This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But Docker lacked an automated “orchestration” tool, which made it time-consuming and complex for datascience teams to scale applications. Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources.
Meesho was founded in 2015 and today focuses on buyers and sellers across India. Model training Meesho used Amazon EMR with Apache Spark to process hundreds of millions of data points, depending on the model’s complexity. One of the major challenges was to run distributed training at scale.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. Dr. Huan works on AI and DataScience. He focuses on developing scalable machine learning algorithms. Youngsuk Park is a Sr.
During a recent episode of ODSC’s Ai X Podcast with Paige Bailey, Engineering Lead for Gen AI Development Experience at Google, we delved into the groundbreaking AI tools and platforms that are shaping the future of datascience. Check out her talk, “ DataScience in the Age of Generative AI ,” there!
Getir was founded in 2015 and operates in Turkey, the UK, the Netherlands, Germany, France, Spain, Italy, Portugal, and the United States. Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. Getir is the pioneer of ultrafast grocery delivery.
The data file format comprises the Tweet’s polarity, IT, date, query, user and text. Twitter US Airline Sentiment Polarized Tweets from February 2015 about the large US airlines. Data is provided in a CSV file and SQLite database. Get the dataset here. Get the dataset here. Synonyms 12. Get the dataset here.
Explore the model pre-training workflow from start to finish, including setting up clusters, troubleshooting convergence issues, and running distributed training to improve model performance. Gain hands-on experience in data management, model training, monitoring, and seamless deployment to production environments.
OpenAI, a company Musk co-founded in 2015, introduced its GPT-4-based model, the o1, last year, which showcased strong problem-solving abilities in coding, math, andscience. The company disclosed Tuesday that it had doubled its GPU cluster to 200,000 Nvidia units for Grok 3s training, up from 100,000 in2023. Whats Next?
We think those workloads fall into three broad categories: DataScience and Machine Learning – Data Scientists love Python, which makes Snowpark Python an ideal framework for machine learning development and deployment. phData has been working in data engineering since the inception of the company back in 2015.
Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. He currently is working on Generative AI for data integration.
per diluted share, for the year ended December 31, 2015. per diluted share, for the year ended December 31, 2015. per diluted share, for the year ended December 31, 2015. per diluted share, for the year ended December 31, 2015. per diluted share, compared to $3,818,000, or $0.21
If you spend even a few minutes on KNIME’s website or browsing through their whitepapers and blog posts, you’ll notice a common theme: a strong emphasis on datascience and predictive modeling. Predicting Crimes in Phoenix, Arizona We have a dataset containing nearly 400,000 crimes committed in Phoenix, Arizona between 2015 and 2021.
They were admitted to one of 335 units at 208 hospitals located throughout the US between 2014–2015. Due to the underlying heterogeneity and distributed nature of the data, it provides an ideal real-world example to test this FL framework. Please follow the steps listed here to install wandb and setup monitoring for this solution.
per diluted share, for the year ended December 31, 2015. per diluted share, for the year ended December 31, 2015. per diluted share, for the year ended December 31, 2015. per diluted share, for the year ended December 31, 2015. per diluted share, compared to $3,818,000, or $0.21
Overview of TensorFlow TensorFlow , developed by Google Brain, is a robust and versatile deep learning framework that was introduced in 2015. Scalability TensorFlow can handle large datasets and scale to distributed clusters, making it suitable for training complex models.
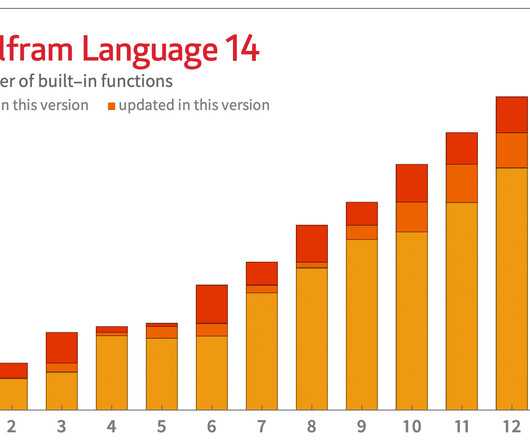
One very simple example (introduced in 2015) is Nothing : Another, introduced in 2020, is Splice : An old chestnut of Wolfram Language design concerns the way infinite evaluation loops are handled. but with things like clustering). And in Version 13.2 We’ve had “basic, raw NDSolve ” since 1991.
Most solvers were datascience professionals, professors, and students, but there were also many data analysts, project managers, and people working in public health and healthcare. His journey in AI began in 2015 with a master's in computer vision for biomedical image analysis. Alejandro A.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





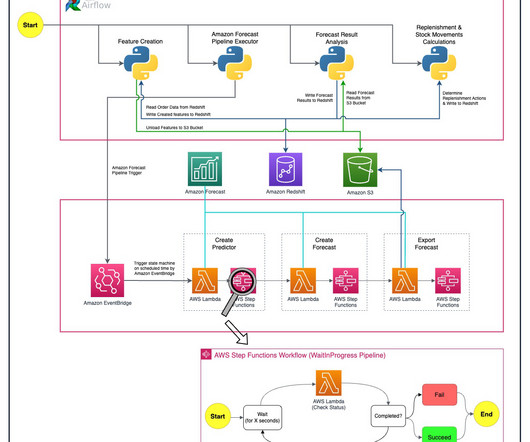




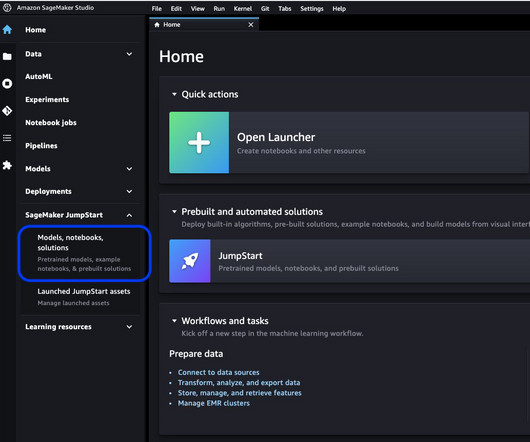
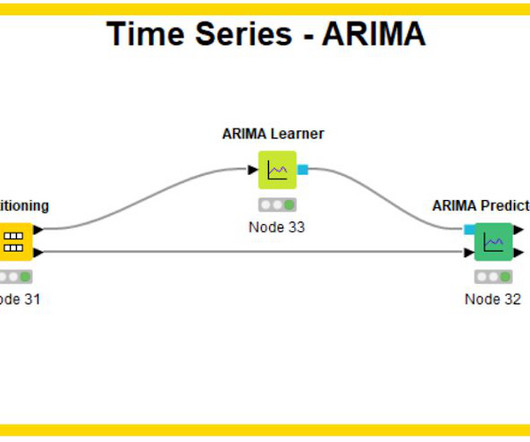









Let's personalize your content