This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DeepLearning is/has become the hottest skill in Data Science at the moment. There is a plethora of articles, courses, technologies, influencers and resources that we can leverage to gain the DeepLearning skills.
With deeplearning and AI on the forefront of the latest applications and demands for new business directions, additional education is paramount for current machine learning engineers and datascientists. These courses are famous among peers, and will help you demonstrate tangible proof of your new skills.
This week: Object-oriented programming for datascientists; DeepLearning Next Step: Transformers and Attention Mechanism; R Users' Salaries from the 2019 Stackoverflow Survey; Types of Bias in Machine Learning; 4 Tips for Advanced Feature Engineering and Preprocessing; and much more!
Also: 12 DeepLearning Researchers and Leaders; Natural Language in Python using spaCy: An Introduction; A Single Function to Streamline Image Classification with Keras; Which Data Science Skills are core and which are hot/emerging ones?; 6 bits of advice for DataScientists.
Generative Adversarial Networks are driving important new technologies in deeplearning methods. With so much to learn, these two videos will help you jump into your exploration with GANs and the mathematics behind the modelling.
Find out how datascientists and AI practitioners can use a machine learning experimentation platform like Comet.ml to apply machine learning and deeplearning to methods in the domain of audio analysis.
Learn about statistical fallacies DataScientists should avoid; New and quite amazing DeepLearning capabilities FB has been quietly open-sourcing; Top Machine Learning tools for Developers; How to build a Neural Network from scratch and more.
Also: DeepLearning for NLP: Creating a Chatbot with Keras!; Understanding Decision Trees for Classification in Python; How to Become More Marketable as a DataScientist; Is Kaggle Learn a Faster Data Science Education?
Also: Types of Bias in Machine Learning; DeepLearning Next Step: Transformers and Attention Mechanism; New Poll: Data Science Skills; R Users Salaries from the 2019 Stackoverflow Survey; How to Sell Your Boss on the Need for Data Analytics.
DataScientists need computing power. Whether you’re processing a big dataset with Pandas or running some computation on a massive matrix with Numpy, you’ll need a powerful machine to get the job done in a reasonable amount of time.
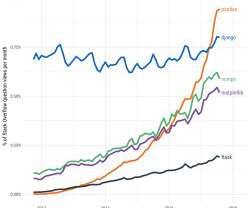
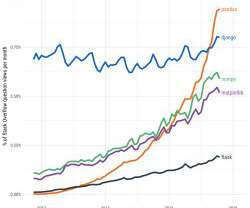
Here is the latest data science news for the week of April 29, 2019. From Data Science 101. The Go Programming Language for Data Science Quick Video Tutorial for Find Updates in Azure Two-Minute Papers, One Pixel attack on NN. General Data Science. This article covers some tips for just that.
Also: Understanding Boxplots; Probability Learning: Maximum Likelihood; Designing Your Neural Networks; Facebook Has Been Quietly Open Sourcing Some Amazing DeepLearning Capabilities for PyTorch; 5 Statistical Traps DataScientists Should Avoid.
Also: Activation maps for deeplearning models in a few lines of code; The 4 Quadrants of Data Science Skills and 7 Principles for Creating a Viral Data Visualization; OpenAI Tried to Train AI Agents to Play Hide-And-Seek but Instead They Were Shocked by What They Learned; 10 Great Python Resources for Aspiring DataScientists.
Also: For data pros only - An SQL Query walks into a bar and sees two tables; DeepLearning for NLP: Creating a Chatbot with Keras!; 12 NLP Researchers, Practitioners & Innovators You Should Be Following; Wanting to be even more marketable as a datascientist?
In a world of large language models (LLMs), deep double descent has created a new shift in understanding data and its position in deeplearning models. A traditional LLM uses large amounts of data to train a machine-learning model, believing that bigger datasets lead to greater accuracy of results.
Two names stand out prominently in the wide realm of deeplearning: TensorFlow and PyTorch. These strong frameworks have changed the field, allowing researchers and practitioners to create and deploy cutting-edge machine learning models. TensorFlow and PyTorch present distinct routes to traverse.
Deeplearning automates and improves medical picture analysis. Convolutional neural networks (CNNs) can learn complicated patterns and features from enormous datasets, emulating the human visual system. Convolutional Neural Networks (CNNs) Deeplearning in medical image analysis relies on CNNs.
A World of Computer Vision Outside of DeepLearning Photo by Museums Victoria on Unsplash IBM defines computer vision as “a field of artificial intelligence (AI) that enables computers and systems to derive meaningful information from digital images, videos and other visual inputs [1].”
