This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Explore the model pre-training workflow from start to finish, including setting up clusters, troubleshooting convergence issues, and running distributed training to improve model performance. In this builders’ session, learn how to pre-train an LLM using Slurm on SageMaker HyperPod.
He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and ArtificialIntelligence. Dhawal Patel is a Principal Machine Learning Architect at AWS. He focuses on Deep learning including NLP and Computer Vision domains.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. In 2015, Google donated Kubernetes as a seed technology to the Cloud Native Computing Foundation (CNCF) (link resides outside ibm.com), the open-source, vendor-neutral hub of cloud-native computing.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. From 2015–2018, he worked as a program director at the US NSF in charge of its big data program. Youngsuk Park is a Sr.
The science behind Swarm Robotics The science behind swarm robotics is based on the principles of swarm intelligence. Swarm intelligence is a type of artificialintelligence that is inspired by the behavior of social insects. In 2015, a swarm of robots was used to search for survivors after the Nepal earthquake.
Elon Musks artificialintelligence company, xAI, has introduced its latest model, Grok 3, which the company asserts outperforms rival systems from OpenAI and Chinas DeepSeek in early evaluations. The company disclosed Tuesday that it had doubled its GPU cluster to 200,000 Nvidia units for Grok 3s training, up from 100,000 in2023.
SnapLogic’s AI journey In the realm of integration platforms, SnapLogic has consistently been at the forefront, harnessing the transformative power of artificialintelligence. Dr. Farooq Sabir is a Senior ArtificialIntelligence and Machine Learning Specialist Solutions Architect at AWS. Sandeep holds an MSc.
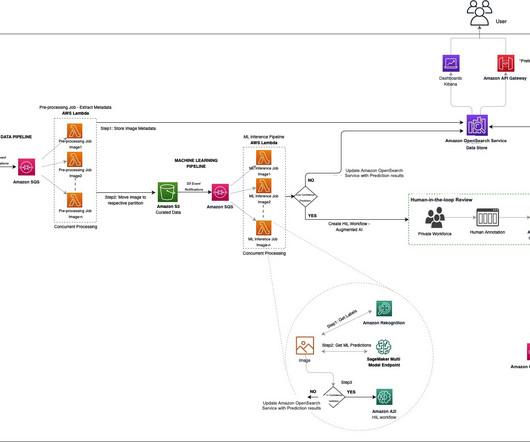
This dataset consists of human and machine annotated airborne images collected by the Civil Air Patrol in support of various disaster responses from 2015-2019. To train this model, we need a labeled ground truth subset of the Low Altitude Disaster Imagery (LADI) dataset. Given the highly parallel needs, we chose Lambda to process our images.
Introduction to Machine Learning Frameworks In the present world, almost every organization is making use of machine learning and artificialintelligence in order to stay ahead of the competition. It is an open source framework that has been available since April 2015. Allows clustering of unstructured data.
Figure 4: The Netflix personalized home page generation problem (source: Alvino and Basilico, “Learning a Personalized Homepage,” Netflix Technology Blog , 2015 ). Green ticks represent the relevant titles (source: Alvino and Basilico, “Learning a Personalized Homepage,” Netflix Technology Blog , 2015 ). And that’s exactly what I do.
The Evolution of AI Tools at Google Since the release of TensorFlow in 2015, Google has been pushing the boundaries of what is possible with AI and machine learning. Paige explained that Gemini models are used not only for code generation but also for tasks like video analysis and data clustering.
Overview of TensorFlow TensorFlow , developed by Google Brain, is a robust and versatile deep learning framework that was introduced in 2015. Scalability TensorFlow can handle large datasets and scale to distributed clusters, making it suitable for training complex models.
Glushkov Institute of Cybernetics of the National Academy of Sciences (NAS) of Ukraine, working on early artificialintelligence systems and cybernetic theory. According to associates, his decision was directly influenced by mapping UFO sighting clusters and abduction reports across the United States.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content