This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. If enabled, its status will display as Access granted.
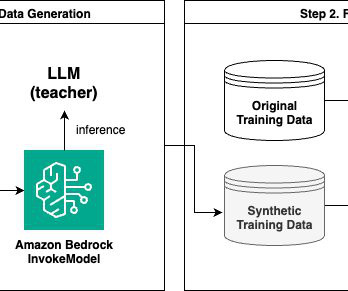
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machinelearning (ML) initiatives. Athena uses the Athena Google BigQuery connector , which uses a pre-built AWS Lambda function to enable Athena federated query capabilities.
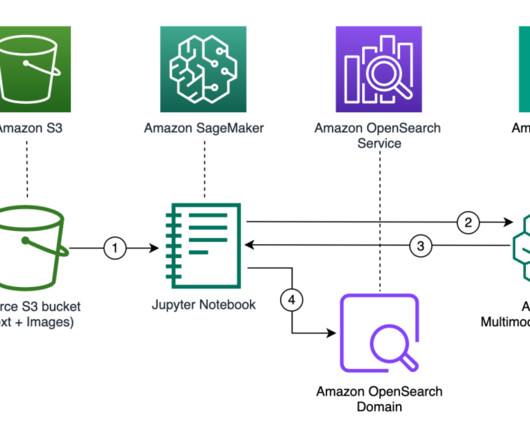
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. Its a fully managed service that you can use to deploy, operate, and scale OpenSearch on AWS. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account. Ingest sample data to the OpenSearch Service index.
SageMaker Unified Studio brings together the functionality and tools from existing AWS analytics and AI/ML services, including Amazon EMR , AWS Glue , Amazon Athena , Amazon Redshift , Amazon Bedrock, and Amazon SageMaker AI. To learn more, refer to Amazon Bedrock in SageMaker Unified Studio.
Managing access control in enterprise machinelearning (ML) environments presents significant challenges, particularly when multiple teams share Amazon SageMaker AI resources within a single Amazon Web Services (AWS) account.
AWS recently announced the general availability of Amazon Bedrock Data Automation , a feature of Amazon Bedrock that automates the generation of valuable insights from unstructured multimodal content such as documents, images, video, and audio. Amazon Bedrock Data Automation serves as the primary engine for information extraction.
SageMaker JumpStart helps you get started with machinelearning (ML) by providing fully customizable solutions and one-click deployment and fine-tuning of more than 400 popular open-weight and proprietary generative AI models. To access SageMaker Studio on the AWS Management Console , you need to set up an Amazon SageMaker domain.
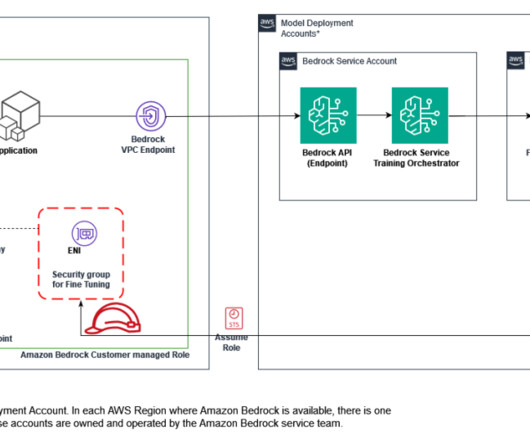
Security in Amazon Bedrock Cloud security at AWS is the highest priority. The workflow steps are as follows: The user submits an Amazon Bedrock fine-tuning job within their AWS account, using IAM for resource access. The VPC is equipped with private endpoints for Amazon S3 and AWS KMS access, enhancing overall security.
At the AWS Summit in New York City , we introduced a comprehensive suite of model customization capabilities for Amazon Nova foundation models. To do so, use the AWS CLI or AWS SDK to delete it. Product Marketing Manager on the AIML team at AWS. You can use JupyterLab in your local setup, too.)
Enter a unique name and choose the AWS Region where you want to host the bucket. We use the AWS SDK for Python (Boto3) to interact with Amazon S3 and Amazon Bedrock. About the Authors Jordan Jones is a Solutions Architect at AWS within the Cloud Sales Center organization. Choose Create bucket. Create your bucket.
Scaling machinelearning (ML) workflows from initial prototypes to large-scale production deployment can be daunting task, but the integration of Amazon SageMaker Studio and Amazon SageMaker HyperPod offers a streamlined solution to this challenge. Make sure you have the latest version of the AWS Command Line Interface (AWS CLI).
