


Understanding Sora: An OpenAI model for video generation
Data Science Dojo
FEBRUARY 16, 2024
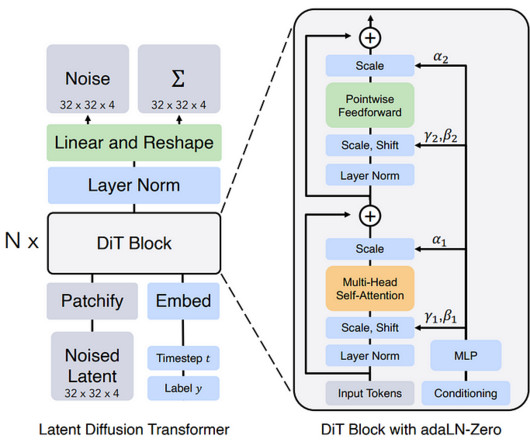
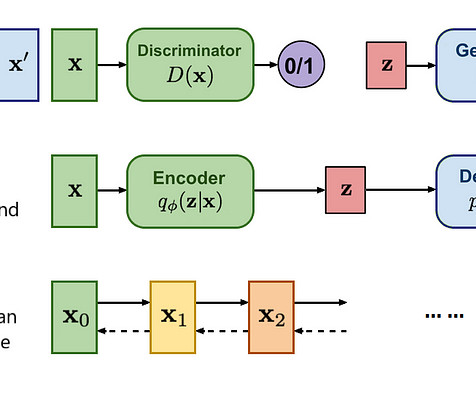
It is a new generative AI Text-to-Video model that can create minute-long videos from a textual prompt. Moreover, the model can express emotions in its visual characters. While it is a Text-to-Video generative model, OpenAI highlights that Sora can work with a diverse range of prompts, including existing images and videos.



























Let's personalize your content