This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. The structured dataset includes order information for products spanning from 2010 to 2017.
Full list of new or updated datasets This dataset joins 33 other new or updated datasets on the Registry of Open Data in four categories: climate and weather, geospatial, life sciences, and machine learning (ML). 94-171) Demonstration Noisy Measurement File from United States Census Bureau What are people doing with open data?
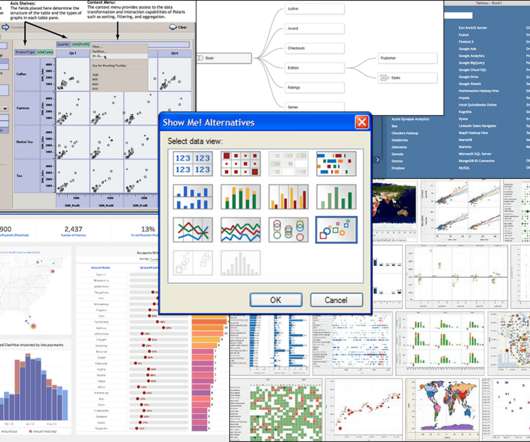
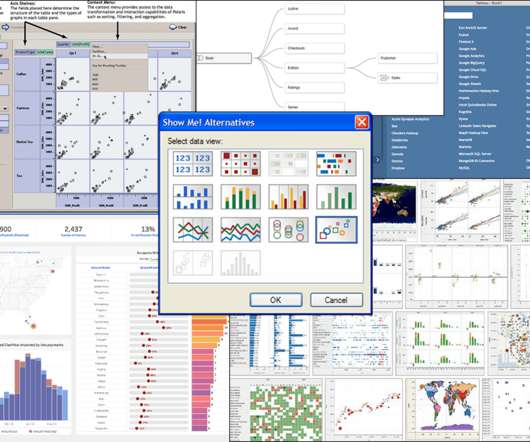
Working with multiple tables got a significant boost with cross data source actions in v5.0 (May Nov 2010), which allowed users to drag and drop multiple tables on one sheet. Formatting, in particular, is essential when sharing visual encodings of data with colleagues. Visual encoding is key to explaining ML models to humans.
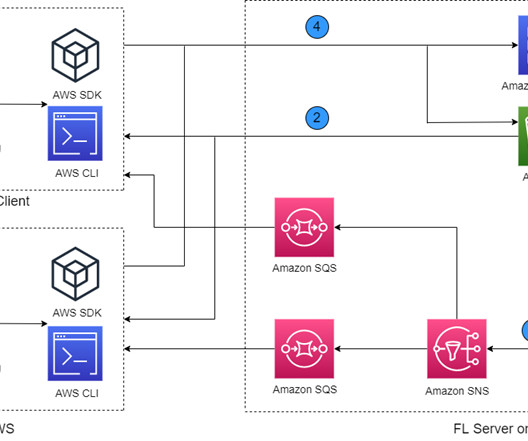
Machine learning (ML), especially deep learning, requires a large amount of data for improving model performance. Customers often need to train a model with data from different regions, organizations, or AWS accounts. Federated learning (FL) is a distributed ML approach that trains ML models on distributed datasets.
Stage 2: Machine learning models Hadoop could kind of do ML, thanks to third-party tools. But in its early form of a Hadoop-based ML library, Mahout still required data scientists to write in Java. If you wanted ML beyond what Mahout provided, you had to frame your problem in MapReduce terms. Context, for one.
Working with multiple tables got a significant boost with cross data source actions in v5.0 (May Nov 2010), which allowed users to drag and drop multiple tables on one sheet. Formatting, in particular, is essential when sharing visual encodings of data with colleagues. Visual encoding is key to explaining ML models to humans.
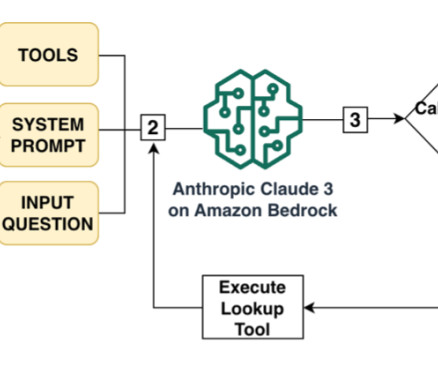
Large language models (LLMs) can help uncover insights from structured data such as a relational database management system (RDBMS) by generating complex SQL queries from natural language questions, making dataanalysis accessible to users of all skill levels and empowering organizations to make data-driven decisions faster than ever before.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content