This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataquality is ownership of the consuming applications or data producers. Governance The two key areas of governance are model and data: Model governance Monitor model for performance, robustness, and fairness. Bharathi Srinivasan is a Generative AI Data Scientist at the AWS Worldwide Specialist Organization.
The OpenEPT database infrastructure will facilitate collaboration between engineers and researchers by promoting data exchange. We will reassess and improve the performance of Verilog behavioural models and revise the mixed mode simulation algorithm.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Users Amazon Personalize need to upload data containing their own customer’s interactions in order for the model to be able to learn these behavioral trends. Choose the plus sign next to the final step on the data flow and choose Add analysis. For Analysis type ¸ choose DataQuality And Insights Report for Amazon Personalize.
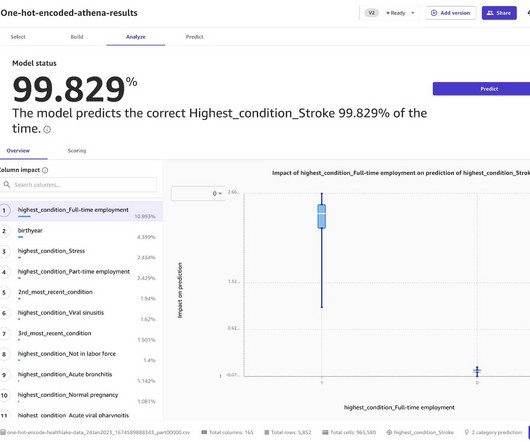
One of the challenges of working with categorical data is that it is not as amenable to being used in many machine learning algorithms. To overcome this, we use one-hot encoding, which converts each category in a column to a separate binary column, making the data suitable for a wider range of algorithms.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
If you piece the words, data and AI together, you cover quite broad, expansive methods and techniques and applications and systems. So we’re going to be hearing about lots of topics. Again, if you want to go deeper, there are lots online and in the literature about it that we and others now have worked on.
If you piece the words, data and AI together, you cover quite broad, expansive methods and techniques and applications and systems. So we’re going to be hearing about lots of topics. Again, if you want to go deeper, there are lots online and in the literature about it that we and others now have worked on.
Importance and Role of Datasets in Machine Learning Data is king. Algorithms are important and require expert knowledge to develop and refine, but they would be useless without data. These datasets, essentially large collections of related information, act as the training field for machine learning algorithms.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content