This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Adaptive Gradient Algorithm (AdaGrad) represents a significant stride in optimization techniques, particularly in the realms of machine learning and deep learning. What is the Adaptive Gradient Algorithm (AdaGrad)? Its innovative mechanisms quickly gained traction among researchers and practitioners in the field.
Scientists interested in this latter approach were also represented at Dartmouth and later championed the rise of symbolic logic, using heuristic and algorithmic processes, which I’ll discuss in a bit. The program relied on early ideas of symbolic logic, with algorithmic steps and heuristic guidance in list form.
It has been over a decade since the Federal Reserve Board (FRB) and the Office of the Comptroller of the Currency (OCC) published its seminal guidance focused on Model Risk Management ( SR 11-7 & OCC Bulletin 2011-12 , respectively). With this definition of model risk, how do we ensure the models we build are technically correct?
Aristotle’s ideas on logic and rationality have influenced the development of algorithms and reasoning systems in modern AI, creating the foundation of the timeline of artificial intelligence. AI-powered robots are equipped with sensors, perception systems, and decision-making algorithms to perceive and interact with their environment.
Some of his early published work on the question, from 2011 and 2012, raises questions about what shape those models will take, and how hard it would be to make developing them go well — all of which will only look more important with a decade of hindsight. I think many plausible regulations have a lot of downsides and may not succeed.
Today, almost all high-performance parsers are using a variant of the algorithm described below (including spaCy). There are lots of problems to solve to make that work, but some sort of syntactic representation is definitely necessary. But the parsing algorithm I’ll be explaining deals with projective trees.
And in fact the big breakthrough in “deep learning” that occurred around 2011 was associated with the discovery that in some sense it can be easier to do (at least approximate) minimization when there are lots of weights involved than when there are fairly few. First comes the embedding module. But that’s not the case.
TensorFlow implements a wide range of deep learning and machine learning algorithms and is well-known for its adaptability and extensive ecosystem. In finance, it's applied for fraud detection and algorithmic trading. In 2011, H2O.ai Notable Use Cases TensorFlow is widely used in various industries.
In 2011, deep learning methods were proving successful for NLP, and techniques for pretraining word representations were already in use. This is exactly what algorithms like word2vec, GloVe and FastText set out to solve. release also has some quiet improvements that will help set the stage for better support for these languages.
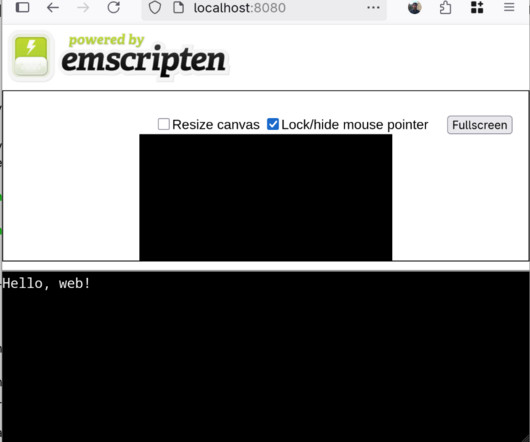
I am not sure about this, but if it is, it is definitely not a normal one. Interestingly, Emscripten, the compiler we are using to translate our C code to WASM, first appeared in 2011, predating WASM by a few years. So, what is this blog post? A tutorial for web development?
And so were in a position to compare the results of human effort (aided, in many cases, by systematic search) with what we can automatically do by the algorithmic process of adaptive evolution. Butas was actually already realized in the mid-1990sits still possible to use algorithmic methods to fill in pieces of patterns.
He graduated in 2011 from IISERs five-year dual science degree program with bachelors and masters degrees, with a concentration in mathematics. The existing algorithms were not efficient. In most cases, there is no definitive right or wrong answer, he says.
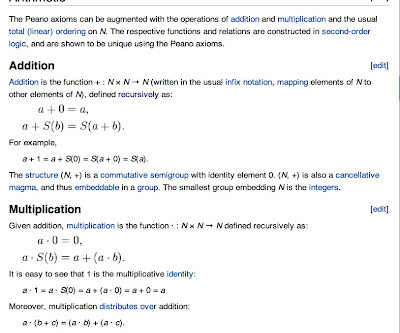
My comments refer to the pages when I accessed them on October 31, 2011.] Those articles appeared on MAA Online in June 2008 , July-August 2008 , September 2008 , and January 2011. The definition is actually not difficult, provided you are used to working in abstract set theory. Many sources gloss over it. P(a,0) = a 2.
1982 While still in school, publishes a paper in a youth science journal detailing an algorithm for generating “conversational responses that create the illusion of understanding,” essentially an early chatbot concept. 2011-2013 Expands operations to include multiple locations across the Southwest.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content