read How BI & Data Analytics Pros Used Twitter in May Pageviews are Dead, Engagement is King Can AI Help You Get Better Headshots? Meet the New Era: AI Web Scraper Technology for Data Teams So, what exactly is an AI web scraper ? There are not many industries left untouched by this trend. Followers Like 33.7k
With sports (and everything else) cancelled, this datascientist decided to take on COVID-19 | A Winner’s Interview with David Mezzetti When his hobbies went on hiatus, Kaggler David Mezzetti made fighting COVID-19 his mission. He previously co-founded and built Data Works into a 50+ person well-respected software services company.
His main research interests revolve around applications of Network Analysis and NaturalLanguageProcessing methods. Artem has versatile experience in working with real-life data from different domains and was involved in several data science projects at the World Bank and the University of Oxford.
data # Assing local directory path to a python variable local_data_path = ". . Isaac Privitera is a Principal DataScientist with the AWS Generative AI Innovation Center, where he develops bespoke generative AI-based solutions to address customers’ business problems.
Datascientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. It has been held at the All England Club in Wimbledon, London, since 1877 and is played on outdoor grass courts, with retractable roofs over the two main courts since 2019.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content