The solution uses the AWS Cloud Development Kit (AWS CDK) to deploy the solution components. The AWS CDK is an open source software development framework for defining cloud infrastructure as code and provisioning it through AWS CloudFormation. Use either the us-west-2 or us-east-1 AWS Region.
Amazon SageMaker Ground Truth is a powerful data labeling service offered by AWS that provides a comprehensive and scalable platform for labeling various types of data, including text, images, videos, and 3D point clouds, using a diverse workforce of human annotators. Virginia) AWS Region. The bucket should be in the US East (N.
Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account. model customization is available in the US West (Oregon) AWS Region. Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. Applied Scientist in AWS Agentic AI. Meta Llama 3.2
Amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining optimal performance and availability. We provide practical examples for both SCP modifications and AWS Control Tower implementations.
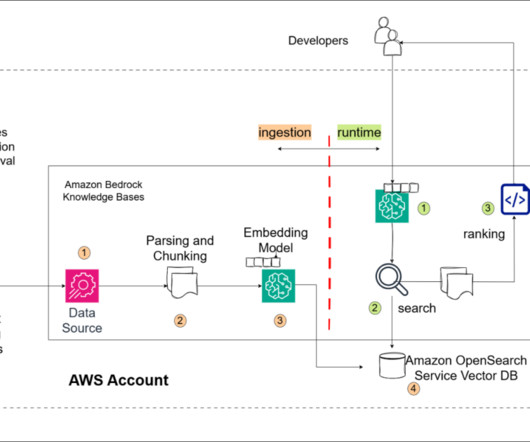
The walkthrough follows these high-level steps: Create a new knowledge base Configure the data source Configure data source and processing Sync the data source Test the knowledge base Prerequisites Before you get started, make sure that you have the following prerequisites: An AWS Account with appropriate service access. Choose Amazon S3.
For instance, a developer setting up a continuous integration and delivery (CI/CD) pipeline in a new AWS Region or running a pipeline on a dev branch can quickly access Adobe-specific guidelines and best practices through this centralized system. Building on these learnings, improving retrieval precision emerged as the next critical step.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machinelearning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
Today, we’re excited to introduce a comprehensive approach to model evaluation through the Amazon Nova LLM-as-a-Judge capability on Amazon SageMaker AI , a fully managed Amazon Web Services (AWS) service to build, train, and deploy machinelearning (ML) models at scale. You can use JupyterLab in your local setup, too.)
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. You need the following prerequisite resources: An AWS account.
At Amazon Web Services (AWS), we recognize that many of our customers rely on the familiar Microsoft Office suite of applications, including Word, Excel, and Outlook, as the backbone of their daily workflows. Using AWS, organizations can host and serve Office Add-ins for users worldwide with minimal infrastructure overhead.
You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment. These connections are stored in the AWS Glue Data Catalog (Data Catalog) and registered with Lake Formation, allowing you to create a federated catalog for each available data source.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage any infrastructure. Our dataset includes Q&A pairs with reference documents regarding AWS services.
Amazon SageMaker JumpStart is a machinelearning (ML) hub that provides pre-trained models, solution templates, and algorithms to help developers quickly get started with machinelearning. HUB_DISPLAY_NAME is the display name for your hub that will be shown to users in UI experiences.
Some companies go to great lengths to maintain confidentiality, sometimes adopting multi-account architectures, where each customer has their data in a separate AWS account. Constantly requesting and monitoring quota for invoking foundation models on Amazon Bedrock becomes a challenge when the number of AWS accounts reaches double digits.
https://dev.to/freakynit/aws-networking-tutorial-38c1 - https://dev.to/freakynit/building-a-minimum-viable-product-m. reply tootyskooty 12 hours ago | root | parent | next [–] Yeah, doesn't work for generating language-learning content yet. In which case lookup.dev is for sale … just fyi.
Tens of thousands of AWS customers use AWSmachinelearning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit.
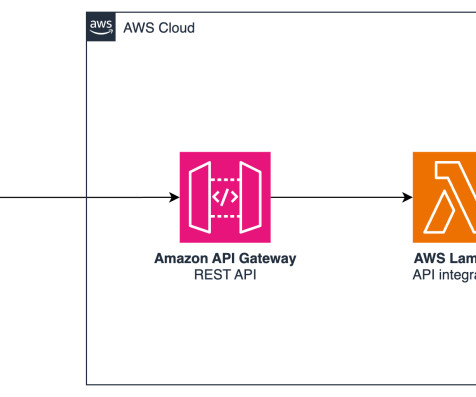
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. The workflow steps are as follows: AWS Lambda running in your private VPC subnet receives the prompt request from the generative AI application.
