
Identification of Hazardous Areas for Priority Landmine Clearance: AI for Humanitarian Mine Action
ML @ CMU
NOVEMBER 7, 2024
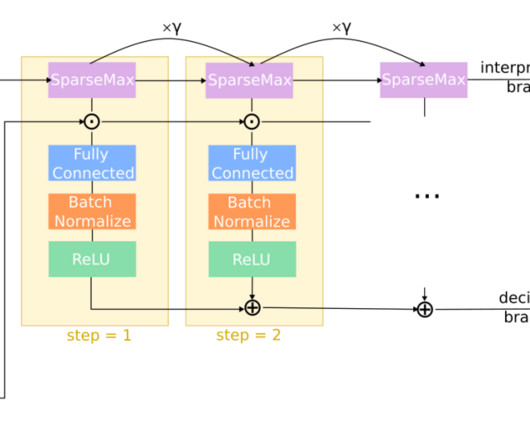
Since landmines are not used randomly but under war logic , Machine Learning can potentially help with these surveys by analyzing historical events and their correlation to relevant features. Validation results in Colombia. Each entry is the mean (std) performance on validation folds following the block cross-validation rule.








Let's personalize your content