
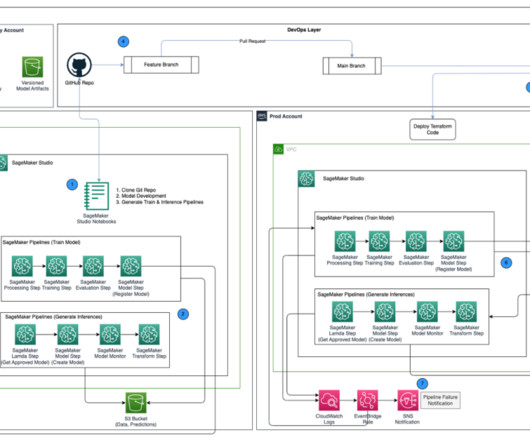
Promote pipelines in a multi-environment setup using Amazon SageMaker Model Registry, HashiCorp Terraform, GitHub, and Jenkins CI/CD
AWS Machine Learning Blog
NOVEMBER 9, 2023
Policy 3 – Attach AWSLambda_FullAccess , which is an AWS managed policy that grants full access to Lambda, Lambda console features, and other related AWS services.








Let's personalize your content