This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 Vision models. WASHINGTON, D.
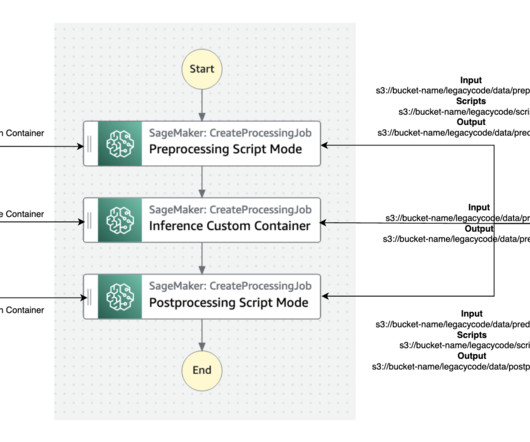
The term legacy code refers to code that was developed to be manually run on a local desktop, and is not built with cloud-ready SDKs such as the AWS SDK for Python (Boto3) or Amazon SageMaker Python SDK. The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK.
If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
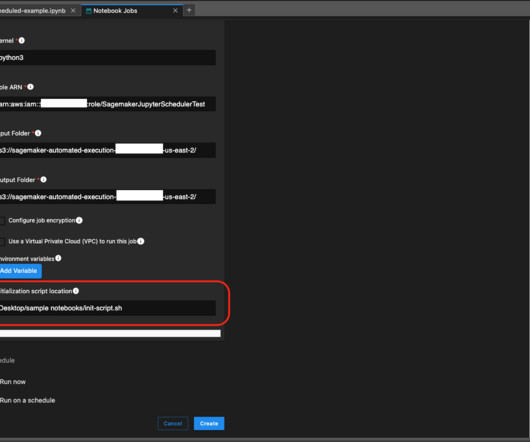
In addition to the IAM user and assumed role session scheduling the job, you also need to provide a role for the notebook job instance to assume for access to your data in Amazon Simple Storage Service (Amazon S3) or to connect to Amazon EMR clusters as needed. Prerequisites For this post, we assume a locally hosted JupyterLab environment.
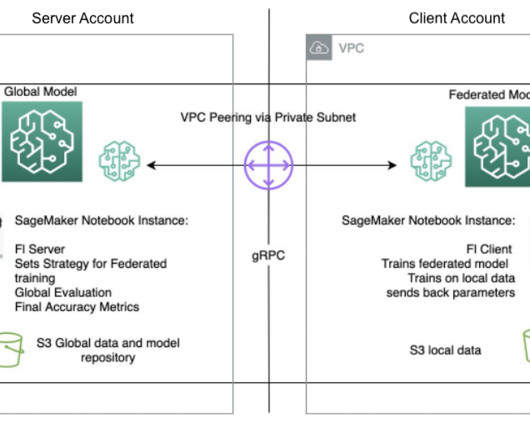
Usually, if the dataset or model is too large to be trained on a single instance, distributed training allows for multiple instances within a cluster to be used and distribute either data or model partitions across those instances during the training process. Each account or Region has its own training instances.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases. Work by Hinton et al.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. Choose the Redshift cluster associated with the secrets.
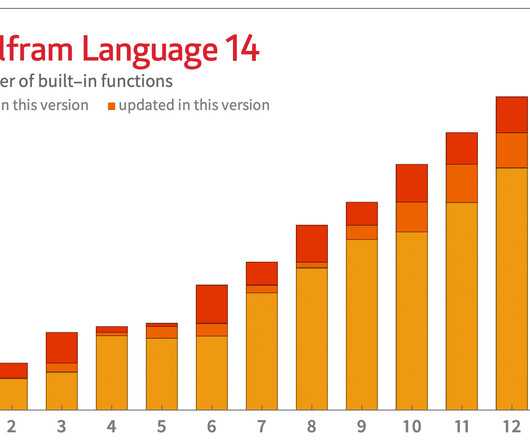
And in 2012 we introduced Quantity to represent quantities with units in the Wolfram Language. but with things like clustering). There’s one setup for interpreted languages like Python. Let’s start with Python. We’ve had ExternalEvaluate for evaluating Python code since 2018. But in Version 14.0
Some might also wonder how I get Python code to run so fast. This makes it easy to achieve the performance of native C code, but allows the use of Python language features, via the Python C API. The Python unicode library was particularly useful to me. Here is what the outer-loop would look like in Python.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., 2012; Otsu, 1979; Long et al., Methodology In this study, we used the publicly available PASCAL VOC 2012 dataset (Everingham et al., References: Arbeláez, P.,
spaCy is a new library for text processing in Python and Cython. The only problem is that the list really contains two clusters of words: one associated with the legal meaning of “pleaded”, and one for the more general sense. Sorting out these clusters is an area of active research.
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well. data # Assing local directory path to a python variable local_data_path = "./data/" This was created in Step-2 above.
It's a programming language designed for writing good CLI scripts, so it's aiming to replace Bash but is much more Python-like, and offers unique syntax and a bunch of in-built support for scripting. Uses lldb's Python scripting extensions to register commands, and handle memory access.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content