This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
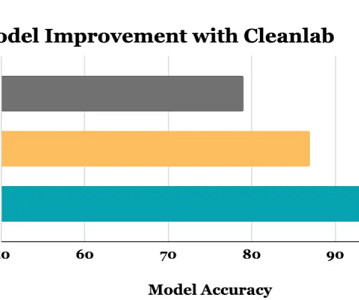
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Our goal is to enable all developers to find and fix data issues as effectively as today’s best datascientists.
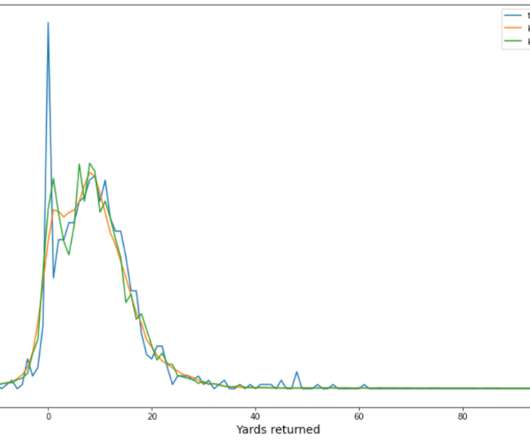
The player tracking data contains the player’s position, direction, acceleration, and more (in x,y coordinates). There are around 3,000 and 4,000 plays from four NFL seasons (2018–2021) for punt and kickoff plays, respectively. The data distribution for punt and kickoff are different.
In 2018, American Family Insurance became an Alation customer and I became the product owner for the AmFam catalog program. To answer these questions we need to look at how data roles within the job market have evolved, and how academic programs have changed to meet new workforce demands. The datascientist.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. He has collaborated with the Amazon Machine Learning Solutions Lab in providing cleandata for them to work with as well as providing domain knowledge about the data itself.
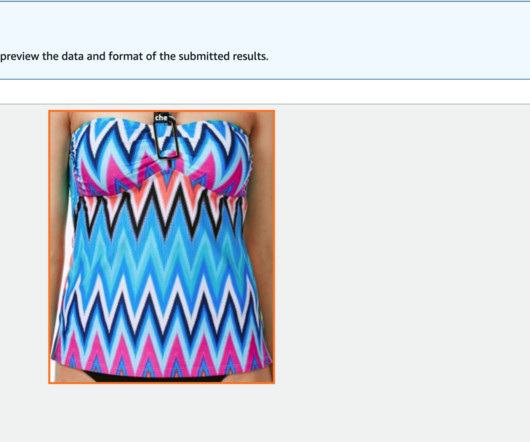
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers datascientists, machine learning (ML) engineers, and researchers to build high-quality datasets. To learn more about Ground Truth, refer to Label Data , Amazon SageMaker Data Labeling FAQs , and the AWS Machine Learning Blog.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content