This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Building on this momentum is a dynamic research group at the heart of CDS called the Machine Learning and Language (ML²) group. By 2020, ML² was a thriving community, primarily known for its recurring speaker series where researchers presented their work to peers. What does it mean to work in NLP in the age of LLMs?
Every year, ODSC East brings together some of the brightest minds in datascience, AI, and machine learning. Michael Galarnyk, Learning Instructor | PhD Student at LinkedIn | GeorgiaTech Michael is a machine learning educator and PhD student at Georgia Tech researching ML for financial markets.
Generative AI to the rescuePhoto by Arif Riyanto on Unsplash I have recently been accepted as a writer for Towards AI, which is thrilling because the publication’s mission of “Making AI & ML accessible to all” resonates strongly with me. I believe that I have two key differentiators in “Making AI & ML Accessible to All.”
Both computer scientists and business leaders have taken note of the potential of the data. Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. MLOps is the next evolution of data analysis and deep learning. What is MLOps?
Measuring the quality of free text responses is not trivial compared to traditional ML models and requires semantic comparisons to approach parity with human evaluation. For example, we often have high volumes of objective data we can use to measure the quality of a model that predicts who might have diabetes.
Rupa, an AI/ML Solution Architect and Senior Data Scientist at Siemens championed the program and served as the primary organizer and Stuti, Lead Data Scientist at Samsung provided technical guidance and coordination throughout the 8 week program. We really appreciate you believing in us and providing us this opportunity.
Established in 2015, Getir has positioned itself as the trailblazer in the sphere of ultrafast grocery delivery. We capitalized on the powerful tools provided by AWS to tackle this challenge and effectively navigate the complex field of machine learning (ML) and predictive analytics. SageMaker is a fully managed ML service.
As newer fields emerge within datascience and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. Rumelhart Prize in 2015, and the ACM/AAAI Allen Newell Award in 2009. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Meesho was founded in 2015 and today focuses on buyers and sellers across India. We used AWS machine learning (ML) services like Amazon SageMaker to develop a powerful generalized feed ranker (GFR). SageMaker offered ease of deployment with support for various ML frameworks, allowing models to be served with low latency.
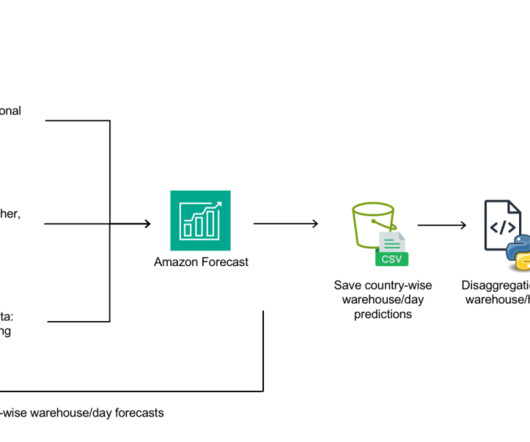
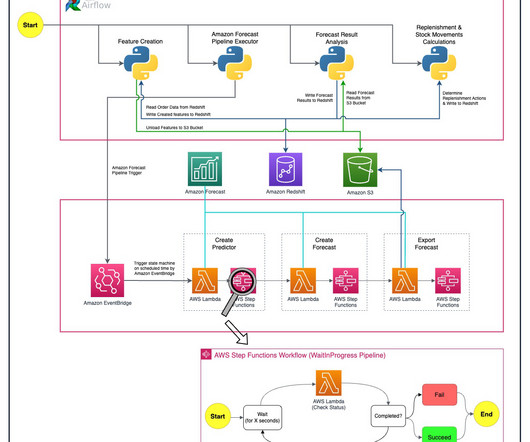
Getir was founded in 2015 and operates in Turkey, the UK, the Netherlands, Germany, and the United States. Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. Initially, daily forecasts for each country are formulated through ML models.
