This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, as companies have finally come to understand the value that datascience can bring, more and more emphasis is being placed on the implementation of datascience in production systems.
Here is the latest datascience news for May 2019. From DataScience 101. REAL TALK WITH A DATA SCIENTIST: THE FUTURE OF DATA WRANGLING WHAT IS ON THE MICROSOFT DATASCIENCE CERTIFICATION EXAM? General DataScience. Not all are datascience/AI related, but many are.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the cloud datascience world. Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure Data Lake. Those are the big datascience announcements of the week.
Welcome to the first beta edition of Cloud DataScience News. This will cover major announcements and news for doing datascience in the cloud. Azure Synapse Analytics This is the future of data warehousing. Azure Synapse Analytics This is the future of data warehousing. Microsoft Azure. Google Cloud.
Here are this week’s news and announcements related to Cloud DataScience. Google is launching Explainable AI which quantifies the impact of the various factors of the data as well as the existing limitations. AWS Storage Day On November 20, 2019, Amazon held AWS Storage Day. Announcements.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
This week Amazon hosted the large AWS re:Invent Conference. Netflix and AWS open source Metaflow Making it easy to build and manage real-life datascience projects. AWS re:Invent Machine Learning Announcements AWS CEO details all of the Machine Learning announcements during his keynote. Announcements.
Unfortunately, it did not bring a flurry of datascience announcements. Machine Learning with Kubernetes on AWS A talk from Container Day 2019 in San Diego. A First Look at AWSData Exchange (Webinar) AWSData Exchange is a product for finding and using third party data.
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
AWS re:Invent 2019 starts today. It is a large learning conference dedicated to Amazon Web Services and Cloud Computing. Parts of the event will be livestreamed , so you can watch from anywhere. Based upon the announcements last week , there will probably be a lot of focus around machine learning and deep learning.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
In this post, we investigate of potential for the AWS Graviton3 processor to accelerate neural network training for ThirdAI’s unique CPU-based deep learning engine. As shown in our results, we observed a significant training speedup with AWS Graviton3 over the comparable Intel and NVIDIA instances on several representative modeling workloads.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia. 2048 256 10.4
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for datascience, machine learning (ML), and computational science. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
In addition to Business Intelligence (BI), Process Mining is no longer a new phenomenon, but almost all larger companies are conducting this data-driven process analysis in their organization. For analysis the way of Business Intelligence this normalized data model can already be used. Click to enlarge!
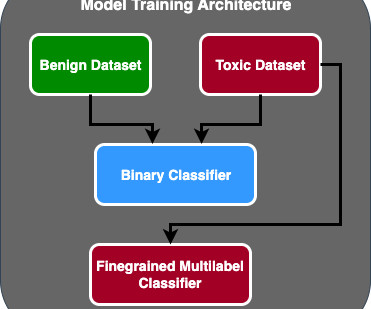
In an effort to create and maintain a socially responsible gaming environment, AWS Professional Services was asked to build a mechanism that detects inappropriate language (toxic speech) within online gaming player interactions. Unfortunately, as in the real world, not all players communicate appropriately and respectfully.
In the following sections, we explain how you can use these features with either the AWS Management Console or SDK. The correct response for this query is “Amazon’s annual revenue increased from $245B in 2019 to $434B in 2022,” based on the documents in the knowledge base. We ask “What was the Amazon’s revenue in 2019 and 2021?”
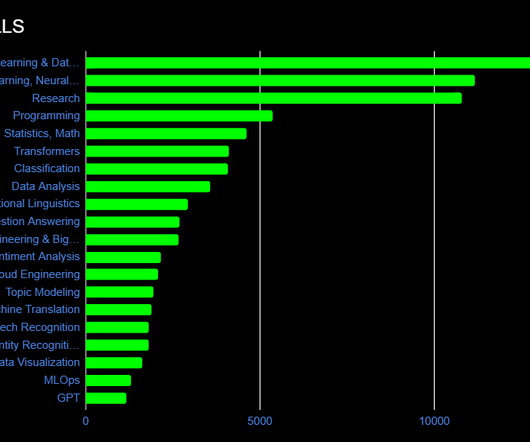
The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know datascience and in turn, NLP.
For more information on Mixtral-8x7B Instruct on AWS, refer to Mixtral-8x7B is now available in Amazon SageMaker JumpStart. Before you get started with the solution, create an AWS account. This identity is called the AWS account root user. The Mixtral-8x7B model is made available under the permissive Apache 2.0
As newer fields emerge within datascience and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. Recently, we spoke with Emily Webber, Principal Machine Learning Specialist Solutions Architect at AWS. Q: LLMs didn’t pick up in popularity until late 2022. Register here.
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from data preparation, building and experimentation, training, hosting, and monitoring. Lauren Mullennex is a Senior AI/ML Specialist Solutions Architect at AWS. In his spare time, he loves traveling and writing.
