This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How did you get started in data science? Like many datascientists in the 2010s, I stumbled my way into the field. Afterward, I worked as research assistant at the Fiscal Research Center - a research group at GSU - on a project measuring income mobility in Georgia using government administrative data.
Are you looking to get a job in big data? The Bureau of Labor Statistics reports that there were over 31,000 people working in this field back in 2018. However, it is not easy to get a career in big data. You need to make sure that you can answer them accurately, articulately and succinctly to get a job as a datascientist.
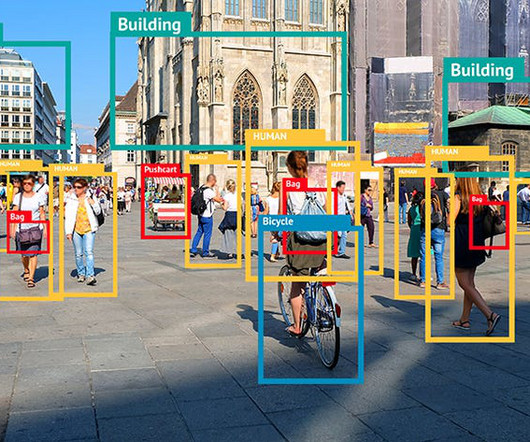
How do Object Detection Algorithms Work? There are two main categories of object detection algorithms. Two-Stage Algorithms: Two-stage object detection algorithms consist of two different stages. Single-stage object detection algorithms do the whole process through a single neural network model.
They are essential for processing large amounts of data efficiently, particularly in deep learning applications. Developed by Google, these devices are application-specific integrated circuits (ASICs) that enhance the performance of AI algorithms, particularly for tasks related to neural networks and deep learning.
Its innovative data flow architecture enables users to execute complex statistical analyses and create sophisticated models efficiently. Overview of TensorFlow TensorFlow emerged as a key tool for datascientists and statisticians, facilitating the implementation of machine learning models.
O Texts (2018). [3] Caner Turkmen is a Senior Applied Scientist at Amazon Web Services, where he works on research problems at the intersection of machine learning and forecasting. Before joining AWS, he worked in the management consulting industry as a datascientist, serving the financial services and telecommunications sectors.
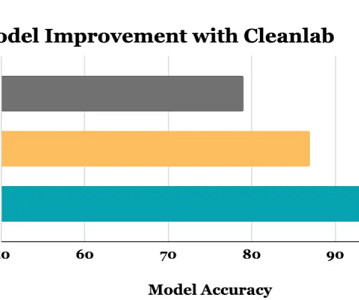
While most ML classes teach students about modeling a fixed dataset, experienced datascientists know that improving data brings higher ROI than tinkering with models. Our goal is to enable all developers to find and fix data issues as effectively as today’s best datascientists. How does cleanlab work?
GenAI I serve as the Principal DataScientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of data science, I’ve witnessed significant transformations.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. Support Vector Machine Support Vector Machine ( SVM ) is a supervised learning algorithm used for classification and regression analysis. What are kernels?
The data set only helps it if it’s well-trained and supervised. A Mongolian pharmaceutical company engaged in a pilot study in 2018 to detect fake drugs, an initiative with the potential to save hundreds of thousands of lives. Experts train AI specifically on how to fight counterfeit products.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Machine learning and AI analytics: Machine learning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
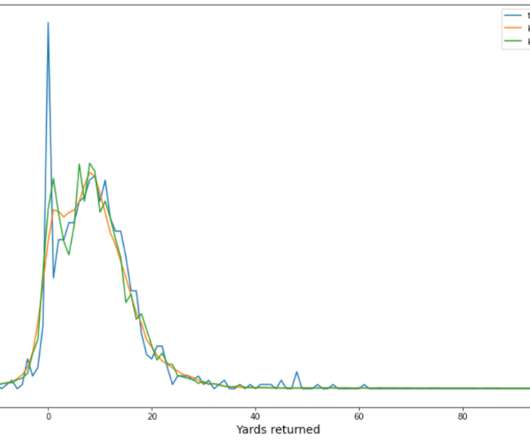
The player tracking data contains the player’s position, direction, acceleration, and more (in x,y coordinates). There are around 3,000 and 4,000 plays from four NFL seasons (2018–2021) for punt and kickoff plays, respectively. The data distribution for punt and kickoff are different.
