

Build an end-to-end MLOps pipeline for visual quality inspection at the edge – Part 3
AWS Machine Learning Blog
OCTOBER 2, 2023
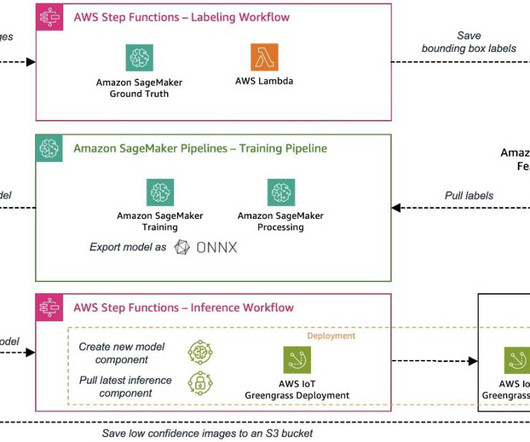
The sample use case used for this series is a visual quality inspection solution that can detect defects on metal tags, which you can deploy as part of a manufacturing process. Prepare Edge devices often come with limited compute and memory compared to a cloud environment where powerful CPUs and GPUs can run ML models easily.










Let's personalize your content