This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
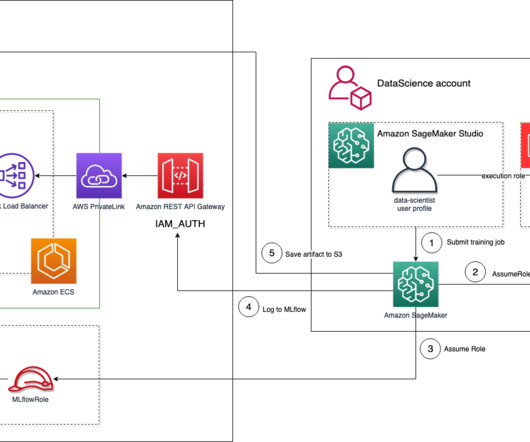
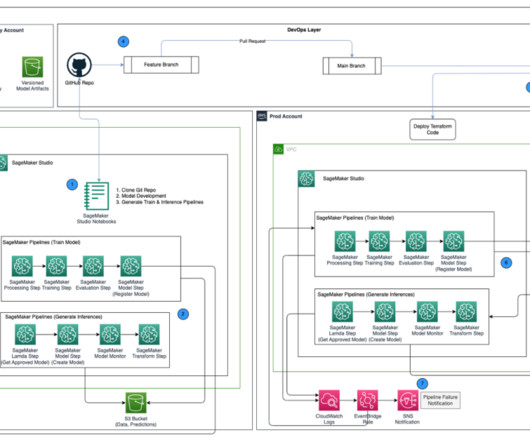
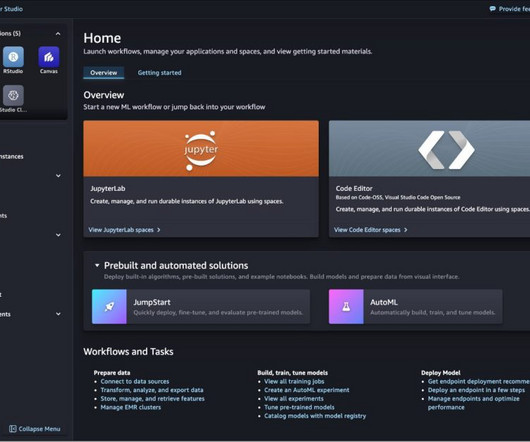
In a previous post , we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK).
Prerequisites To run this step-by-step guide, you need an AWS account with permissions to SageMaker, Amazon Elastic Container Registry (Amazon ECR), AWS Identity and Access Management (IAM), and AWS CodeBuild. Complete the following steps: Sign in to the AWS Management Console and open the IAM console.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined datascience experience within the Amazon SageMaker ecosystem. This same interface is also used for provisioning EMR clusters.
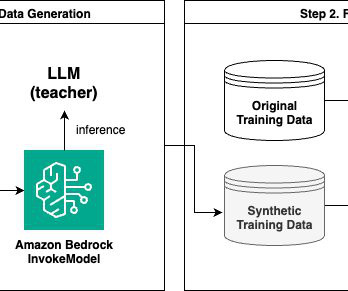
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage any infrastructure. Our dataset includes Q&A pairs with reference documents regarding AWS services.
During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
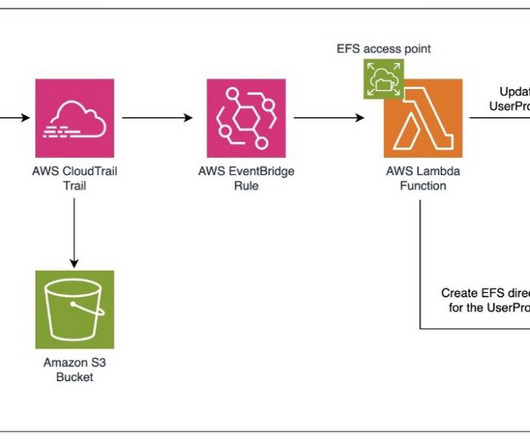
Amazon EFS provides a scalable fully managed elastic NFS file system for AWS compute instances. Using this folder, users can share data between their own private spaces. This means that each user within the domain will have their own private space on the EFS file system, allowing them to store and access their own data and files.