By incorporating computer vision methods and algorithms into robots, they are able to view and understand their environment. Object recognition and tracking algorithms include the CamShift algorithm , Kalman filter , and Particle filter , among others.
An additional 2018 study found that each SLR takes nearly 1,200 total hours per project. This ongoing process straddles the intersection between evidence-based medicine, data science, and artificial intelligence (AI). dollars apiece.
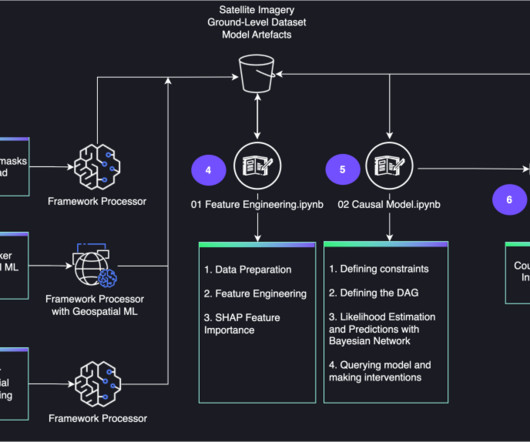
The structure of the causal model is initially learned from data, whereas subject matter expertise (trusted literature or empirical beliefs) is used to postulate additional dependencies and independencies between random variables and intervention variables, as well as asserting the structure is causal.
After all, this is what machine learning really is; a series of algorithms rooted in mathematics that can iterate some internal parameters based on data. This is understandable: a report by PwC in 2018 suggested that 30% of UK jobs will be impacted by automation by the 2030s Will Robots Really Steal Our Jobs?
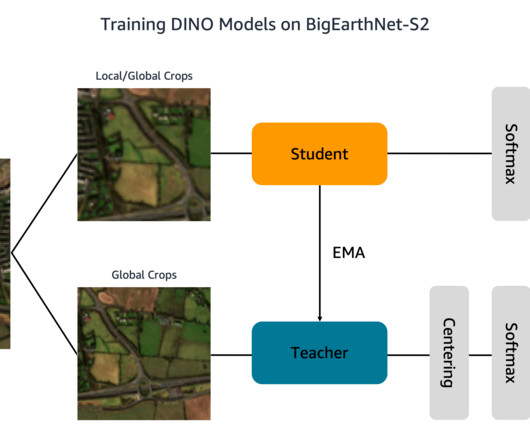
Our solution is based on the DINO algorithm and uses the SageMaker distributed data parallel library (SMDDP) to split the data over multiple GPU instances. The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. tif" --include "_B03.tif" during training.
The same report estimates that in 2018 alone, AI contributed $2 trillion to the global GDP. While it has been fun for datascientists to test what machine learning can do, companies that invest huge resources into their AI solutions want to see results. “AI could contribute up to $15.7
Together with data stores, foundation models make it possible to create and customize generative AI tools for organizations across industries that are looking to optimize customer care, marketing, HR (including talent acquisition) , and IT functions. An open-source model, Google created BERT in 2018.
We also demonstrate the performance of our state-of-the-art point cloud-based product lifecycle prediction algorithm. Challenges One of the challenges we faced while using fine-grained or micro-level modeling like product-level models for sale prediction was missing sales data. We next calculated the MAPE for the actual sales values.
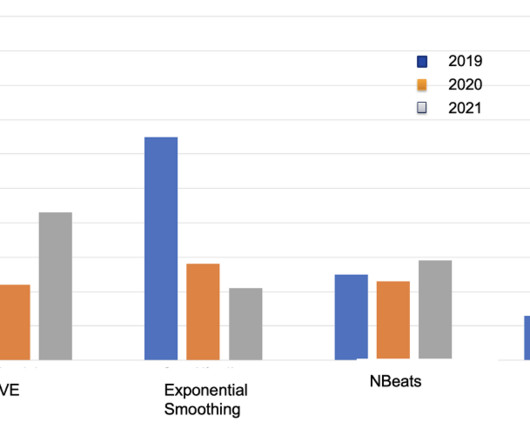
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. Each season consists of around 17,000 plays.
nnIn 1996, Moret founded the ACM Journal of Experimental Algorithmics, and he remained editor in chief of the journal until 2003. About the Authors Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms.
By 2018, about 200 ICO projects were funded. I have nothing but optimism for this space because if you look back to 2014 or 2018 and where we are now–it’s an exponential curve, and we’re still early.” I want individuals to have the ability to take control of their own data and to monetize it in whatever way.
