


Automate PDF pre-labeling for Amazon Comprehend
AWS Machine Learning Blog
DECEMBER 14, 2023
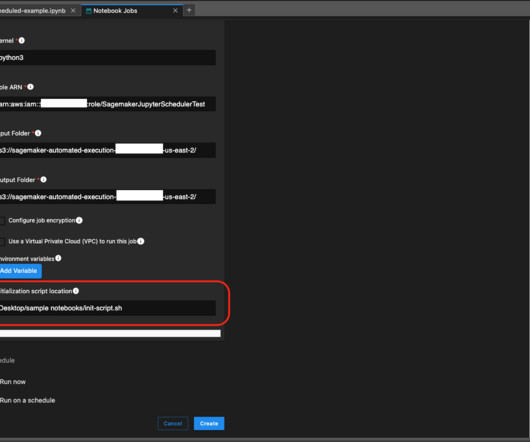
Amazon Comprehend is a natural-language processing (NLP) service that provides pre-trained and custom APIs to derive insights from textual data. To train a custom model, you first prepare training data by manually annotating entities in documents. For the demo, we use simulated bank statements like the following example.


































Let's personalize your content