The breakthrough came through a novel unsupervised deeplearning methodology developed by Fernandez-Granda, Peter Crozier, and collaborators to train deep neural networks and also evaluate them using only noisy data. But with too few electrons, your images are dominated bynoise. By StephenThomas
Open source is becoming the standard for sharing and improving technology. Some of the largest organizations in the world namely: Google, Facebook and Uber are open sourcing their own technologies that they use in their workflow to the public.
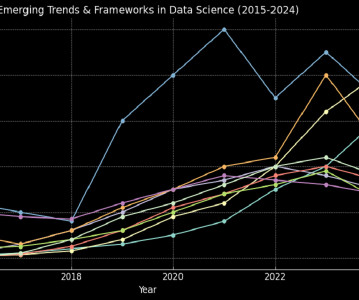
The Early Years: Laying the Foundations (20152017) In the early years, data science conferences predominantly focused on foundational topics like data analytics , visualization , and the rise of big data. The DeepLearning Boom (20182019) Between 2018 and 2019, deeplearning dominated the conference landscape.
yml file from the AWS DeepLearning Containers GitHub repository, illustrating how the model synthesizes information across an entire repository. Codebase analysis with Llama 4 Using Llama 4 Scouts industry-leading context window, this section showcases its ability to deeply analyze expansive codebases. billion to a projected $574.78
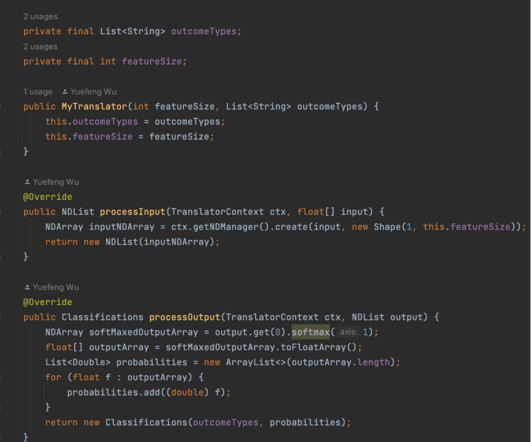
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts.
Jupyter enables users to work with code and data interactively, and to build and share computational narratives that provide a full and reproducible record of their work. Given the importance of Jupyter to datascientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
This is a guest post co-authored with Ville Tuulos (Co-founder and CEO) and Eddie Mattia (DataScientist) of Outerbounds. We then show how to set up the infrastructure stack you need to take your own data assets and pre-train or fine-tune a state-of-the-art Llama2 model on Trainium hardware.
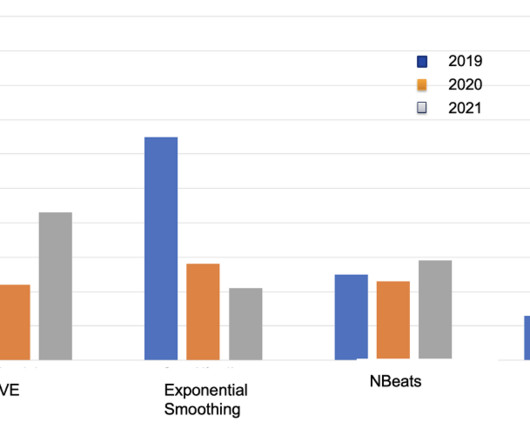
For example, in the 2019 WAPE value, we trained our model using sales data between 2011–2018 and predicted sales values for the next 12 months (2019 sale). We evaluated the WAPE for all BLs in the auto end market for 2019, 2020, and 2021. In 2019 and 2020, our model achieved less than 0.1
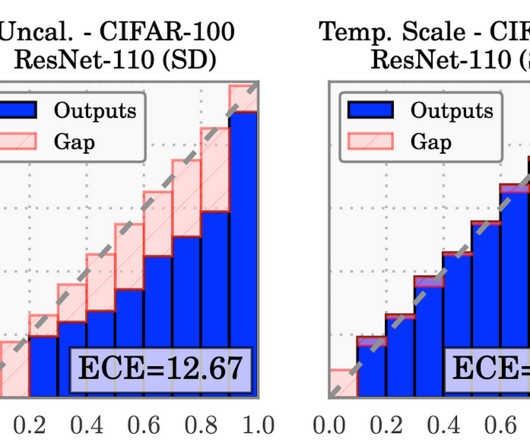
Label Smoothing Equation [5] In their 2019 paper “ When does label smoothing help? ”, Hinton et al. [5] logits of the final layer), which helps reduce overconfidence and subsequently reduces the network’s ECE. ” Advances in neural information processing systems 32 (2019). [6] Measuring Calibration in DeepLearning.