Just Do Something with AI: Bridging the Business Communication Gap forML This blog explores how ML practitioners can navigate AI business communication, ensuring AI initiatives align with real businessvalue. Looking back at almost 5000 conference sessions, how has the industrychanged? Learn more and apply to be a part of the eventhere.
But Docker lacked an automated “orchestration” tool, which made it time-consuming and complex for datascience teams to scale applications. Deploying machine learning on Kubernetes makes it easier for organizations to automate the management and scaling of ML lifecycles and reduces the need for manual intervention.
In today’s highly competitive market, performing data analytics using machine learning (ML) models has become a necessity for organizations. It enables them to unlock the value of their data, identify trends, patterns, and predictions, and differentiate themselves from their competitors.
Getir was founded in 2015 and operates in Turkey, the UK, the Netherlands, Germany, France, Spain, Italy, Portugal, and the United States. Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. Getir is the pioneer of ultrafast grocery delivery.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Datascience practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any datascience task then you definitely used pandas. So, pandas is a library which helps with performing data ingestion and transformations. apply(lambda x: x.year) df.groupby('year')['Sales'].mean() Latest order date.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). phData has been working in data engineering since the inception of the company back in 2015. Why is Snowpark Exciting to us?
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machine learning (ML) model from distributed health data held locally at different sites. Import the data loader into the training script.
The data file format comprises the Tweet’s polarity, IT, date, query, user and text. Twitter US Airline Sentiment Polarized Tweets from February 2015 about the large US airlines. Data is provided in a CSV file and SQLite database. Get the dataset here. Get the dataset here. Synonyms 12. Long-Form Content 14.
The Future of Data-centric AI virtual conference will bring together a star-studded lineup of expert speakers from across the machine learning, artificial intelligence, and datascience field. chief data scientist, a role he held under President Barack Obama from 2015 to 2017. Patil served as the first U.S.
The Future of Data-centric AI virtual conference will bring together a star-studded lineup of expert speakers from across the machine learning, artificial intelligence, and datascience field. chief data scientist, a role he held under President Barack Obama from 2015 to 2017. Patil served as the first U.S.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. He currently is working on Generative AI for data integration. Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. He is the author of the upcoming book “What’s Your Problem?”
The manufacturing industry can benefit from AI, data and machine learning to advance manufacturing quality and productivity, minimize waste and reduce costs. With ML, manufacturers can modernize their businesses through use cases like forecasting demand, optimizing scheduling, preventing malfunctioning and managing quality.
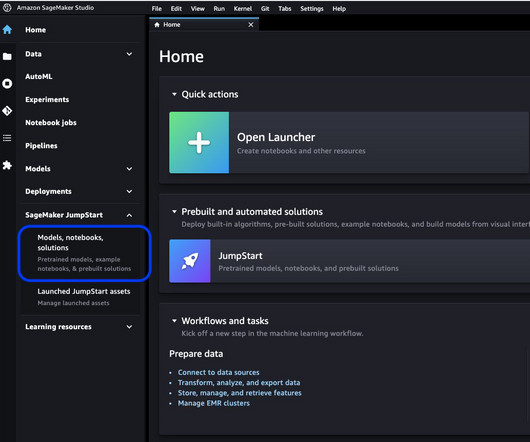
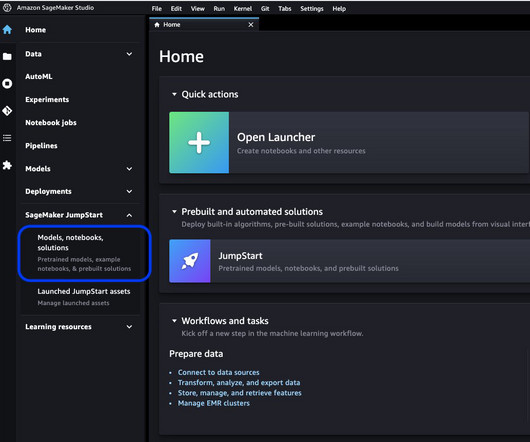
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
Insurance data is typically highly inaccessible: reports suggest that 80% of insurance data is unstructured, unlabelled, and not ready for AI model training. This means that an insurer’s ability to select, adopt and customise ML and Generative AI at scale will be a key competitive battleground.