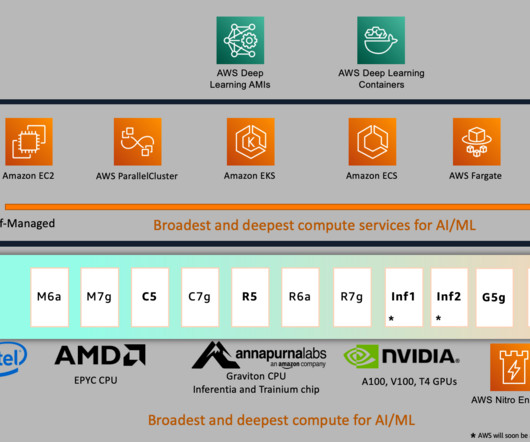
Innovation built on AWS core strengths Bringing NVIDIA Blackwell to AWS isn’t about a single breakthrough—it’s about continuous innovation across multiple layers of infrastructure. NVIDIA DGX Cloud on AWS P6e-GB200 UltraServers will also be available through NVIDIA DGX Cloud. We can’t wait to see what you will build with them.
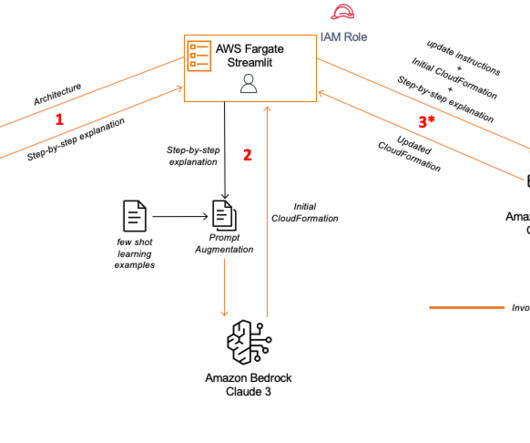
Architecting specific AWS Cloud solutions involves creating diagrams that show relationships and interactions between different services. Instead of building the code manually, you can use Anthropic’s Claude 3’s image analysis capabilities to generate AWS CloudFormation templates by passing an architecture diagram as input.
It employs advanced deep learning technologies to understand user input, enabling developers to create chatbots, virtual assistants, and other applications that can interact with users in natural language. Version control – With AWS CloudFormation, you can use version control systems like Git to manage your CloudFormation templates.
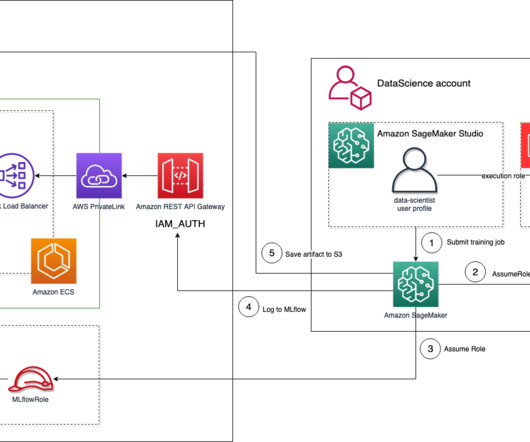
With Amazon SageMaker , you can manage the whole end-to-end machinelearning (ML) lifecycle. In a previous post , we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure.
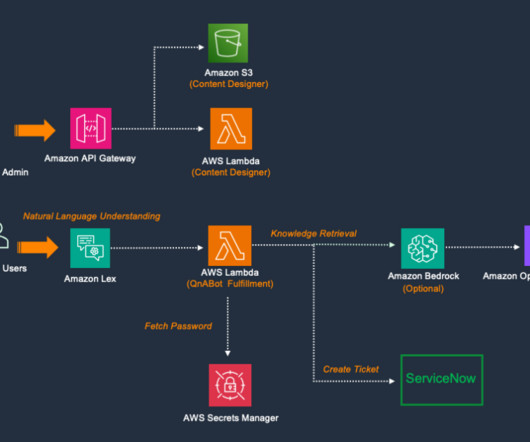
QnABot on AWS is an open source solution built using AWS native services like Amazon Lex , Amazon OpenSearch Service , AWS Lambda , Amazon Transcribe , and Amazon Polly. In this post, we demonstrate how to integrate the QnABot on AWS chatbot solution with ServiceNow. QnABot version 5.4+ Provide a name for the bot.
