


Infrastructure challenges and opportunities for AI startups
Dataconomy
MAY 30, 2023
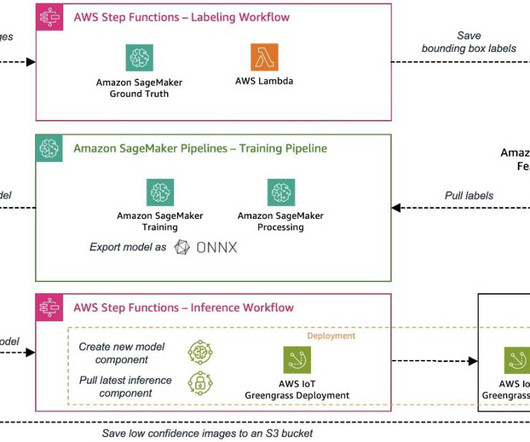
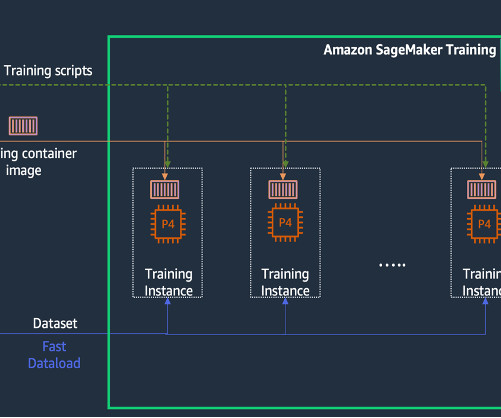
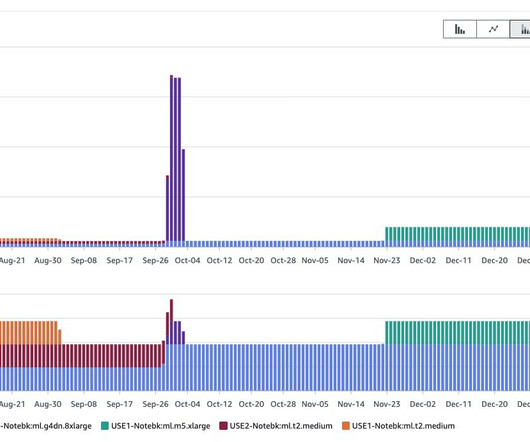
Similarly, the day-to-day operation of AI systems are also very compute-intensive, and tend to run on high-performance GPUs. meaningfully tagged) and ‘unlabelled’ (untagged) data, using the already-meaningful (labelled) data to train the AI and improve performance on processing the unlabelled data.






















Let's personalize your content