This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This increases the time it takes for customers to go from data to insights. Our customers want a simple and secure way to find the best applications, integrate the selected applications into their machine learning (ML) and generative AI development environment, manage and scale their AI projects.
Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. Read the original article at Turing Post , the newsletter for over 90 000 professionals who are serious about AI and ML. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific.
Here is what a recent whitepaper by Dataiku reveals about Artificial intelligence and machine learning emphasising on the role of datascientists. This is the first part of an article series based on a whitepaper by Dataiku) The year 2018 was supposed to be the one. Let’s find out.
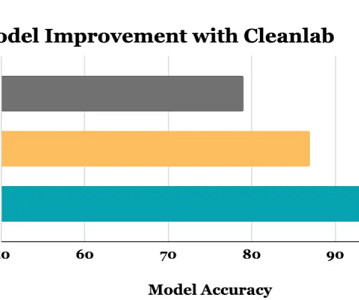
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Our goal is to enable all developers to find and fix data issues as effectively as today’s best datascientists.
They are essential for processing large amounts of data efficiently, particularly in deep learning applications. By 2018, these powerful tools were made available for third-party use, marking a significant milestone in the accessibility of high-performance computing resources.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
Whether you are a DataScientist or a college student, the LinkedIn platform can give you a plethora of options to explore and grow. In this blog, we will be uncovering the how you can optimize DataScientist LinkedIn profile for Indian market , as well as approach a global audience.
By harnessing the power of threat intelligence, machine learning (ML), and artificial intelligence (AI), Sophos delivers a comprehensive range of advanced products and services. The Sophos Artificial Intelligence (AI) group (SophosAI) oversees the development and maintenance of Sophos’s major ML security technology.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Business requirements We are the US squad of the Sportradar AI department.
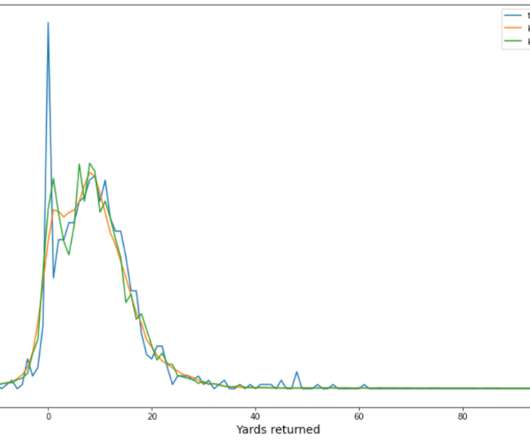
With advanced analytics derived from machine learning (ML), the NFL is creating new ways to quantify football, and to provide fans with the tools needed to increase their knowledge of the games within the game of football. Next, we present the data preprocessing and other transformation methods applied to the dataset.
This approach allows for greater flexibility and integration with existing AI and machine learning (AI/ML) workflows and pipelines. By providing multiple access points, SageMaker JumpStart helps you seamlessly incorporate pre-trained models into your AI/ML development efforts, regardless of your preferred interface or workflow.
Secondly, to be a successful ML engineer in the real world, you cannot just understand the technology; you must understand the business. Some typical examples are given in the following table, along with some discussion as to whether or not ML would be an appropriate tool for solving the problem: Figure 1.1:
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
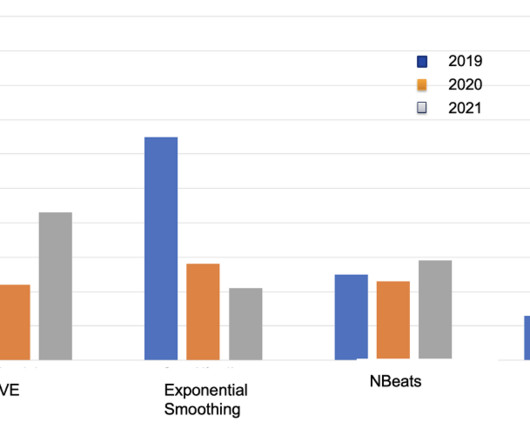
& AWS Machine Learning Solutions Lab (MLSL) Machine learning (ML) is being used across a wide range of industries to extract actionable insights from data to streamline processes and improve revenue generation. We calculated the WAPE value of a model by splitting the data into test and validation sets.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. Each season consists of around 17,000 plays.