After all, this is what machine learning really is; a series of algorithms rooted in mathematics that can iterate some internal parameters based on data. He is co-host of the AI Right podcast and was named ‘Rising Star of the Year’ at the 2022 British Data Awards and ‘DataScientist of the Year’ by the Data Science Foundation in 2019.
Jump Right To The Downloads Section In the world of machine learning and AI (artificial intelligence), building a powerful model is only half the battle; the other half lies in demonstrating its impact. For machine learning engineers and datascientists, creating intuitive user interfaces (UIs) to showcase their models can be a game-changer.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
From generative modeling to automated product tagging, cloud computing, predictive analytics, and deeplearning, the speakers present a diverse range of expertise. Our speakers lead their fields and embody the desire to create revolutionary ML experiences by leveraging the power of data-centric AI to drive innovation and progress.
From generative modeling to automated product tagging, cloud computing, predictive analytics, and deeplearning, the speakers present a diverse range of expertise. Our speakers lead their fields and embody the desire to create revolutionary ML experiences by leveraging the power of data-centric AI to drive innovation and progress.
Srinivas Alva is a DataScientist at ZS Associates, specializing in the transformation of high-grade research into commercial solutions. degree in AI and ML specialization from Gujarat University, earned in 2019. His expertise and experience make him a valuable asset in the field of data science and Generative AI.
LeCun received the 2018 Turing Award (often referred to as the "Nobel Prize of Computing"), together with Yoshua Bengio and Geoffrey Hinton, for their work on deeplearning. Hinton is viewed as a leading figure in the deeplearning community. > Finished chain. ") > Entering new AgentExecutor chain.
It was developed by Facebook AI Research and released in 2019. Interpretability: Like many other deeplearning models, RoBERTa is frequently referred to as a “black box.” Overfitting: RoBERTa, like any deeplearning model, is prone to overfitting. It is a state-of-the-art model for a variety of NLP tasks.
Action: duckduckgo_search Action Input: "Chief AI Scientist Meta AI" Observation: At the same panel, Yann LeCun, chief AI scientist at Facebook parent Meta, was asked about the current limitations of AI. scientist calls A.I. Hinton is viewed as a leading figure in the deeplearning community. France: 82.7:
2019) set out to determine how well an NLP model could determine whether or not a given sentence adhered to linguistic norms. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners.
Prerequisites To follow along with this tutorial, you will need the following: Basic knowledge of Python and deeplearning. Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables datascientists & ML teams to track, compare, explain, & optimize their experiments.
Collaboration across teams Machine learning models result from collaborative efforts among teams with different skill sets and expertise. These teams may include but are not limited to datascientists, software developers, machine learning engineers, and DevOps engineers. Thanks for reading, and keep learning!
Advances in neural information processing systems 32 (2019). Visualizing data using t-SNE.” Journal of machine learning research 9, no. Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in DeepLearning and Natural Language Processing.
Although these techniques are effective, they are limited by how much data they can compress. Deeplearning-based compression techniques have emerged as a viable alternative to traditional methods. Requirements For this tutorial, you need the following: Basic knowledge of Python and deeplearning.
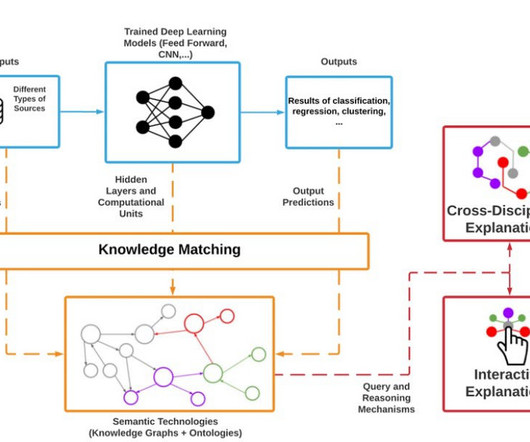
For example, explainability is crucial if a healthcare professional uses a deeplearning model for medical diagnoses. Audience and Context Interpretability : Interpretability primarily targets researchers, datascientists, or experts interested in understanding the model's behavior and improving its performance.
Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. Named entity annotations and noun phrases can also help, by letting you learn vectors for multi-word expressions.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. However, the model’s size and computational requirements can make it challenging to use in some applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content