Insurance data is typically highly inaccessible: reports suggest that 80% of insurance data is unstructured, unlabelled, and not ready for AI model training. This means that an insurer’s ability to select, adopt and customise ML and Generative AI at scale will be a key competitive battleground.
Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv preprint arXiv:1511.07122, 2015. [4] 4] Data source: [link] Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners.
This guarantees businesses can fully utilize deep learning in their AI and ML initiatives. You can make more informed judgments about your AI and ML initiatives if you know these platforms' features, applications, and use cases. Developed by François Chollet, it was released in 2015 to simplify the creation of deep learning models.
We provided a quick overview of Women in Big Data (WiBD). Launched in 2015 and becoming a nonprofit organization in 2020, WiBD is a grassroots initiative dedicated to inspiring, connecting, and advancing women in data fields. Currently, there is an ML Engineer Track, but no certification is available yet.
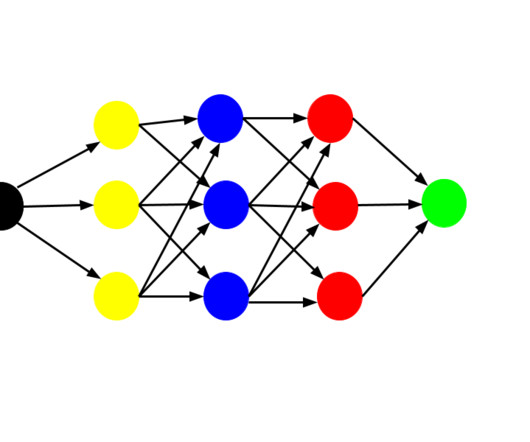
Andrew Jones of DataScience Infinity Imagine that you train a network to recognize pictures of a statue. Andrew Jones of DataScience Infinity This operation is repeated for every section of the image that a filter strides over. You then repeat that loop for each layer in your network.
SpaCy is a popular open-source NLP library developed in 2015 by Matthew Honnibal and Ines Montani, the founders of the software company Explosion. It provides a range of features for processing and analyzing text data. Developing a chatbot can be a complex task, but with the help of SpaCy, it can be made easier. What is SpaCy?
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
ResNet is a deep CNN architecture developed by Kaiming He and his colleagues at Microsoft Research in 2015. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners.
The plot shows that there has been a steady increase in the number of titles added each year, with a notable jump in 2015. Further Analysis From the first plot, we can see the frequency of content added by Netflix from 2008 to 2021. From the second plot, we can see the top 20 genres that have been added by Netflix from 2008 to 2021.
The Art of Forecasting in the Retail Industry Part I : Exploratory Data Analysis & Time Series Analysis In this article, I will conduct exploratory data analysis and time series analysis using a dataset consisting of product sales in different categories from a store in the US between 2015 and 2018.
In addition, we are also responsible for the Experimentation Platforms at Comcast and the products, the data platforms that kind of underlie all these AI and machine-learning applications, as well as our product analytics platforms that make it easier to train, develop, and manage models. The voice remote was launched for Comcast in 2015.
In addition, we are also responsible for the Experimentation Platforms at Comcast and the products, the data platforms that kind of underlie all these AI and machine-learning applications, as well as our product analytics platforms that make it easier to train, develop, and manage models. The voice remote was launched for Comcast in 2015.
Winning teams included individuals with expertise in computer science, engineering, biomedical informatics, neuroscience, psychology, datascience, sociology, and various clinical specialties. Many teams combined technical skills in AI/ML with domain knowledge in neuroscience, aging, or healthcare.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content