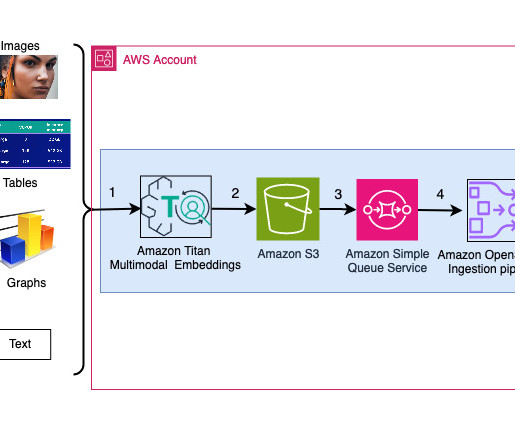
We used AWS services including Amazon Bedrock , Amazon SageMaker , and Amazon OpenSearch Serverless in this solution. The data is sent to the Amazon Titan Text Embeddings model to generate embeddings. Use AWS CloudFormation to create the solution stack You can use AWS CloudFormation to create the solution stack.
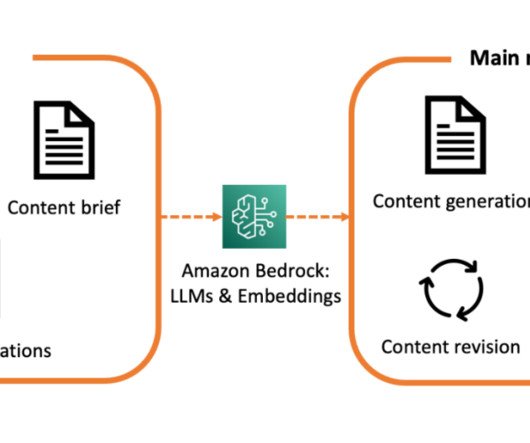
To answer this question, the AWS Generative AI Innovation Center recently developed an AI assistant for medical content generation. 2019 Apr;179(4):561-569. Epub 2019 Jan 31. Data Scientist with 8+ years of experience in DataScience and Machine Learning. Am J Med Genet A. doi: 10.1002/ajmg.a.61055.
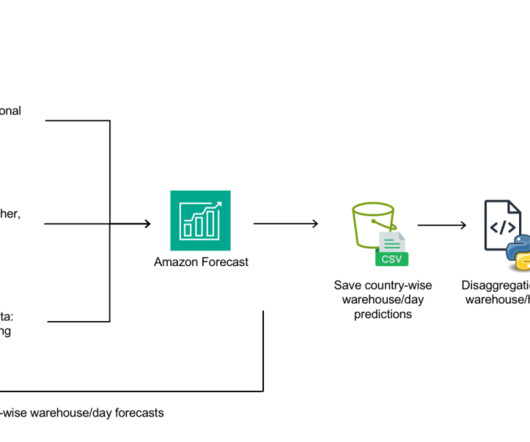
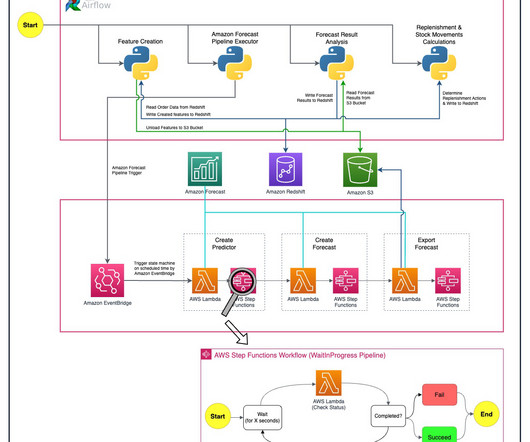
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. The following diagram shows the solution’s architecture.
In this post, we detail our collaboration in creating two proof of concept (PoC) exercises around multi-modal machine learning for survival analysis and cancer sub-typing, using genomic (gene expression, mutation and copy number variant data) and imaging (histopathology slides) data. 2022 ) was implemented (Section 2.1).
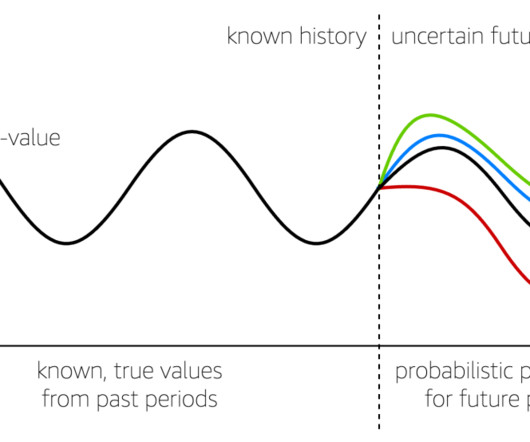
Modern, state-of-the-art time series forecasting enables choice To meet real-world forecasting needs, AWS provides a broad and deep set of capabilities that deliver a modern approach to time series forecasting. Real-world data is more complicated than can be expressed with an average or a straight regression line estimate.
Amazon Go, a cashier-less convenience store that debuted in 2019, is just one instance of how traditional industries are undergoing a digital upheaval. A common pitfall for businesses undergoing digital transformation is assuming that it is easy to migrate existing technology to a new platform or system (like the cloud or AWS).
