Writing Robust Tests for Data & Machine Learning Pipelines
Eugene Yan
SEPTEMBER 3, 2022
Or why I should write fewer integration tests.

 writing testing-pipelines
writing testing-pipelines 
Eugene Yan
SEPTEMBER 3, 2022
Or why I should write fewer integration tests.

Data Science Dojo
APRIL 3, 2023
Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before. These tools provide a visual interface for building machine learning pipelines, making the process easier and more efficient for data scientists.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Towards AI
APRIL 7, 2024
It is the data we feed it with and a reliable pipeline. Overall, we need high confidence in our pipeline, model, and understanding of the problem and data. However, we cannot test many of the above points with unit tests as in traditional software development. A good trick is to write specific functions first.
Towards AI
MARCH 7, 2024
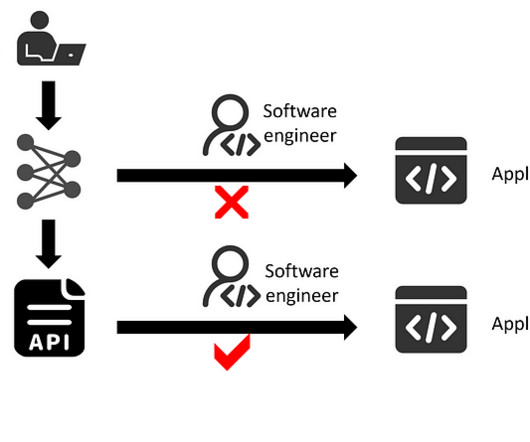
In the realm of IT application development, especially as a data scientist, it’s customary to encapsulate data processing and model inference pipelines into an API service. Integrate an AI model into an application. Source: by author. This API service essentially acts as a URL endpoint for invoking your AI model.

Dataconomy
FEBRUARY 26, 2024
This blog will provide an overview of performance testing fundamentals, identify prevalent performance bottlenecks, and offer strategies for proficiently executing these tests. What is performance testing? How can you perform performance testing for your mobile applications? Image credit ) 4.

DagsHub
SEPTEMBER 5, 2023
This is where CI/CD pipelines come into play, streamlining the process effectively. Let’s explore how the same tools that helped us in building a continuous training pipeline - Amazon SageMaker, Dagshub, and MLFlow - can help us in Deploying a model. They continuously learn and enhance their performance with additional data.

Towards AI
FEBRUARY 2, 2024
Gradio is simply a great choice for creating a customizable user interface for machine learning models to test your proof of concept. And we’re also importing the pipeline function from the Hugging Face Transformers library, which is very good for working with pre-trained transformer models in NLP.

Expert insights. Personalized for you.



























Let's personalize your content