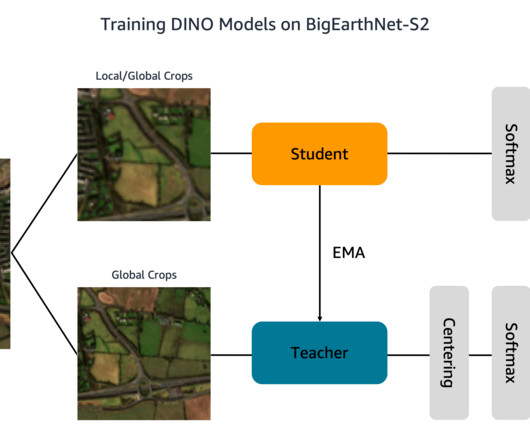
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. The following are a few example RGB images and their labels.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. Overall , understanding kernels and how to select and tune them is an important aspect of being a datascientist. What are kernels? Types of kernels.
AWS ProServe solved this use case through a joint effort between the Generative AI Innovation Center (GAIIC) and the ProServe ML Delivery Team (MLDT). However, LLMs are not a new technology in the ML space. The new ML workflow now starts with a pre-trained model dubbed a foundation model.
While this requires technology – AI, machine learning, log parsing, natural language processing,metadata management, this technology must be surfaced in a form accessible to business users – the data catalog. The Forrester Wave : Machine Learning Data Catalogs, Q2 2018. Subscribe to Alation's Blog.
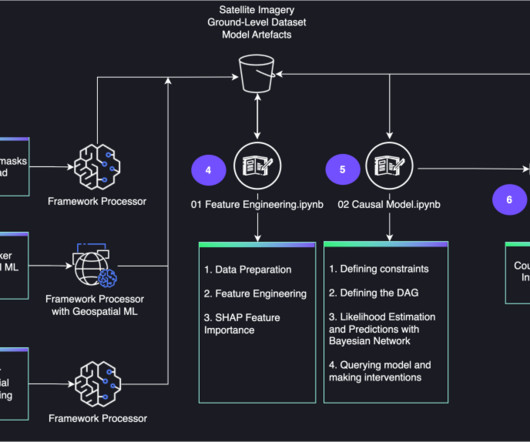
Causal inference Causality is all about understanding change, but how to formalize this in statistics and machine learning (ML) is not a trivial exercise. Note that this solution is currently available in the US West (Oregon) Region only. In this crop yield study, the nitrogen added as fertilizer and the yield outcomes might be confounded.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machine learning (ML) model from distributed health data held locally at different sites. Import the data loader into the training script.
To help with these efforts, we’ve compiled a list of the top NLP datasets for NLP projects that datascientists and data professionals can use for training their models. million articles from 20,000 news sources across a seven day period in 2017 and 2018. This list is a starting point for training your NLP models.
When you’re working on an enterprise scale, managing your ML models can be tricky. YOLOv3 is a newer version of YOLO and was released in 2018. During training, the model is presented with an image with its own real labels and learns to predict the class and position of each object in the image, as well as the corresponding mask.
In January, we publicly unveiled our SaaS platform , which helps datascientists collect, enrich, and structure data to train AI and ML models. We also have big plans to grow and qualify our crowd on Neevo and ensure data security through GDPR compliance and ISO certifications. It’s been a big year for us so far.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all machine learning (ML) development steps, from preparing data to building, training, and deploying your ML models. He retired from EPFL in December 2016.nnIn
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers datascientists, machine learning (ML) engineers, and researchers to build high-quality datasets. For our example use case, we work with the Fashion200K dataset , released at ICCV 2017. Then import the relevant modules.
Some recent examples: Robotic systems that learned to grab and manipulate things with human-like dexterity was demonstrated by Google Brain researchers in 2018 utilizing deep reinforcement learning. A combination of simulated and real-world data was used to train the system, enabling it to generalize to new objects and tasks.