A common enterprise scenario involves centralized datascience teams developing foundation models (FMs), evaluating the performance against open source FMs, and iterating on performance. To learn more about how to manage models using private hubs, see Manage Amazon SageMaker JumpStart foundation model access with private hubs.
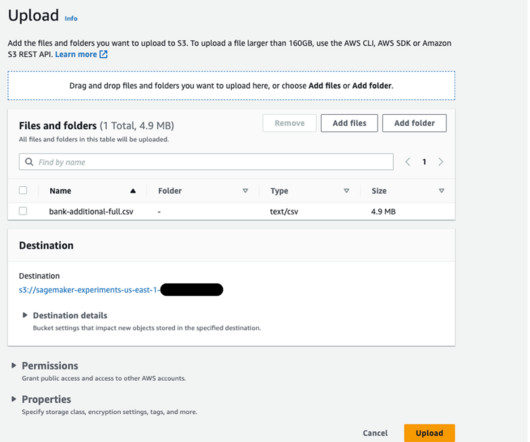
Solution Overview Imagine you, as an administrator, have to manage data for multiple datascience teams running their own data preparation workflows in SageMaker Data Wrangler. We demonstrate how to use S3 Access Points with SageMaker Data Wrangler with the following steps: Upload data to an S3 bucket.
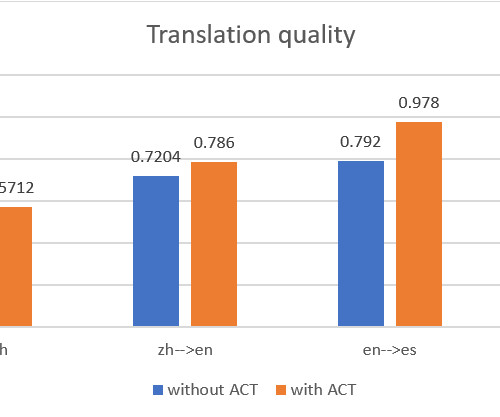
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. In this post, we present a solution that D2L.ai
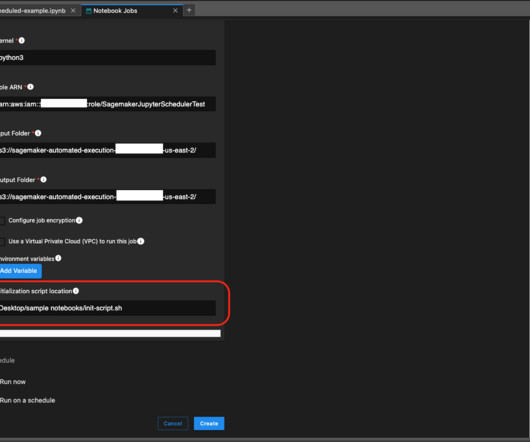
To run this job repeatedly on a schedule, you had to set up, configure, and oversee cloud infrastructure to automate deployments, resulting in a diversion of valuable time away from core datascience development activities. Install the AWS Command Line Interface (AWS CLI) if you don’t already have it installed.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
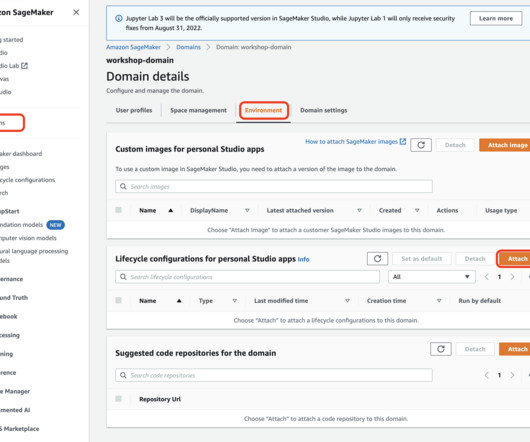
You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). The Studio Image Build CLI lets you build SageMaker-compatible Docker images directly from your Studio environments by using AWS CodeBuild. Environments without internet access.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
Launch of Kepler Architecture: NVIDIA launched the Kepler architecture in 2012. Collaborations with leading tech giants – AWS, Microsoft, and Google among others – paved the way to expand NVIDIA’s influence in the AI market. Its parallel processing capability made it a go-to choice for developers and researchers.