Using historical data from the 2018–2023 Mexico Grand Prix and race data from the 2024 season, participants will analyze variables such as lap times, stint numbers, tire compounds, and pit stop timing. Whether you’re a seasoned data pro or just starting, there’s a place for you in our vibrant community of datascientists.
After 116 years in business, legendary guitar maker Gibson filed for bankruptcy in 2018. A commitment to using data to become a customer-first organization rather than a self-described “developer-led community.”. Collaborating together, they were able to align interests and algorithms to generate a breakthrough data product.
As per the recent report by Nasscom and Zynga, the number of data science jobs in India is set to grow from 2,720 in 2018 to 16,500 by 2025. Top 5 Colleges to Learn Data Science (Online Platforms) 1. The focus of this e-learning platform is to build proficiency in Data Science. Course Fee : The course fee starts from Rs.
Datascientists have been so preoccupied with whether they could build an algorithm, they didn’t stop to think about whether they should. The report identifies key accountability practices around the principles of governance, data, performance, and monitoring to help federal agencies and others use AI responsibly.
SageMaker enables Marubeni to run ML and numerical optimization algorithms in a single environment. His team applies data science and digital technologies to support Marubeni Power growth strategies. Before joining Marubeni, Hernan was a DataScientist at Columbia University. He holds a Ph.D. in Computer Engineering.
Consider a scenario where legal practitioners are armed with clever algorithms capable of analyzing, comprehending, and extracting key insights from massive collections of legal papers. Algorithms can automatically detect and extract key items. But what if there was a technique to quickly and accurately solve this language puzzle?
By leveraging the power of neural networks, deep learning techniques breathe new life into recommendation algorithms, empowering them to handle complex data and surpass the limitations of their predecessors. Netflix’s movies and TV shows are recommended based on user ratings, viewing history, and platform interactions.
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers datascientists, machine learning (ML) engineers, and researchers to build high-quality datasets. To learn more about Ground Truth, refer to Label Data , Amazon SageMaker Data Labeling FAQs , and the AWS Machine Learning Blog.
The data can be accessed via a PhysioNet repository, and details of the data access process can be found here [1]. The eICU data is ideal for developing ML algorithms, decision support tools, and advancing clinical research. We defined it as a binary classification task, where each data sample spans a 1-hour window.
At its core, Meta-Learning equips algorithms with the aptitude to quickly grasp new tasks and domains based on past experiences, paving the way for unparalleled problem-solving skills and generalization abilities. Reptile is a meta-learning algorithm that falls under model-agnostic meta-learning approaches.
LeCun received the 2018 Turing Award (often referred to as the "Nobel Prize of Computing"), together with Yoshua Bengio and Geoffrey Hinton, for their work on deep learning. He is also one of the main creators of the DjVu image compression technology (together with Léon Bottou and Patrick Haffner).
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. Andrew Gordon Wilson before joining Amazon in 2018.
Algorithmic Accountability: Explainability ensures accountability in machine learning and AI systems. Audience and Context Interpretability : Interpretability primarily targets researchers, datascientists, or experts interested in understanding the model's behavior and improving its performance. Russell, C. &
Datascientists can build upon generalized FMs and fine-tune custom versions with domain-specific or task-specific training data. It is based on GPT and uses machine learning algorithms to generate code suggestions as developers write. That’s where the “foundation” in foundation models comes in.
A 2018 study from McKinsey estimated the total global unclaimed value potential from AI/ML at $10-15 trillion, and Foundation Models will enable valuable applications that the firm couldn’t conceive of four years ago. Arora said that the approach yielded a lift in accuracy on all of the popular LLMs they tested on.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. We pay our contributors, and we don’t sell ads.
Data processing and manipulation: Tools provide the necessary functionality for an agent to process and manipulate data. This includes cleaning and transforming data, performing calculations, or applying machine learning algorithms. He co-developed the Lush programming language with Léon Bottou.
Language model pretraining By far the biggest news in NLP research over 2018 was the success of language model pretraining. In 2018, a number of papers showed that a simple language modelling objective worked well for LSTM models. This is exactly what algorithms like word2vec, GloVe and FastText set out to solve. Devlin et al.
al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. However, established test sets often don’t correspond well to the data being used, or the definition of similarity that the application requires.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content