As per the recent report by Nasscom and Zynga, the number of data science jobs in India is set to grow from 2,720 in 2018 to 16,500 by 2025. Top 5 Colleges to Learn Data Science (Online Platforms) 1. also offers free classes on Machine Learning that cover the core concepts of ML. In addition, Pickl.AI
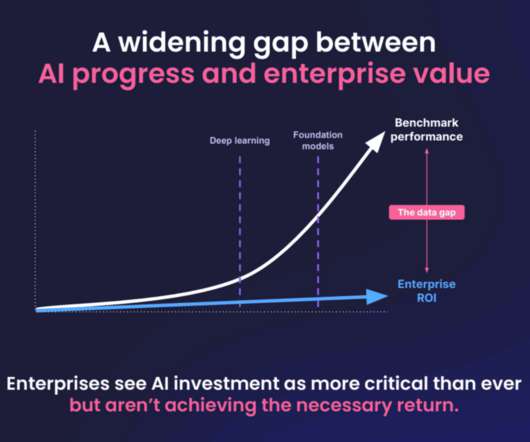
Trends in Enterprise ML and the Potential Impact of Foundation Models Carlo Giovine, a partner at McKinsey QuantumBlack , together with David Harvey, a staff expert at the same firm, told the online audience that companies are not moving fast enough to capture the value potential of AI/ML.
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.” We’re here to talk to you all about data-centric AI. That’s data. It’s wonderful to be here.
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.” We’re here to talk to you all about data-centric AI. That’s data. It’s wonderful to be here.
About the Authors Maira Ladeira Tanke is a Senior Generative AI DataScientist at AWS. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. Mark holds six AWS certifications, including the ML Specialty Certification.
Together with David Harvey, an engagement manager focused on scaling deployments and applied R&D at that same firm, they presented the session “Trends in Enterprise ML and the potential impact of Foundation Models” at Snorkel AI’s 2023 Foundation Model Virtual Summit. Our ML protocols need updating in several ways.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables datascientists & ML teams to track, compare, explain, & optimize their experiments. We’re committed to supporting and inspiring developers and engineers from all walks of life.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. We pay our contributors, and we don’t sell ads.
LeCun received the 2018 Turing Award (often referred to as the "Nobel Prize of Computing"), together with Yoshua Bengio and Geoffrey Hinton, for their work on deep learning. He is also one of the main creators of the DjVu image compression technology (together with Léon Bottou and Patrick Haffner).
Audience and Context Interpretability : Interpretability primarily targets researchers, datascientists, or experts interested in understanding the model's behavior and improving its performance. Why We Will Never Open Deep Learning's Black Box || Towards Data Science Brent, M., Russell, C. & & Watcher, S.
Datascientists can build upon generalized FMs and fine-tune custom versions with domain-specific or task-specific training data. This model debuted in June 2020, but remained a tool for researchers and ML practitioners until its creator, OpenAI, debuted a consumer-friendly chat interface in November 2022.
LeCun received the 2018 Turing Award (often referred to as the "Nobel Prize of Computing"), together with Yoshua Bengio and Geoffrey Hinton, for their work on deep learning. He is also one of the main creators of the DjVu image compression technology (together with Léon Bottou and Patrick Haffner).
Let's run this command with the following code: # Training loop for epoch in range(num_epochs): for batch_idx, (support_set, query_set) in enumerate(train_loader): optimizer.zero_grad() # Move data to device (e.g., 2018) Reptile: A scalable meta-learning algorithm || OpenAI.com Xavier L. GPU) support_set = support_set.to(device)
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables datascientists & ML teams to track, compare, explain, & optimize their experiments. Natural language processing and machine learning as practical toolsets for archival processing. Law and word order: NLP in legal tech.
With that said, I’m actually a faculty member at Harvard, and one of my key goals is to help—both academically as well as from an industry perspective—work with MLCommons , which is a nonprofit organization focusing on accelerating benchmarks, datasets, and best practices for ML (machine learning). Learn more, live!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content