Organizations must diligently manage access controls, encryption, and data protection to mitigate risks. For example, the 2019 Capital One breach exposed over 100 million customer records, highlighting the need for robust security measures. Data catalog: Implement a data catalog to organize and catalog your data assets.
Priorities for Data Cubes evolution Users and developers discussed some of the main trends in the evolution of data cubes and best practices moving forward, such as how to overcome bottlenecks, and key technologies to improve efficiency and accessibility. 2/2) What should be the priority for the data cube evolution? Queiroz, G.
Advances in neural information processing systems 32 (2019). Visualizing data using t-SNE.” He helps AWS customers identify and build ML solutions to address their business challenges in areas such as logistics, personalization and recommendations, computer vision, fraud prevention, forecasting and supply chain optimization.
She finished her second Masters in Computer Engineering and Cybersecurity in 2019 from San Jose State University. Security and DataScience are interlayered sciences that are used to create solutions for companies looking to protect themselves from cyber-criminal threats. Reena covered these two areas in the presentation.
The Future of Data-centric AI virtual conference will bring together a star-studded lineup of expert speakers from across the machine learning, artificial intelligence, and datascience field. chief data scientist, a role he held under President Barack Obama from 2015 to 2017. Patil served as the first U.S.
The Future of Data-centric AI virtual conference will bring together a star-studded lineup of expert speakers from across the machine learning, artificial intelligence, and datascience field. chief data scientist, a role he held under President Barack Obama from 2015 to 2017. Patil served as the first U.S.
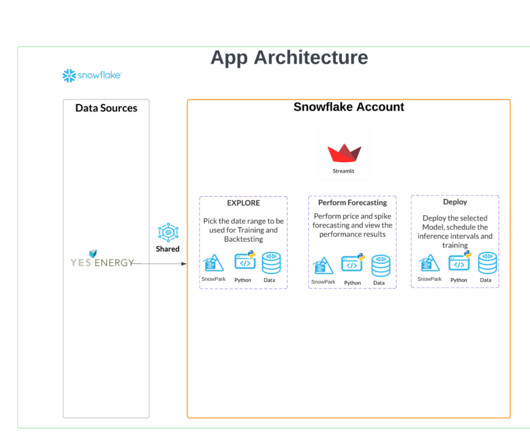
Utilizing Streamlit as a Front-End At this point, we have all of our data processing, model training, inference, and model evaluation steps set up with Snowpark. Streamlit, an open-source Python package for building web-apps, has grown in popularity since its launch in 2019. Let’s continue by creating a front-end to enable analysts.
Learn more Version Control for Machine Learning and DataScience Dataset version management challenges Data storage and retrieval As a machine learning project advances in its lifecycle, its demand for data also increases. Data Management at Scale. Read more How to Version and Compare Datasets in neptune.ai
This piece of data that my mentor found is called “ SemCor Corpus [5] ” (We access the dataset via NLTK’s SemcorCorpusReader [6] ) The reformatted version of the dataset looks something like this. It might look quite overwhelming but this is what datascience and computer engineering are about.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). OpenAI’s GPT-2, finalized in 2019 at 1.5 The plot was boring and the acting was awful: Negative This movie was okay. For example: I love this movie.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). OpenAI’s GPT-2, finalized in 2019 at 1.5 The plot was boring and the acting was awful: Negative This movie was okay. For example: I love this movie.
For example, let’s take Airflow , AWS SageMaker pipelines. We’re building on top of Hamilton, which is an open-source framework for describing data flows. As you’ve been running the ML data platform team, how do you do that? If you can be data-driven, that is the best. Stefan: Back in 2019.
It’s a fully managed on-demand service, integrated with SageMaker and other AWS services, and therefore creates and manages resources for you. Furthermore, Pipelines is supported by the SageMaker Python SDK , letting you track your data lineage and reuse steps by caching them to ease development time and cost.
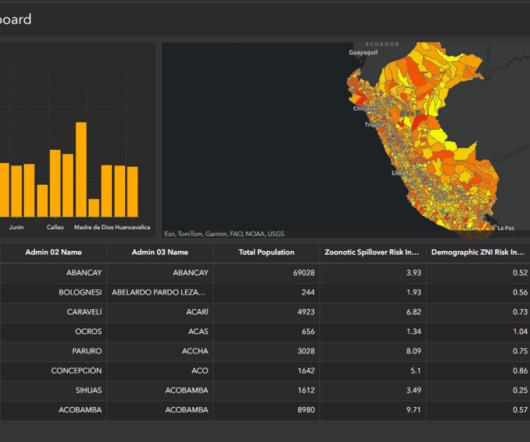
According to health organizations such as the Centers for Disease Control and Prevention ( CDC ) and the World Health Organization ( WHO ), a spillover event at a wet market in Wuhan, China most likely caused the coronavirus disease 2019 (COVID-19). Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in geospatial AI/ML.
Progress of Gen AI from DataScience Dojo 1. Following earlier collaborations in 2019 and 2021, this agreement focused on boosting AI supercomputing capabilities and research. AWS launched Bedrock Amazon Web Services unveiled its groundbreaking service, Bedrock. OpenAI released Dall.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content