This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI hallucinations: When language models dream in algorithms. Inaccuracies span a spectrum, from odd and inconsequential instances—such as suggesting the Golden Gate Bridge’s relocation to Egypt in 2016—to more consequential and problematic scenarios.
The quality of your training data in Machine Learning (ML) can make or break your entire project. This article explores real-world cases where poor-qualitydata led to model failures, and what we can learn from these experiences. Why Does DataQuality Matter? The outcome? Sounds great, right?
Preprocessing – You might consider a series of preprocessing steps to improve dataquality and training efficiency. For example, certain data sources can contain a fair number of noisy tokens; deduplication is considered a useful step to improve dataquality and reduce training cost. billion words 5.1
Consider a scenario where legal practitioners are armed with clever algorithms capable of analyzing, comprehending, and extracting key insights from massive collections of legal papers. Algorithms can automatically detect and extract key items. But what if there was a technique to quickly and accurately solve this language puzzle?
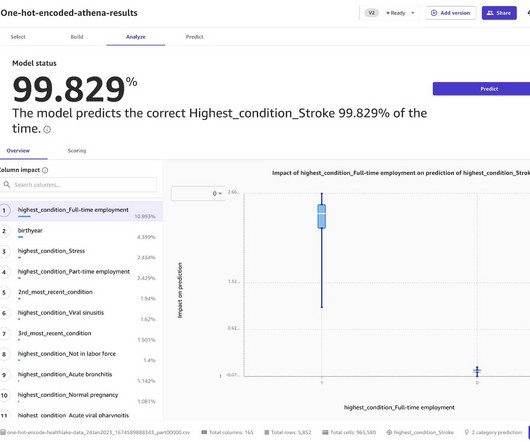
One of the challenges of working with categorical data is that it is not as amenable to being used in many machine learning algorithms. To overcome this, we use one-hot encoding, which converts each category in a column to a separate binary column, making the data suitable for a wider range of algorithms.
A classification model or a classifier is a type of machine learning algorithm that assigns categories or labels to data points. Improve your dataquality for better AI DagsHub helps you easily curate and annotate your vision, audio, and document data with a single platform. Müller, A. C., & Guido, S.
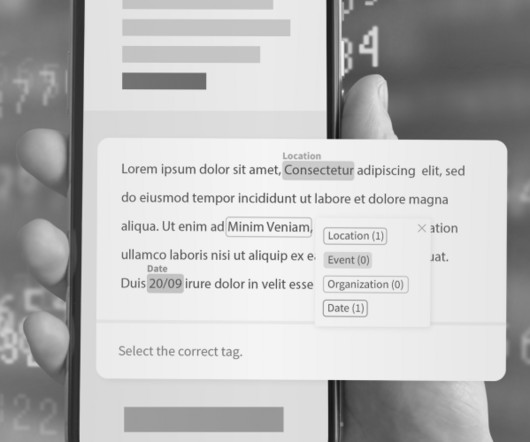
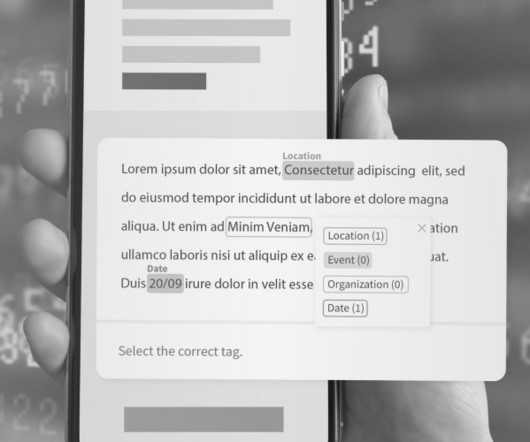
Another approach is to use machine learning algorithms, which can learn to identify and categorize named entities from a large corpus of labelled training data. These algorithms can be trained to recognize a wide range of named entities and can handle complex language, making them a more robust and flexible solution for NER.
Another approach is to use machine learning algorithms, which can learn to identify and categorize named entities from a large corpus of labelled training data. These algorithms can be trained to recognize a wide range of named entities and can handle complex language, making them a more robust and flexible solution for NER.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content