You need to grant your users permissions for private spaces and user profiles necessary to access these private spaces. This means that if the file system is provisioned at a root or prefix level within the domain, these settings will automatically apply to the space created by the domain users.
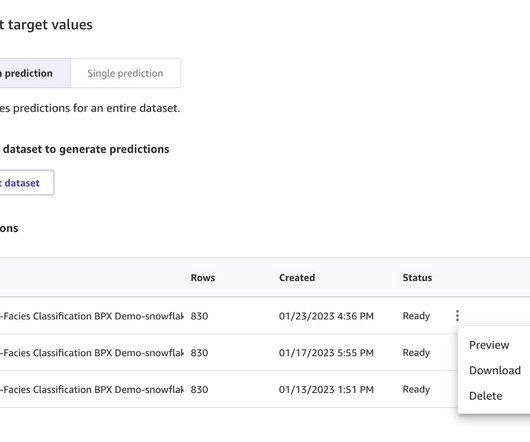
Solution overview Our solution consists of the following steps: Upload facies CSV data from your local machine to Snowflake. For this post, we use data from the following open-source GitHub repo. Configure AWS Identity and Access Management (IAM) roles for Snowflake and create a Snowflake integration. A Snowflake account.
Pedro Domingos, PhD Professor Emeritus, University Of Washington | Co-founder of the International Machine Learning Society Pedro Domingos is a winner of the SIGKDD Innovation Award and the IJCAI John McCarthy Award, two of the highest honors in datascience and AI.
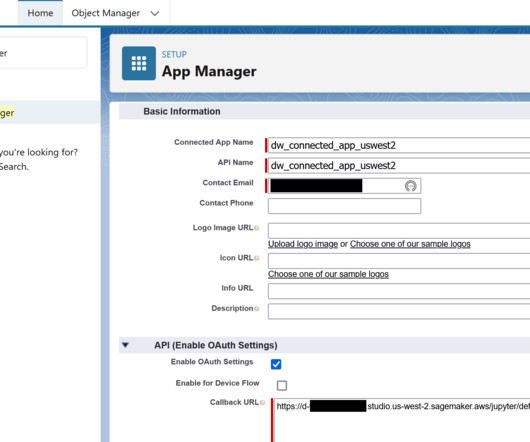
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. The endpoint will be exposed to Salesforce Data Cloud as an API through API Gateway.
During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
The number of annual data breaches gets higher each year. In 2012, records show there were 447 data breaches in the United States. Ten years later, in 2022, researchers recorded 1,800 cases of data compromise. million data records were leaked. The discovery process includes data mapping as well.
Since DataRobot was founded in 2012, we’ve been committed to democratizing access to the power of AI. We’re building a platform for all users: data scientists, analytics experts, business users, and IT. Let’s dive into each of these areas and talk about how we’re delivering the DataRobot AI Cloud Platform with our 7.2
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Datascience practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
Dabei arbeiten wir technologie-offen und mit nahezu allen Tools – Und oft in enger Verbindung mit Initiativen der Business Intelligence und DataScience. Gemeinsam haben sie alle die Funktion als Zwischenebene zwischen den Datenquellen und den Process Mining, BI und DataScience Applikationen.
Our professional work involves processing and analyzing medical data, particularly focusing on image and audio data. Beyond our primary roles, we are enthusiastic participants in datascience competitions and have achieved multiple victories in these contests. Fangjing Wu is a datascience master's student.
Amazon Web Services (AWS) provides highly optimized and cost-effective solutions for deploying AI models, like the Mixtral 8x7B language model, for inference at scale. This post demonstrates how to deploy and serve the Mixtral 8x7B language model on AWS Inferentia2 instances for cost-effective, high-performance inference.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content