

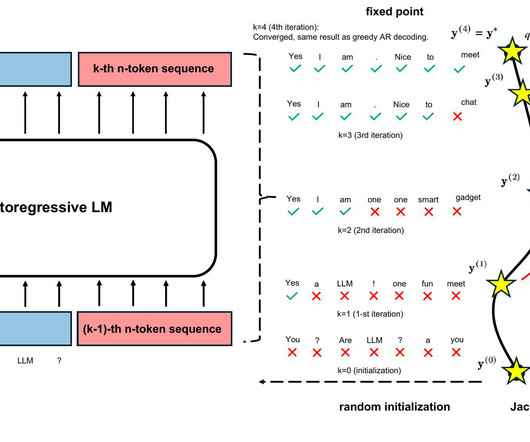
Consistency LLM: converting LLMs to parallel decoders accelerates inference 3.5x
Hacker News
MAY 8, 2024
In this blog, we show pretrained LLMs can be easily taught to operate as efficient parallel decoders. We introduce Consistency Large Language Models (CLLMs), a new family of parallel decoders capable of reducing inference latency by efficiently decoding an $n$-token sequence per inference step.





































Let's personalize your content