

Optimize AWS Inferentia utilization with FastAPI and PyTorch models on Amazon EC2 Inf1 & Inf2 instances
AWS Machine Learning Blog
JULY 24, 2023
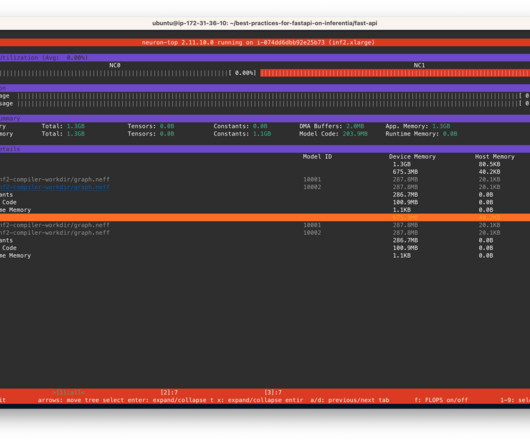
This allows us to handle more inference requests with fewer accelerators. The AWS Neuron SDK allows us to utilize each of the NeuronCores in parallel, which gives us more control in loading and inferring four or more models in parallel without sacrificing throughput.












Let's personalize your content