


Transformer models: A guide to understanding different transformer architectures and their uses
Data Science Dojo
MARCH 23, 2024
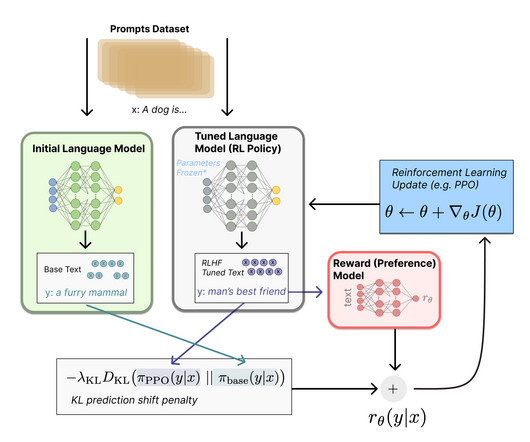
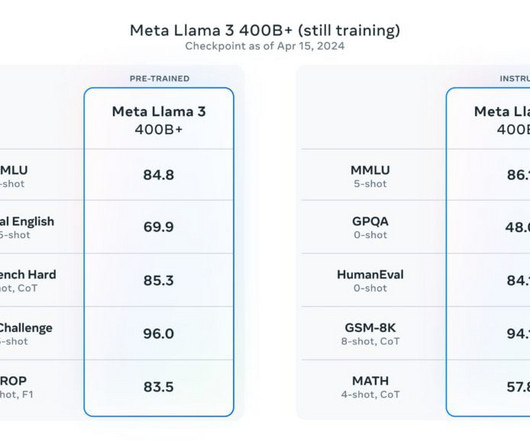
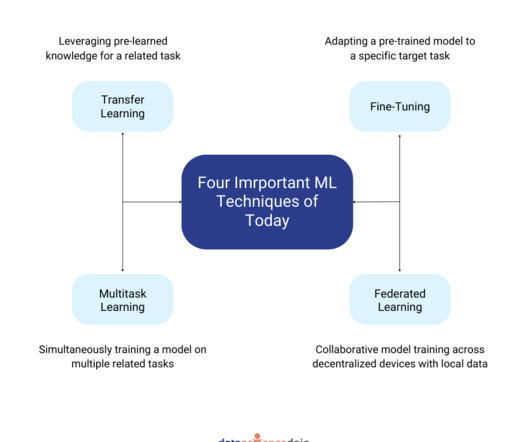
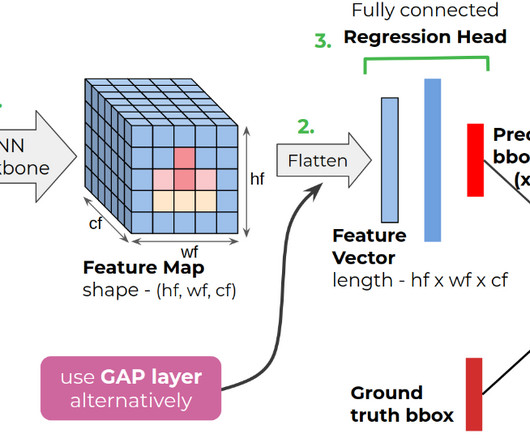
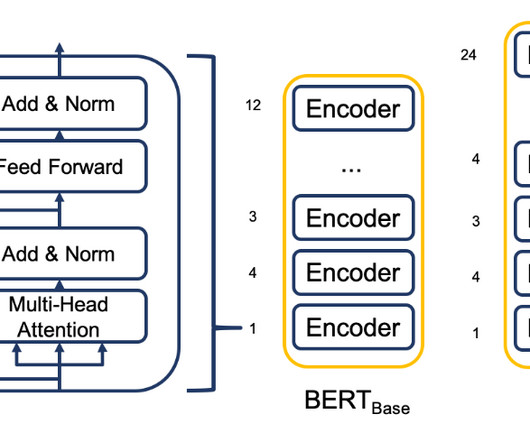
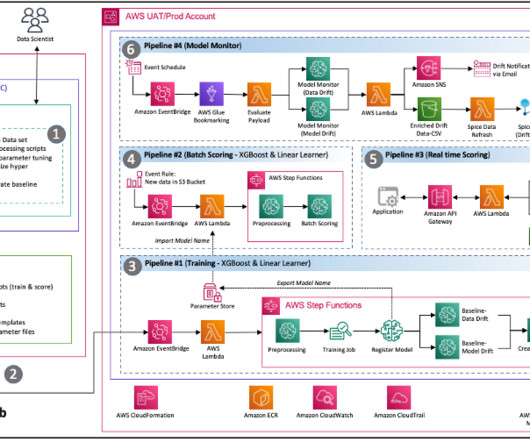
Their role is critical to ensure improved accuracy, faster training on data, and wider applicability. Categorization based on pre-training approaches While architecture is a basic component of consideration, the training techniques are equally crucial components for transformers. How to categorize transformer models?









































Let's personalize your content