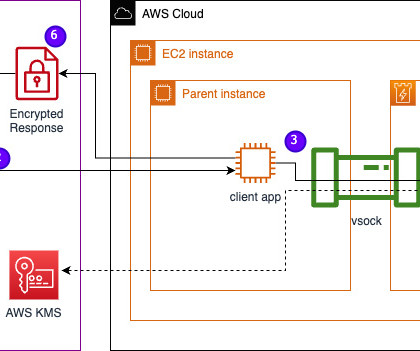
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. The steps carried out during the inference are as follows: The chatbot app generates temporary AWS credentials and asks the user to input a question. hvm-2.0.20230628.0-x86_64-gp2
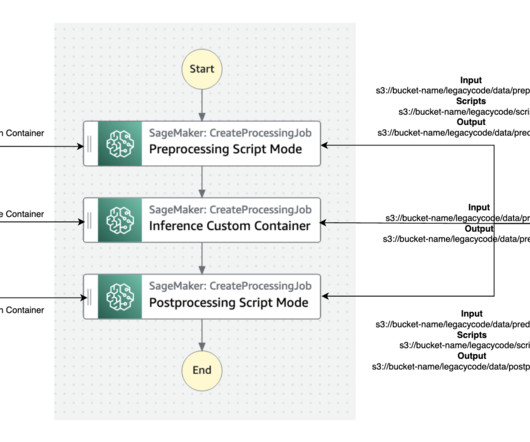
Amazon SageMaker Pipelines is a fully managed AWS service for building and orchestrating machinelearning (ML) workflows. You can use SageMaker Pipelines to orchestrate ML jobs in SageMaker, and its integration with the larger AWS ecosystem also allows you to use resources like AWS Lambda functions, Amazon EMR jobs, and more.
Prerequisites To run this step-by-step guide, you need an AWS account with permissions to SageMaker, Amazon Elastic Container Registry (Amazon ECR), AWS Identity and Access Management (IAM), and AWS CodeBuild. Complete the following steps: Sign in to the AWS Management Console and open the IAM console.
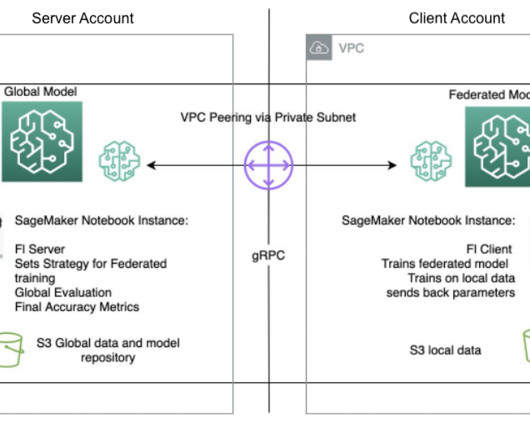
Machinelearning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. In this post, we demonstrate how to use the managed ML platform to provide a notebook experience environment and perform federated learning across AWS accounts, using SageMaker training jobs.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machinelearning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
Advancements in artificial intelligence (AI) and machinelearning (ML) are revolutionizing the financial industry for use cases such as fraud detection, credit worthiness assessment, and trading strategy optimization. It enables secure, high-speed data copy between same-Region access points using AWS internal networks and VPCs.
PyTorch is a machinelearning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 DLAMI + DLC.
In addition to Amazon Bedrock, you can use other AWS services like Amazon SageMaker JumpStart and Amazon Lex to create fully automated and easily adaptable generative AI order processing agents. In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda.
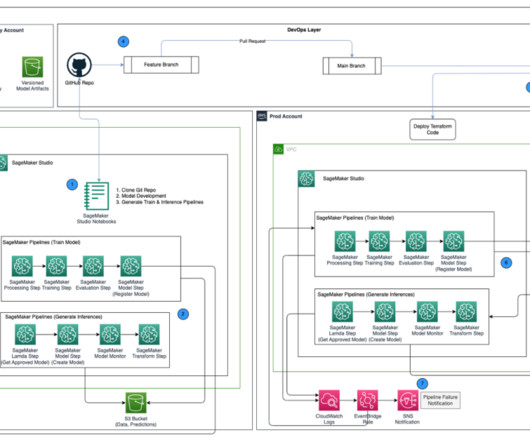
Building out a machinelearning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machinelearning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content