
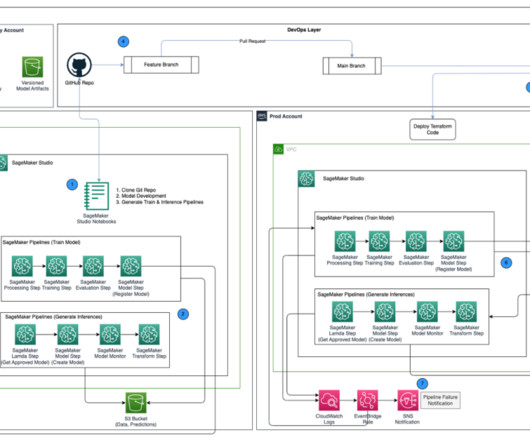
Promote pipelines in a multi-environment setup using Amazon SageMaker Model Registry, HashiCorp Terraform, GitHub, and Jenkins CI/CD
AWS Machine Learning Blog
NOVEMBER 9, 2023
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.








Let's personalize your content